JavaScript Validator
JavaScript Editor
JavaScript Validator
JavaScript Editor
Databases are another of those big topics covered by enough books to fill a library. In this section we'll just be taking the briefest of tours, giving us enough information to get started. We will cover databases themselves, how to define and design them, and look at a brief summary of SQL, the language used to talk to databases. If you are already familiar with these topics, you may want to go straight to the next section where we start to talk about accessing databases from web pages.
We'll be using Microsoft's Access database for our examples, though much of what we'll be talking about applies to any relational database. I'm using Access XP, but Access 95, 97, or 2000 will work just as well. Access is a good database for individual use and for intranet websites that don't expect high numbers of concurrent users. However, it would not be suitable for a big e-commerce website on the Internet; it does not cope well with large numbers of users and doesn't have the security of something like MS SQL Server 2000.
The aim of a database is to store information. However, some logical way of organizing the structure of this information is also needed. This can be achieved through a series of tables, each containing data that logically fits together. Such databases are called relational databases and are the most common form of database found in use.
Tables themselves contain data separated into records, each record being a set of related data. For example, my hospital medical record is all the medical information relating to me. It might contain my name, age, address, illnesses I've had, operations I've had, and so on. The important thing is that it all relates to me. You will have your own separate medical record, storing the same bits of information, that is, name, age, and so on, but obviously it'll be your age and name information, not mine. Each item of information stored inside a record, for example name, age, and address, is called a field. We have a name field, an age field, an address field, and so on.
To recap, a database contains tables, tables contain records, and records are made up of fields.
When we design our database, we create our own tables and specify the field names that they will contain. Let's use an example to explore these concepts. Imagine we're creating a database for a big computer parts supplier called CompBitsCo. This database may contain one table with information about the stock that the company has, another table containing information about their customers, and yet another containing information about the orders made by the customers.
In our example of the CompBitsCo company database, what information might be stored in the stock information table?
The information may be things like the item description, cost of the item, and the number in stock. There's probably lots more information that could be stored, but we'll keep things simple for our example.
Each piece of information (for example the description, cost, or number in stock) is represented by a field in the database table. We need to specify a unique name for each field inside the table and specify what sort of data it will be storing. For example, it might be storing text, such as the item's description; numbers, such as the stock number; currency, such as the cost of an item; or dates, such as the date the next delivery of stock is due. There is a wide range of data types that can be stored, although some are more common than others. A list of some of the main data types available in an Access database is shown in the following table:
|
Data Type |
Description |
|---|---|
|
Text |
Can store up to 255 characters |
|
Memo |
Can store up to 64,000 characters |
|
Number |
Numerical data |
|
Date/Time |
Stores dates and times |
|
Currency |
Stores monetary values |
|
Yes/No |
Can store values that are Yes/No or True/False |
Different databases will support different data types. Although all of them support common ones like text and number, they may have a different name and be able to store different amounts of data.
Let's define some fields for the stock table in our example.
First we have the item description. We'll give this field a logical descriptive name like the ItemDescription field. It's going to be holding text so its data type is clearly Text.
The next field is the number of items available for a particular product. Let's call this the NumberInStock field. It will hold numerical data, so its field type will be Number.
Finally we have the cost information, for which the field name ItemCost seems fairly logical and descriptive. We could use the number for the format of the field's data, but because it's money data, the Currency data type seems more logical in this circumstance.
So now we have the collection of fields shown in the following table.
|
Field Name |
Data Type |
|---|---|
|
ItemDescription |
Text |
|
NumberInStock |
Number |
|
ItemCost |
Currency |
It is important to note that even relatively small databases could have hundreds of fields. If they were not grouped in some logical way, trying to make sense of it all could prove challenging, to say the least. This is why databases often contain multiple tables, with fields logically grouped together into one table or another. For example, the CompBitsCo database will contain another table of customer information, which contains fields such as customer name and customer address.
We mentioned earlier the concept of a record, which consists of data corresponding to a group of fields. For example, if we had an item called a Widget, with 10 in stock, and they cost $10.99, then our ItemDescription field would hold Widget. NumberInStock would hold 10, and ItemCost would hold $10.99. Collectively this data is called a record. A table can have many, many records. For example, a second record might show that ItemDescription is BigWidget, NumberInStock is 7, and ItemCost is $16.99.
Let's create a new Access database and add the stock table discussed previously.
First open up Access. Once it's opened create a new database by clicking the "New Database" link if you're using Access XP. If you're using an older version, select Blank Access database from the dialog box and click OK. (See Figure 17-1.)
