JavaScript Debugger
JavaScript Editor
JavaScript Debugger
JavaScript Editor
When moving around the HTML document tree, we can either start at the top of the tree or start at an element of our choice. We’ll start with directly accessing an element, since the process is a bit easier to understand. Notice in the simple document shown here how the <<p>> tag is uniquely identified by the id attribute value of “p1”:
<<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">> <<html xmlns="http://www.w3.org/1999/xhtml">> <<head>> <<title>>DOM Test<</title>> <</head>> <<body>> <<p id="p1" align="center">>A paragraph of <<em>>text<</em>> is just an example<</p>> <</body>> <</html>>
Because the paragraph is uniquely identified, we can access this element using the getElementById() method of the Document—for example, by document.getElementById('p1'). This method returns a DOM Element object. We can examine the object returned to see what type of tag it represents.
var currentElement = document.getElementById('p1');
var msg = "nodeName: "+currentElement.nodeName+"\n";
msg += "nodeType: "+currentElement.nodeType+"\n";
msg += "nodeValue: "+currentElement.nodeValue+"\n";
alert(msg);
The result of inserting this script into the previous document is shown here:

Notice that the element held in nodeName is type P, corresponding to the XHTML paragraph element that defined it. The nodeType is 1, corresponding to an Element object, as shown in Table 10-1. However, notice that the nodeValue is null. You might have expected the value to be “A paragraph of text is just an example” or a similar string containing the <<em>> tag as well. In actuality, an element doesn’t have a value. While elements define the structure of the tree, it is text nodes that hold most of the interesting values. Text nodes are attached as children of other nodes, so to access what is enclosed by the <<p>> tags, we would have to examine the children of the node. We’ll see how to do that in a moment, but for now study the various Node properties available for an arbitrary tag summarized in Table 10-2.
|
DOM Node Properties |
Description |
|---|---|
|
>nodeName |
Contains the name of the node |
|
>nodeValue |
Contains the value within the node; generally only applicable to text nodes |
|
>nodeType |
Holds a number corresponding to the type of node, as given in Table 10-1 |
|
>parentNode |
A reference to the parent node of the current object, if one exists |
|
>childNodes |
Access to list of child nodes |
|
>firstChild |
Reference to the first child node of the element, if one exists |
|
>lastChild |
Points to the last child node of the element, if one exists |
|
>previousSibling |
Reference to the previous sibling of the node; for example, if its parent node has multiple children |
|
>nextSibling |
Reference to the next sibling of the node; for example, if its parent node has multiple children |
|
>attributes |
The list of the attributes for the element |
|
>ownerDocument |
Points to the HTML Document object in which the element is contained |
| Note |
DOM HTMLElement objects also have a property tagName that is effectively the same as the Node object property nodeName. |
Given the new properties, we can “walk” the given example quite easily. The following is a simple demonstration of walking a known tree structure.
<<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">>
<<html xmlns="http://www.w3.org/1999/xhtml">>
<<head>>
<<title>>DOM Walk Test<</title>>
<<meta http-equiv="content-type" content="text/html; charset=utf-8" />>
<</head>>
<<body>>
<<p id="p1" align="center">>A paragraph of <<em>>text<</em>> is just an example
<</p>>
<<script type="text/javascript">>
<<!--
function nodeStatus(node)
{
var temp = "";
temp += "nodeName: "+node.nodeName+"\n";
temp += "nodeType: "+node.nodeType+"\n";
temp += "nodeValue: "+node.nodeValue+"\n\n";
return temp;
}
var currentElement = document.getElementById('p1'); // start at P
var msg = nodeStatus(currentElement);
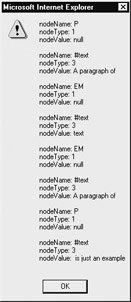
currentElement = currentElement.firstChild; // text node 1
msg += nodeStatus(currentElement);
currentElement = currentElement.nextSibling; // em Element
msg += nodeStatus(currentElement);
currentElement = currentElement.firstChild; // text node 2
msg += nodeStatus(currentElement);
currentElement = currentElement.parentNode; // back to em Element
msg += nodeStatus(currentElement);
currentElement = currentElement.previousSibling; //back to text node 1
msg += nodeStatus(currentElement);
currentElement = currentElement.parentNode; // to p Element
msg += nodeStatus(currentElement);
currentElement = currentElement.lastChild; // to text node 3
msg += nodeStatus(currentElement);
alert(msg);
//-->>
<</script>>
<</body>>
<</html>>
The output of the example is shown in Figure 10-2.
