Source code editor
Website development
ÿ£¢
Source code editor
Website development
ÿ£¢|
|
Understanding TCP and UDPAs this hour has already mentioned, TCP is a connection-oriented protocol that provides extensive error control and flow control. UDP is a connectionless protocol with much less sophisticated error control. You might say that TCP is built for reliability, and UDP is built for speed. Applications that must support interactive sessions, such as Telnet and FTP, tend to use TCP. Applications that do their own error checking or that don't need much error checking tend to use UDP. A software developer designing a network application can choose whether to use TCP or UDP as a transport protocol. UDP's simpler control mechanisms should not necessarily be considered limiting. First of all, less quality assurance does not necessarily mean lower quality. The extra checks and controls provided by TCP are entirely unnecessary for many applications. In cases where error control and flow control are necessary, some developers prefer to provide those control features within the application itself, where they can be customized for the specific need, and to use the leaner UDP transport for network access. UDP-based services such as TCP/IP's Remote Procedure Call (RPC) can support advanced and sophisticated applications, but those applications must take responsibility for more error control and flow control tasks than if they reached the stack through TCP. TCP: The Connection-Oriented Transport ProtocolThis hour has already described TCP's connection-oriented approach to communication. TCP has a few other important features that warrant mentioning:
A close look at TCP reveals a complex system of announcements and acknowledgments supporting TCP's connection-oriented structure. The following sections take a closer look at TCP data format, TCP data transmission, and TCP connections. The technical nature of this discussion should reveal how complex TCP really is. This discussion of TCP also underscores the fact that a protocol is more than just a data format: It is a whole system of interacting processes and procedures designed to accomplish a set of well-defined objectives. As you learned in Hour 2, "How TCP/IP Works," layered protocol systems such as TCP/IP operate through an information exchange between a given layer on the sending machine and the corresponding layer on the receiving machine. In other words, the Network Access layer on the sending machine communicates with the Network Access layer on the receiving machine, the Internet layer on the sending machine communicates with the Internet layer on the receiving machine, and so forth. The TCP software communicates with the TCP software on the machine to which it has established (or wants to establish) a connection. In any discussion of TCP, if you hear the phrase "Computer A establishes a connection with Computer B," what that really means is that the TCP software of Computer A has established a connection with the TCP software of Computer B, both of which are acting on behalf of a local application. The subtle distinction yields an interesting observation concerning the concept of end-node verification that was introduced in Hour 1, "What Is TCP/IP?" Recall that end nodes are responsible for verifying communications on a TCP/IP network. (The end nodes are the nodes that are actually attempting to communicateas opposed to the intermediate nodes, which forward the message.) In a typical internetworking situation (see Figure 6.7), the data is passed from the source subnet to the destination subnet by routers. These routers typically operate at the Internet layerthe layer below the Transport layer. (You'll learn more about routers in Hour 10, "Routing.") The important point is that the routers are not concerned with the information at the Transport level. They simply pass on the Transport layer data as cargo for the IP datagram, which attaches its own header information and sends the datagram on its way. The control and verification information encoded in a TCP segment is intended solely for the TCP software of the destination machine. This speeds up routing over TCP/IP internetworks (because routers do not have to participate actively in TCP's elaborate quality assurance ritual) and at the same time enables TCP to fulfill the Department of Defense's objective of providing a network with end-node verification. Figure 6.7. Routers forward but do not process Transport layer data.
TCP Data FormatThe TCP header format is shown in Figure 6.8. The complexity of this structure reveals the complexity of TCP and the many facets of its functionality. Figure 6.8. TCP segment data format.
The fields are as follows. You'll have a better idea of how these data fields are used after reading the next section, which discusses TCP connections:
TCP needs all these data fields to successfully manage, acknowledge, and verify network transmissions. The next section shows how the TCP software uses some of these fields to manage the tasks of sending and receiving data. TCP ConnectionsEverything in TCP happens in the context of a connection. TCP sends and receives data through a connection, which must be requested, opened, and closed according to the rules of TCP. As you learned earlier in this hour, one of the reasons for TCP is to provide an interface so that applications can have access to the network. That interface is provided through the TCP ports and, in order to provide a connection through the ports, the TCP interface to the application must be open. TCP supports two open states:
In a typical situation, an application wanting to receive connections, such as an FTP server, places itself and its TCP port status in a passive open state. On the client computer, the FTP client's TCP state is most likely closed until a user initiates a connection from the FTP client to the FTP server, at which time the state for the client becomes active open. The TCP software of the computer that switches to active open (that is, the client) then initiates the exchange of messages that leads to a connection. That exchange of information, the so-called three-way handshake, will be discussed later in this hour. A client is a computer requesting or receiving services from another computer on the network. A server is a computer offering services to other computers on the network. TCP sends segments of variable length; within a segment, each byte of data is assigned a sequence number. The receiving machine must send an acknowledgment for every byte it receives. TCP communication is thus a system of transmissions and acknowledgments. The Sequence Number and Acknowledgment Number fields of the TCP header (described in the preceding