Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Data StructuresProbably one of the most frequent questions I'm asked is, "What kind of data structures should be used in a game?" The answer is: the fastest and most efficient data structures possible. However, in most cases you won't need the most advanced, complex data structures that computer science has to offer. Rather, you should try to keep things simple. And speed is more important than memory these days, so you should sacrifice memory before you sacrifice speed! With that in mind, I want to take a look at a few of the most common data structures used in games and give you some insight into when and how to use them. Static Structures and ArraysThe most basic of all data structures is, of course, a single occurrence of a data item such as a single structure or class. For example:
typedef struct PLAYER_TYP // tag for forward references
{
int state; // state of player
int x,y; // position of player
// ...
} PLAYER, *PLAYER_PTR;
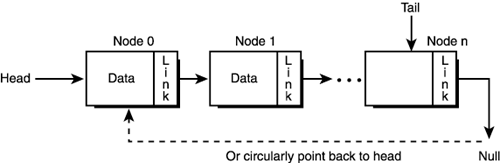
C++ In C++, you no longer need to use typedef on structure definitions to create a type; a type is automatically created for you when you use the keyword struct. In addition, C++ structs can have methods and even public and private sections. PLAYER player_1, player_2; // create a couple players In this case, a single data structure along with two statically defined records does the job. On the other hand, if there were three or more players, it would probably be a good idea to use an array like this: PLAYER players[MAX_PLAYERS]; // the players of the game Here you can process all the players with a simple loop. Okay, great, but what if you don't know how many players or records there are going to be until the game runs? When this situation arises, I figure out the maximum number of elements that the array would have to hold. If it's reasonably small number, like 256 or less, and each element is also reasonably small (less than 256 bytes), I will usually statically allocate it and use a counter to count how many of the elements are active at any time. You may think that this is a waste of memory, and it is, but a preallocated array of a fixed size is easier and faster to traverse than a linked list or more dynamic structure. The point is, if you know the number of elements ahead of time and there aren't that many of them, go ahead and preallocate an array statically by making a call to malloc() or new() during startup. WARNING Don't get carried away with static arrays. For example, if you have a structure that is 4KB and there may be from 1 to 256 static arrays, you definitely need a better strategy than allocating 1MB in case there may be 256 of them at some point. In this case, it might be better to use a linked list or to dynamically reallocate the array and increase its size on demand. Linked ListsArrays are fine for simple data structures that can be precounted or estimated at compilation or startup, but data structures that can grow or shrink during run-time should use some form of linked lists. Figure 11.1 depicts a standard abstract linked list. A linked list consists of a number of nodes, each node containing information and a link to the next node in the list. Figure 11.1. A linked list.
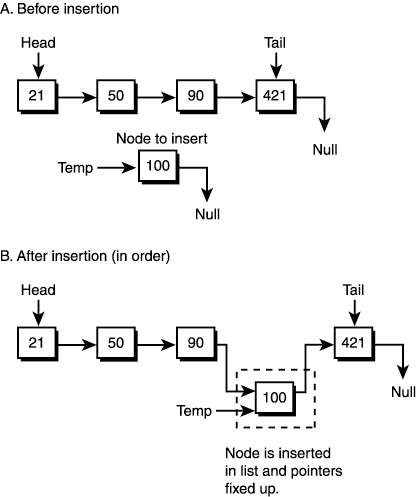
Linked lists are cool because you can insert a node anywhere in the list, and you can delete a node from anywhere in the list. Take a look at Figure 11.2 to see this graphically. The capability to insert and delete nodes (and hence, information) during run-time makes linked lists very attractive as data structures for games. Figure 11.2. Inserting into a linked list.