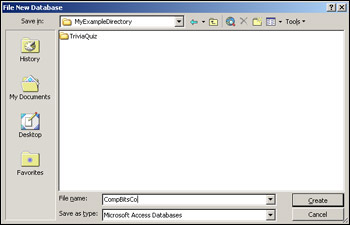
The dialog box shown in Figure 17-2 then allows us to pick a file name and location for the new database. It enters db1.mdb as a suggested name for the database. Change this to CompBitsCo.mdb and place it in the AWalkOnTheServerSide virtual directory and click Create.
We now have our database. Let's create our first table, which we'll call the Stock table.
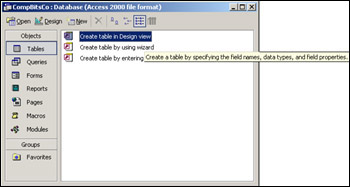
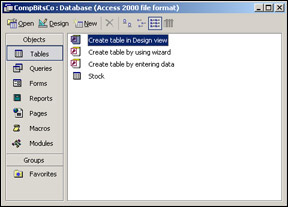
In the view as shown in Figure 17-3, make sure that Tables is selected under Objects; then double-click Create table in Design view.
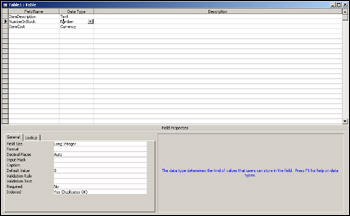
We're now in table design view and have a blank table in front of us that needs to have its fields defined as we defined them previously. Figure 17-4 shows how it should look after all the fields have been defined. Type the field names into the appropriate Field Name boxes. When we click each Data Type box, a drop-down list will appear allowing us to choose the data type for that field.
Although each field has a data type, this data type itself has various properties, which are shown under the General tab in the bottom left of the screen. Where these properties need to be changed I'll point it out, otherwise we can leave them at their default values.
The ItemDescription field has the Text data type, which itself has the Field Size property. The default for this is 50. This simply sets aside the space that might be required for this field, in terms of the number of characters it can hold. We can set it to any value from 1 to 255.
The NumberInStock field has the Number data type, which also has the Field Size property. However, this time we're given a choice from a drop-down list, which appears when we click on the Field Size input box. For our purposes the default value of Long Integer is fine, but it's worth noting that this field defines which type of numbers can be stored in the field. It goes from the smallest, a Byte, which can only hold a whole number from 0 to 255, right up to a Double, which is a floating-point number holding a very large range of values. The Replication ID value of Field Size is a number, but for specialized purposes outside the scope of this book.
Why not just pick the Field Size that can hold the biggest number? Or choose the maximum number of characters for a field?
On a small scale using this strategy may just be acceptable, but imagine the effect on a large database with a hundred thousand customers, where even a small waste of space could have big consequences. When deciding the data type, we need to choose the smallest possible field size that will do the job and perhaps allow a little flexibility. For example, with the NumberInStock field we've chosen the Long Integer type, which will allow whole numbers up to 2,147,483,647. However, we might be able to cut the size of storage space of the field in half and use an Integer Field Size, which allows whole numbers up to 32,767. Whether we did this would depend on how much stock we expect to be held at any one time. If there's even a remote possibility that in the future the stock held would be more than 32,767, we should choose Long Integer. If, on the other hand, the largest stock level ever recorded was 2,000 and it's not expected to get much larger, we could choose the Integer field size. There's no hard and fast rule; just use good judgment.
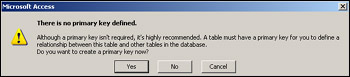
With all the fields complete, we can close the table, making sure to save it first. Choose the name Stock for the table when asked. When we save the table, a dialog box like that shown in Figure 17-5 will appear asking if we want to create a primary key. Click No. We'll look at primary keys later and create one then.
Before we add some data to the database, we'll create the tables necessary to store customer and customer order data.
To complete our information storage for CompBitsCo, let's see what fields we might need to store customer and order information.
For customers, we'll probably want to store the name, address, and telephone number. For orders, we'll want to store an order number, an order date, which customer ordered the goods, and which and how many goods were ordered.
Our fields will look something like those shown in the following table.
|
Field Name |
Data Type |
|---|---|
|
CustomerName |
Text |
|
CustomerAddress |
Text |
|
TelNumber |
Text |
|
OrderNo |
Number |
|
OrderDate |
Date |
|
GoodsOrdered |
Text |
|
QtyOrdered |
Number |
We now need to split the fields into tables. The important points to remember when splitting fields into tables is that we need some sort of sensible split. We need to allow data to be retrieved efficiently at a later date, and we want to avoid data replication, that is, the unnecessary repetition of data.
We could lump the whole lot into one table, say the CustomerAndOrders table. This would work, but it would be very bad design, because it would be wasteful of storage space; we'd be duplicating data. Let's see what data would look like if it were stored in one table and we'll see why it's wasteful.