The problem with the previous example is that we knew the sibling and child relationships ahead of time by inspecting the markup in the example. How do you navigate a structure that you aren’t sure of? We can avoid looking at nonexistent nodes by first querying the hasChildNodes() method for the current node before traversing any of its children. This method returns a Boolean value indicating whether or not there are children for the current node.
if (current.hasChildNodes()) current = current.firstChild;
When traversing to a sibling or parent, we can simply use an if statement to query the property in question, for example,
if (current.parentNode) current = current.parentNode;
The following example demonstrates how to walk an arbitrary document. We provide a basic document to traverse, but you can substitute other documents as long as they are well formed:
<<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">>
<<html xmlns="http://www.w3.org/1999/xhtml">>
<<head>>
<<title>>DOM Test<</title>>
<<meta http-equiv="content-type" content="text/html; charset=utf-8" />>
<</head>>
<<body>>
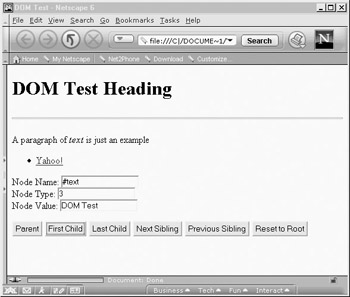
<<h1>>DOM Test Heading<</h1>>
<<hr />>
<<!-- Just a comment -->>
<<p>>A paragraph of <<em>>text<</em>> is just an example<</p>>
<<ul>>
<<li>><<a href="/">>Yahoo!<</a>><</li>>
<</ul>>
<<form name="testform" id="testform" action="#" method="get">>
Node Name: <<input type="text" id="nodeName" name="nodeName" />><<br />>
Node Type: <<input type="text" id="nodeType" name="nodeType" />><<br />>
Node Value: <<input type= "text" id="nodeValue" name="nodeValue" />><<br />>
<</form>>
<<script type="text/javascript">>
<<!--
function update(currentElement)
{
window.document.testform.nodeName.value = currentElement.nodeName;
window.document.testform.nodeType.value = currentElement.nodeType;
window.document.testform.nodeValue.value = currentElement.nodeValue;
}
function nodeMove(currentElement, direction)
{
switch (direction)
{
case "previousSibling": if (currentElement.previousSibling)
currentElement = currentElement.previousSibling;
else
alert("No previous sibling");
break;
case "nextSibling": if (currentElement.nextSibling)
currentElement = currentElement.nextSibling;
else
alert("No next sibling");
break;
case "parent": if (currentElement.parentNode)
currentElement = currentElement.parentNode;
else
alert("No parent");
break;
case "firstChild": if (currentElement.hasChildNodes())
currentElement = currentElement.firstChild;
else
alert("No Children");
break;
case "lastChild": if (currentElement.hasChildNodes())
currentElement = currentElement.lastChild;
else
alert("No Children");
break;
default: alert("Bad direction call");
}
update(currentElement);
return currentElement;
}
var currentElement = document.documentElement;
update(currentElement);
//-->>
<</script>>
<<form action="#" method="get">>
<<input type="button" value="Parent"
onclick="currentElement=nodeMove(currentElement,'parent');" />>
<<input type="button" value="First Child"
onclick="currentElement=nodeMove(currentElement,'firstChild');" />>
<<input type="button" value="Last Child"
onclick="currentElement=nodeMove(currentElement,'lastChild');" />>
<<input type="button" value="Next Sibling"
onclick="currentElement=nodeMove(currentElement,'nextSibling');" />>
<<input type="button" value="Previous Sibling"
onclick="currentElement=nodeMove(currentElement,'previousSibling');" />>
<<input type="button" value="Reset to Root"
onclick="currentElement=document.documentElement; update(currentElement);" />>
<</form>>
<</body>>
<</html>>
The rendering of this example is shown in Figure 10-3.
Something to be aware of when trying examples like this is that different browsers create the document tree in slightly different ways. Opera, Netscape 6/7, and other Mozilla-based browsers will appear to have more nodes to traverse than Internet Explorer because white space is represented as a text node in the tree, as shown here.
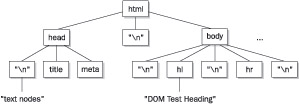
This can cause some headaches if you are using this kind of tree traversal to examine a document and want it to behave identically between browsers. It is possible to normalize the Mozilla-style DOM tree, but in most cases it won’t be needed. Since most programmers tend to use getElementById() to retrieve specific nodes, there is usually little need for full-blown tree traversal.