The only bad thing about linked lists is that you must traverse them node by node to find what you're looking for (unless other secondary data structures are created to help with the searching). For example, say that you want the 15th element in an array. You would access it like this: players[15] But with linked lists, you need a traversal algorithm to traverse the list to find the 15th element. This means that the searching of linked lists can take a number of iterations equal to the length of the list (in the worst case). That is, O(n)—read "Big O of n." This means that there are on the order of n operations for n elements. Of course, there are optimizations and secondary data structures that you can employ to maintain a sorted indexed list that allows access almost as fast as the simple array. Creating a Linked ListLet's take a look at how you would create a simple linked list, add a node, delete a node, and search for an item with a given key. Here's the basic node:
typedef struct NODE_TYP
{
int id; // id number of this object
int age; // age of person
char name[32]; // name of person
NODE_TYP *next; // this is the link to the next node
// more fields go here
} NODE, *NODE_PTR;
To start the list off, you need a head pointer and a tail pointer that point to the head and tail of the list, respectively. However, the list is empty, so the pointers start off pointing to NULL:
NODE_PTR head = NULL,
tail = NULL;
NOTE Some programmers like to start off a linked list with a dummy node that's always empty. This is mostly a choice of taste. However, this changes some of the initial conditions of the creation, insertion, and deletion algorithms, so you might want to try it. Traversing a Linked ListIronically, traversing a linked list is the easiest of all operations:
void Traverse_List(NODE_PTR head)
{
// this function traverses the linked list and prints out
// each node
// test if head is null
if (head==NULL)
{
printf("\nLinked List is empty!");
return;
} // end if
// traverse while nodes
while (head!=NULL)
{
// visit the node, print it out, or whatever...
printf("\nNode Data: id=%d", head->id);
printf("\nage=%d,head->age);
printf("\nname=%s\n",head->name);
// advance to next node (simple!)
head = head->next;
} // end while
print("\n");
} // end Traverse_List
Pretty cool, huh? Next, let's take a look at how you would add a node. Adding a NodeThe first step in adding a node is creating it. There are two ways to approach this: You could send the new data elements to the insertion function and let it build up a new node, or you could build up a new node and then pass it to the insertion function. Either way is basically the same. Furthermore, there are a number of ways to insert a node into a linked list. The brute-force method is to add it to the front or the end. This fine if you don't care about the order, but if you want the list to remain sorted, you should use a more intelligent insertion algorithm that maintains either ascending or descending order—an insertion sort of sorts. This will make searching much faster. For simplicity's sake, I'm going to take the easy way out and insert at the end of the list, but inserting with sorting is not that much more complex. You first need to scan the list, find where the new element should be inserted, and insert it. The only problem is keeping track of the pointers and not losing anything. Anyway, here's the code to insert a new node at the end of the list (a bit harder than inserting at the front of the list). Notice the special cases for empty lists and lists with a single element:
// access the global head and tail to make code easier
// in real life, you might want to use ** pointers and
// modify head and tail in the function ???
NODE_PTR Insert_Node(int id, int age, char *name)
{
// this function inserts a node at the end of the list
NODE_PTR new_node = NULL;
// step 1: create the new node
new_node = (NODE_PTR)malloc(sizeof(NODE)); // in C++ use new operator
// fill in fields
new_node->id = id;
new_node->age = age;
strcpy(new_node->name,name); // memory must be copied!
new_node->next = NULL; // good practice
// step 2: what is the current state of the linked list?
if (head==NULL) // case 1
{
// empty list, simplest case
head = tail = new_node;
// return new node
return(new_node);
} // end if
else
if ((head != NULL) && (head==tail)) // case 2
{
// there is exactly one element, just a little
// finesse...
head->next = new_node;
tail = new_node;
// return new node
return(new_node);
} // end if
else // case 3
{
// there are 2 or more elements in list
// simply move to end of the list and add
// the new node
tail->next = new_node;
tail = new_node;
// return the new node
return(new_node);
} // end else
} // end Insert_Node
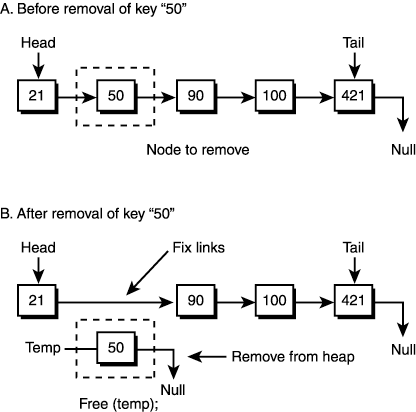
As you can see, the code is rather simple. But it's easy to mess up because you're dealing with pointers, so be careful! Also, the astute programmer will very quickly realize that with a little thought, cases two and three can be combined, but the code here is easier to follow. Now let's remove a node. Deleting a NodeDeleting a node is more complex than inserting a node because pointers and memory have to be shuffled. The problem with deletion is that, in most cases, you want to delete a specific node. The node might be at the head, tail, or middle, so you must write a very general algorithm that takes all these cases into consideration. If you're careful, deletion isn't a problem. If you don't take all the cases into consideration and test them, though, you'll be sorry! In general, the algorithm must search the linked list for the key in question, remove the node from the list, and release its memory. In addition, the algorithm has to fix up the pointers that pointed to the node and that the node pointed to. Take a look at Figure 11.3 to see this. Figure 11.3. Removing a node from a linked list.