Assume that we need to store information for a customer called Mr. Big who has ordered three items. The data in the table would look like the following:
|
Customer Name |
Customer Address |
Tel Number |
Order No |
Order Date |
Goods Ordered |
Qty Ordered |
|---|---|---|---|---|---|---|
|
Mr Big |
Some place, somewhere |
1234 5678 |
112 |
1 Jan 2000 |
SomeBit |
2 |
|
Mr Big |
Some place, somewhere |
1234 5678 |
112 |
1 Jan 2000 |
AnotherBit |
7 |
|
Mr Big |
Some place, somewhere |
1234 5678 |
112 |
1 Jan 2000 |
ALittleBit |
1 |
From the data in the table we can see that we've stored the customer's name, address, phone number, order number, and order date three times, when just once would do. The only things that are unique from row to row are the goods ordered and their quantity. This suggests that the goods ordered and their quantity need to go in a table on their own. We should have two tables, a CustomerOrder table and an OrderItem table. The CustomerOrder table will contain the fields CustomerName, CustomerAddress, TelNumber, OrderNo, and OrderDate. The OrderItem table will contain GoodsOrdered, QtyOrdered, and OrderNo. If we don't include the OrderNo field, we'll have no way of telling which order the goods relate to. By using it, for any row in the OrderItems table we just look up the OrderNo in the CustomerOrder table to see who ordered it.
Currently this leaves the CustomerOrder table looking like this:
|
Field Name |
Data Type (Field Size) |
|---|---|
|
CustomerName |
Text (50) |
|
CustomerAddress |
Text (255) |
|
TelNumber |
Text (25) |
|
OrderNo |
Number (Long Integer) |
|
OrderDate |
Date |
The OrderItem table looks like this:
|
Field Name |
Data Type (Field Size) |
|---|---|
|
OrderNo |
Number (Long Integer) |
|
GoodsOrdered |
Text (255) |
|
QtyOrdered |
Number (Integer) |
However, another change we will make is within the CustomerOrder table; instead of creating the OrderNo field as a number we'll create it as an AutoNumber field, a special type of number field that automatically populates a new record with a unique number, usually the next number available for that field. We'll look at this field in more detail later.
Let's create these tables in Access as we did for the Stock table. Within Access, make sure that Tables is selected under Objects, as shown in Figure 17-6.
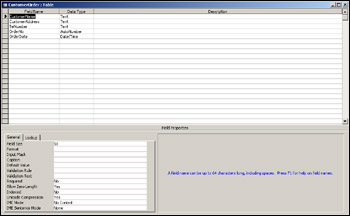
We'll first create the CustomerOrder table, so double-click Create table in Design view, and then create the fields as shown in Figure 17-7. Note again that the properties of each field under the General tab can be left at their default values except CustomerAddress, which needs a Field Size of 255, and TelNumber, which needs a Field Size of 25.
Make sure you save the table as CustomerOrder before closing it. When offered the opportunity to create a Primary Key, click No.
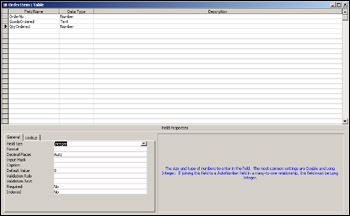
Now repeat the previous steps to create the OrderItem table, again leaving the field properties at their default values. The completed fields are shown in Figure 17-8. Save the table as OrderItem, and again don't select a primary key.
Now that we have our three tables defined, we need to look at how some fields in the tables are related to one another.
Before we can populate our tables with data, we still have a few issues that need resolving with our database design. First, although we have a Stock table containing all the things customers can buy and an OrderItem table containing all the things customers have bought, there's no relationship between them. For example, we could have an item in the OrderItem table that does not appear in the Stock table. This would be very strange. How can customers have bought an item that CompBitsCo doesn't even sell, and if they did buy it, how much did it cost? Cost information is in the Stock table. Also, if a customer buys something, we need to look up the item's cost in the Stock table. Then when it has been purchased, we need to change the amount of stock held. Therefore we need two things:
A way of matching items in the OrderItem table to items in the Stock table
A way of ensuring that the OrderItem table can never contain items that don't exist in the Stock table
Currently we have a GoodsOrdered field containing the name of the item ordered. We could use this to match the same item in the Stock table. This helps us with the first requirement in the previous list, that is, matching items in the two tables, but it doesn't help with the second requirement, ensuring that items in the OrderItem table are in the Stock table. Also, using a text field with the name of the item is very wasteful of both storage space and computer processing. Say our item is called a GruntMaster 7000. That's using approximately 10 bytes for necessary information about the field and then 32 bytes of memory for the actual characters, and given that there may be lots of customer orders for a GruntMaster 7000, it means this waste is repeated again and again. Also, when doing a comparison between the GoodsOrdered field in the OrderItems table and the ItemDescription field in the Stock table, the computer has to compare 32 bytes before being sure the two rows are the same. So what's the alternative?