section) provide the communicating TCP software with regular updates on the status of the transmission. A separate sequence number is not encoded with each individual byte. Instead, the Sequence Number field in the header gives the sequence number of the first byte of data in a segment. There is one exception to this rule. If the segment occurs at the beginning of a connection (see the description of the three-way handshake later in this section), the Sequence Number field contains the ISN, which is actually one less than the sequence number of the first byte in the segment. (The first byte is ISN +1.) If the segment is received successfully, the receiving computer uses the Acknowledgment Number field to tell the sending computer which bytes it has received. The Acknowledgment Number field in the acknowledgment message will be set to the last received sequence number +1. In other words, the Acknowledgment Number field defines which sequence number the computer is prepared to receive next. If an acknowledgment is not received within the specified time period, the sending machine retransmits the data beginning with the byte after the last acknowledged byte. Establishing a ConnectionFor the sequence/acknowledgment system to work, the computers must synchronize their sequence numbers. In other words, Computer B must know what initial sequence number (ISN) Computer A used to start the sequence. Computer A must know what ISN Computer B will use to start the sequence for any data Computer B will transmit. This synchronization of sequence numbers is called a three-way handshake. The three-way handshake always occurs at the beginning of a TCP connection. The three steps of a three-way handshake are as follows:
After the three-way handshake, the connection is open, and the TCP modules transmit and receive data using the sequence and acknowledgment scheme described earlier in this section. TCP Flow ControlThe Window field in the TCP header provides a flow control mechanism for the connection. The purpose of the Window field is to ensure that the sending computer doesn't send too much data too quickly, which could lead to a situation in which data is lost because the receiving computer can't process incoming segments as quickly as the sending computer can transmit them. The flow control method used by TCP is called the sliding window method. The receiving computer uses the Window field (also known as the buffer size field) to define a window of sequence numbers beyond the last acknowledged sequence number that the sending computer is authorized to transmit. The sending computer cannot transmit beyond that window until it receives the next acknowledgment. Closing a ConnectionWhen it is time to close the connection, the computer initiating the close, Computer A, places a segment in the queue with the FIN flag set to one. The application then enters what is called the fin-wait state. In the fin-wait state, Computer A's TCP software continues to receive segments and processes the segments already in the queue, but no additional data is accepted from the application. When Computer B receives the FIN segment, it returns an acknowledgment to the FIN, sends any remaining segments, and notifies the local application that a FIN was received. Computer B sends a FIN segment to Computer A, which Computer A acknowledges, and the connection is closed.
ÅÀŢšîŃŤ ÅÝÅçîŢţůîŧîî
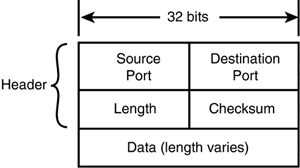
îÅçŃ šŧîîîîÅ¥ÅçŧîŃÅý UDP: The Connectionless Transport ProtocolUDP is much simpler than TCP, and it doesn't perform any of the functions listed in the preceding section. However, there are a few observations about UDP that this hour should mention. First, although UDP is sometimes described as having no error-checking capabilities, in fact, it is capable of performing rudimentary error checking. It is best to characterize UDP as having the capability for limited error checking. The UDP datagram includes a checksum value that the receiving machine can use to test the integrity of the data. (Often, this checksum test is optional and can be disabled on the receiving machine to speed up processing of incoming data.) The UDP datagram includes a pseudo-header that encompasses the destination address for the datagram, thus providing a means of checking for misdirected datagrams. Also, if the receiving UDP module receives a datagram directed to an inactive or undefined UDP port, it returns an ICMP message notifying the source machine that the port is unreachable. Second, UDP does not offer the resequencing of data provided by TCP. Resequencing is most significant on a large network, such as the Internet, where the segments of data might take different paths and experience significant delays in router buffers. On local networks, the lack of a resequencing feature in UDP typically does not lead to unreliable reception. By the Way UDP's lean, connectionless design makes it the protocol of choice for network broadcast situations. A broadcast is a single message that will be received and processed by all computers on the subnet. Understandably, if the source computer had to simultaneously open a TCP-style connection with every computer on the subnet in order to send a single broadcast, the result could be a significant erosion of network performance. The primary purpose of the UDP protocol is to expose datagrams to the Application layer. The UDP protocol itself does very little and therefore employs a simple header structure. The RFC that describes this protocol, RFC 768, is only three pages in length. As mentioned earlier, UDP does not retransmit missing or corrupted datagrams, sequence datagrams received out of order, eliminate duplicated datagrams, acknowledge the receipt of datagrams, or establish or terminate connections. UDP is primarily a mechanism for application programs to send and receive datagrams without the overhead of a TCP connection. The application can provide for any or all of these functions, if they are necessary for the application's purpose. The UDP header consists of four 16-bit fields. See Figure 6.9 for the layout of the UDP datagram header. Figure 6.9. The UDP datagram header and data payload.
The following list describes these fields:
Because the actual UDP header does not include the source or destination IP address, it is possible for the datagram to be delivered to the wrong computer or service. Part of the data used for the checksum calculation is a string of values extracted from the IP header known as the pseudo-header. The pseudo-header provides destination IP addressing information so that the receiving computer can determine whether a UDP datagram has been misdelivered. |
|
|
Source code editor
Website development
ÿ£¢