In addition to document.getElementById(), there are other methods and properties useful for accessing a specific node in a document. Particularly valuable are the collections provided by the DOM Level 0 to support traditional JavaScript practices.
Given that many older HTML documents favor the use of the name (rather than id) attribute with HTML elements like <<form>>, <<input>>, <<select>>, <<textarea>>, <<img>>, <<a>>, <<area>>, and <<frame>>, it is often useful to retrieve these elements by name. To do so, use the getElementsByName() method of the Document. This method accepts a string indicating the name of the element to retrieve; for example:
tagList = document.getElementsByName('myTag');
Notice that this method can potentially return a list of nodes rather than a single node. This is because the uniqueness of the value in a name attribute is not strictly enforced under traditional HTML, so, for example, an <<img>> tag and a <<form>> element might share the same name. Also you may have <<input>> tags in different forms in a document with the same name. Like any other JavaScript collection, you can use the length property to determine the length of the object list and traverse the list itself using the item() method or normal array syntax; for example:
tagList = document.getElementsByName('myTag');
for (var i = 0; i << tagList.length; i++)
alert(tagList.item(i).nodeName);
Equivalently, using slightly different syntax:
tagList = document.getElementsByName('myTag');
for (var i = 0; i << tagList.length; i++)
alert(tagList[i].nodeName);
Given that the getElementsByName() method returns a list of HTML elements with the same name attribute value, you may wonder why getElementById() does not work this way. Recall that each element’s id is supposed to be a unique value. In short, permitting getElementById() to behave as getElementsByName() would only encourage the loose HTML style that has caused enough problems already. If you do have an invalid document because multiple elements have the same id, the getElementById() method may not work or may return only the first or last item.
Sometimes it will not be possible to jump to a particular point in the document tree, and there are times when you will want to start at the top of the tree and work down through the hierarchy. There are two Document properties that present useful starting points for tree walks. The property document.documentElement points to the root element in the document tree. For HTML documents, this would be the <<html>> tag. The second possible starting point is document.body, which references the node in the tree corresponding to the <<body>> tag. You might also have some interest in looking at the DOCTYPE definition for the file. This is referenced by document.doctype, but this node is not modifiable. It may not appear to have much use, but the document.doctype value does allow you to look to see what type of document you are working with.
For backward compatibility, the DOM supports some object collections popular under early browser versions. These collections form DOM Level 0, which is roughly equivalent to what Netscape 3’s object model supported. The collections defined by DOM Level 0 are shown in Table 10-3 and can be referenced numerically (document.forms[0]), associatively (document.forms['myform']), or directly (document.myform). You can also use the item() method to access an array index (document.forms.item(0)), although this is uncommon and not well supported in older JavaScript; it should probably be avoided.
|
Collection |
Description |
|---|---|
|
>document.anchors[] |
A collection of all the anchors in a page specified by <a name=""> </a> |
|
>document.applets[] |
A collection of all the Java applets in a page |
|
>document.forms[] |
A collection of all the <form> tags in a page |
|
>document.images[] |
A collection of all images in the page defined by <img> tags |
|
>document.links[] |
A collection of all links in the page defined by <a href=""> </a> |
You may notice that Table 10-3 does not include proprietary collections like embeds[], all[], layers[], and so on. The reason is that the main goal of the DOM is to eliminate the reliance of scripts upon proprietary DHTML features. However, as we’ll see throughout this book, old habits die hard on the Web.
The final way to access elements under DOM Level 1 is using the getElementsByTagName() method of the Document. This method accepts a string indicating the instances of the tag that should be retrieved—for example, getElementsByTagName('img'). The method returns a list of all the tags in the document that are of the type passed as the parameter. While you may find that
allParagraphs = document.getElementsByTagName('p');
works correctly, it is actually more correct to invoke this function as a method of an existing element. For example, to find all the paragraphs within the <<body>> tag, you would use
allParagraphs = document.body.getElementsByTagName('p');
You can even find elements within other elements. For example, you might want to find a particular paragraph and then find the <<em>> tags within:
para1 = document.getElementById('p1');
emElements = para1.getElementsByTagName('em');
We’ll see some examples later on that use these methods to manipulate numerous elements at once. For now, let’s turn our attention to manipulating the nodes we retrieve from a document.
JavaScript Debugger
JavaScript Editor