In any event, here's the code that implements the deletion based on removing the node with key ID:
// again this function will modify the globals
// head and tail (possibly)
int Delete_Node(int id) // node to delete
{
// this function deletes a node from
// the linked list given its id
NODE_PTR curr_ptr = head, // used to search the list
prev_ptr = head; // previous record
// test if there is a linked list to delete from
if (!head)
return(-1);
// traverse the list and find node to delete
while(curr_ptr->id != id && curr_ptr)
{
// save this position
prev_ptr = curr_ptr;
curr_ptr = curr_ptr->next;
} // end while
// at this point we have found the node
// or the end of the list
if (curr_ptr == NULL)
return(-1); // couldn't find record
// record was found, so delete it, but be careful,
// need to test cases
// case 1: one element
if (head==tail)
{
// delete node
free(head);
// fix up pointers
head=tail=NULL;
// return id of deleted node
return(id);
} // end if
else // case 2: front of list
if (curr_ptr == head)
{
// move head to next node
head=head->next;
// delete the node
free(curr_ptr);
// return id of deleted node
return(id);
} // end if
else // case 3: end of list
if (curr_ptr == tail)
{
// fix up previous pointer to point to null
prev_ptr->next = NULL;
// delete the last node
free(curr_ptr);
// point tail to previous node
tail = prev_ptr;
// return id of deleted node
return(id);
} // end if
else // case 4: node is in middle of list
{
// connect the previous node to the next node
prev_ptr->next = curr_ptr->next;
// now delete the current node
free(curr_ptr);
// return id of deleted node
return(id);
} // end else
} // end Delete_Node
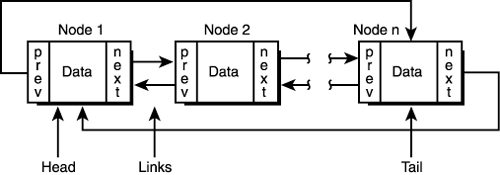
Note that there are a lot of special cases in the code. Each case is simple, but you have to think of everything—which I hope I did! Finally, you may have noticed the dramarama involved with deleting nodes from the interior of the list. This is due to the fact that once a node is traversed, you can't get back to it. Hence, I had to keep track of a previous NODE_PTR to keep track of the last node. This problem, along with others, can be solved by using a doubly linked list, as shown in Figure 11.4. Figure 11.4. A doubly linked list.
The cool things about doubly linked lists are that you can traverse them in both directions from any point and insertions and deletions are much easier. And the only change to the data structure is another link field, as shown here:
typedef struct NODE_TYP
{
int id; // id number of this object
int age; // age of person
char name[32]; // name of person
// more fields go here
NODE_TYP *next; // link to the next node
NODE_TYP *prev; // link to previous node
} NODE, *NODE_PTR;
With a doubly linked list, you always move forward or backward from any node, so the tracking code is simplified for insertions and deletions. For an example of implementing a simple linked list, take a look at the console application DEMO11_1.CPP|EXE. It allows you to add, delete, and traverse a linked list. NOTE DEMO11_1.CPP is a console application, rather than the standard Windows .EXE application that you've been working with, so make sure to set the compiler for Console Application before trying to compile it. And obviously, there is no DirectX, so you don't need any of the DirectX .LIB files. |
|
|
Ajax Editor
JavaScript Editor