Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Algorithmic AnalysisAlgorithm design and algorithmic analysis are usually senior-level computer science material. However, we can at least touch upon some common-sense techniques and ideas to help you when you start writing more complex algorithms. First, a good algorithm is better than all the assembly language or optimization in the world. For example, you saw that just changing the order of your data can reduce the amount of time it takes to search for a data element by orders of magnitude. So the moral of the story is to select a solid algorithm that fits the problem and the data, but at the same time to pick a data structure that can be accessed and manipulated with a good algorithm. For example, if you always use linear arrays, you're never going to get better than linear search time (unless you use secondary data structures). But if you use sorted arrays, you can get logarithmic search time. The first step in writing good algorithms is having some clue about how to analyze them. The art of analyzing algorithms is called asymptotic analysis and is usually calculus-based. I'm not go to go into it too much, but I'll skim some of the concepts. The basic idea of analyzing an algorithm is computing how many times the main loop is executed for n elements, whatever n happens to be. This is the most important idea. Of course, how long it takes for each execution, plus the overhead of setup, can also be important once you have a good algorithm, but the place to start is the general counting of how many times the loop executes. Let's take a look at two examples:
for (int index=0; index<n; index++)
{
// do work, 50 cycles
} // end for index
In this case, the loop is going to execute for n iterations, so the execution time is of the order n, or O(n). This is called Big O notation and is an upper bound, or very rough upper estimate, of execution time. Anyway, if you want to be more precise, you know that the inner computation takes 50 cycles, so the total execution time is n*50 cycles Right? Wrong! If you're going to count cycles, you'd better count the cycles that it takes for the loop itself. This consists of an initialization of a variable, a comparison, and increment, and a jump each iteration. Adding these gives you something like this: Cyclesinitialization+(50+Cyclesinc+Cyclescomp+Cyclesjump)*n This is a much better estimate. Of course, Cyclesinc, Cyclescomp, and Cyclesjump are the number of cycles for the increment, comparison, and jump, respectively, and are each around 1-2 on a Pentium-class processor. Therefore, in this case the loop itself contributes just as much to the overall time of the inner loop as the work the loop does! This is a key point. For example, many game programmers write a pixel-plotting function as a function instead of a macro or inline code. Because a pixel-plotting function is so simple, the call to the function takes more time than the pixel plotting! So make sure that you do enough work in your loop to warrant one, and that the work "drowns out" the loop mechanics themselves. Now let's see another example that has a much worse running time than n:
// outer loop
for (i=0; i<n; i++)
{
// inner loop
for (j=1; j<2*n; j++)
{
// do work
} // end for j
} // end for i
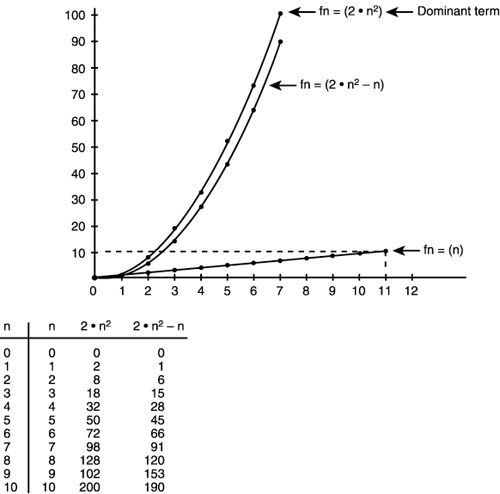
This time, I'm assuming the work part takes much more time than the actual code that supports the loop mechanics, so I'm not interested in it. What I am interested in is how many times this loop executes. The outer loop executes n times and the inner loop executes 2*n-1 times, so the total amount of time the inner code will be executed is n*(2*n-1) = 2*n2-n Let's look at this for a moment, because there are two terms. The 2*n2 term is the dominate term and will drown out the n term as n gets large. Take a look at Figure 11.5 to see this. Figure 11.5. Rates of growth for the term of 2*n2-n.
For a small n, say 2, the n term is relevant: 2*(2)2 - 2 = 6 In this case, the n term contributes to subtracting 25 percent of the total time away, but take a look when n gets large. For example, n = 1000: 2*(1000)2 - 1000 = 1999000 In this case, the n term contributes a decrease of only .05 percent; hardly important. You can see that the dominant term is indeed the 2*n2 term, or more simply the n2 itself. Hence, this algorithm is O(n2). This is very bad. Algorithms that run in n2 time will just kill you, so if you come up with an algorithm like this, try, try again! That's it for asymptotic analysis. The bottom line is that you must be able to roughly estimate the run-time of your loops, which will help you pick out the algorithms and recode areas that need work. |
|
|
Ajax Editor
JavaScript Editor