 JavaScript Debugger
JavaScript Editor
JavaScript Debugger
JavaScript Editor
The most important thing to think about with the DOM Level 1 and Level 2 is that you are manipulating a document tree. For example, consider the simple (X)HTML document presented here:
<<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">> <<html xmlns="http://www.w3.org/1999/xhtml">> <<head>> <<title>>DOM Test<</title>> <</head>> <<body>> <<h1>>DOM Test Heading<</h1>> <<hr />> <<!-- Just a comment -->> <<p>>A paragraph of <<em>>text<</em>> is just an example<</p>> <<ul>> <<li>><<a href="/">>Yahoo!<</a>><</li>> <</ul>> <</body>> <</html>>
When a browser reads this particular (X)HTML document, it represents the document in the form of the tree, as shown here:
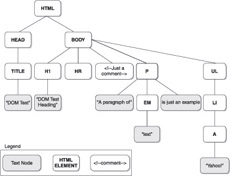
Notice that the tree structure follows the structured nature of the (X)HTML. The <<html>> element contains the <<head>> and <<body>>. The <<head>> contains the <<title>>, and the <<body>> contains the various block elements like paragraphs (<<p>>), headings (<<h1>>), and lists (<<ul>>). Each element may in turn contain more elements or textual fragments. As you can see, each of the items (or, more appropriately, nodes) in the tree correspond to the various types of objects allowed in an HTML or XML document. There are 12 types of nodes defined by the DOM; however, many of these are useful only within XML documents. We’ll discuss JavaScript and XML in Chapter 20, so for now the node types we are concerned with are primarily related to HTML and are presented in Table 10-1.
|
Node Type Number |
Type |
Description |
Example |
|---|---|---|---|
|
1 |
Element |
An (X)HTML or XML element |
<p>…</p> |
|
2 |
Attribute |
An attribute for an HTML or XML element |
align="center" |
|
3 |
Text |
A fragment of text that would be enclosed by an HTML or XML element |
This is a text fragment! |
|
8 |
Comment |
An HTML comment |
<!-- This is a comment --> |
|
9 |
Document |
The root document object, namely the top element in the parse tree |
<html> |
|
10 |
DocumentType |
A document type definition |
<!DOCTYPE HTML PUBLIC "-
|
Before moving on, we need to introduce some familiar terminology related to node relationships in a document tree. A subtree is part of a document tree rooted at a particular node. The subtree corresponding to the following HTML fragment from the last example,
<<p>>A paragraph of <<em>>text<</em>> is just an example<</p>>
is shown here:

The following relationships are established in this tree:
The p element has three children: a text node, the em element, and another text node.
The text node “A paragraph of” is the first child of the p element.
The last child of the p element is the text node “is just an example.”
The parent of the em element is the p element.
The text node containing “text” is the child of the em element, but is not a direct descendent of the p element.
The nomenclature used here should remind you of a family tree. Fortunately, we don’t talk about second cousins, relatives twice removed, or anything like that! The diagram presented here summarizes all the basic relationships that you should understand:

Make sure that you understand that nodes a, b, and c would all consider node 1 to be their parent, while node d would look at b as its parent.
Now that we have the basics down, let’s take a look at how we can move around the document tree and examine various (X)HTML elements using JavaScript and the DOM.
JavaScript Debugger
JavaScript Editor