The alternative is to use numbers, giving each item in the Stock table its own unique ID. We simply need to add an extra field to the Stock table, call it something like StockId, and make it a Long Integer field size. Then in the OrderItem table, instead of including the item's name we just include its StockId. Using a long integer requires only 4 bytes of memory, which makes for a big saving on storage space and makes comparisons between tables quicker. This process is called normalization.
Let's start by adding a StockId field to the Stock table.
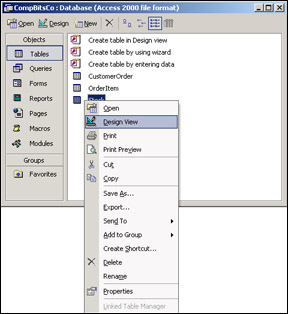
From the table view, right-click the Stock table and select Design View, as shown in Figure 17-9. You can also select the Design icon from the toolbar.
Now that we're in design view, right-click the ItemDescription field and select Insert Rows as shown in Figure 17-10.
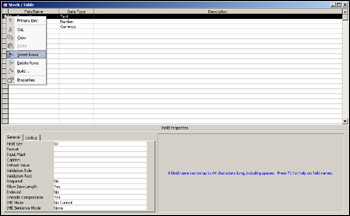
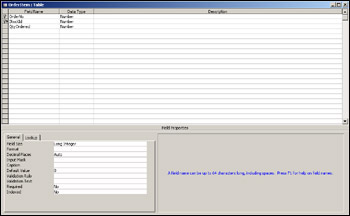
Complete the field definition as shown in Figure 17-11, with a field name of StockId and the type as Number with a Field Size of Long Integer.
The primary way of looking up information in the Stock table is the StockId field that we just created. We can speed up the look-up of data in key fields such as StockId by making it the primary key. What this really means is that the field is indexed internally by Access so that it can do data lookups a lot faster. By saying it's the primary key, we're saying it's the most important index. We can define other indexes, but only one primary index or primary key, although as we'll see later, the primary key can be made up of more than one field. To make StockId the primary key in Access, we simply right-click the StockId field and select Primary Key from the menu shown in Figure 17-12. Note that a primary key must contain unique data. So, for example, we couldn't have two stock ids with the value 28.
Once the field has been defined as the primary key field, we'll see a little key symbol next to the row defining the field. Also notice that the Indexed property changes from Yes (Duplicates OK) to Yes (No Duplicates). This is because primary key fields must contain unique data so that Access can quickly sort and find data.
The StockId field is simply a made up number we're using to enable items to be uniquely identified and represented in the OrderItems table. The number given for that field is not important, so long as it's unique for that table. To save us from having to think up a unique number for each StockId, we can use Access's AutoNumber data type. To change the data type of the StockId field, simply click the Data Type box and choose AutoNumber from the drop-down list. Now whenever we add information about a stock item, the StockId field will automatically be given a number. In fact, we aren't able to edit the value in an autonumber field.
Save the changes to the Stock table. However, before we leave it, let's add some stock data. To add data, it is easiest to switch from table design view to the data sheet view. We can either select the data sheet icon or select Datasheet View from the View menu.
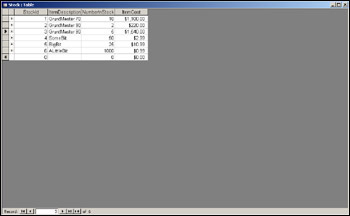
Now enter some example stock items. Each row represents one record, that is, the information provided by the fields for one stock item. Some example values are shown in Figure 17-13. Remember that the autonumber field populates itself so don't try entering a value for the StockId. When finished, close the table. There is no need to save it since values are stored each time you move from one record (that is, one row) to another.
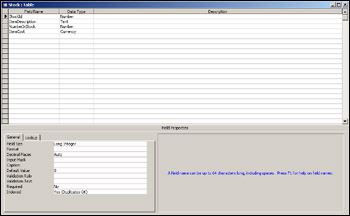
We need to change the OrderItem table to reflect the changes made in the Stock table. View the OrderItem table in design view. We need to change the name of the GoodsOrdered field to StockId and its data type from Text to Number with a field size of Long Integer. Why Long Integer and not AutoNumber? Information for this field will be taken from the StockId field of the Stock table and will not be created independently of it.
When finished, the table should look like the one in Figure 17-14. Note that while field data types can be changed easily when there is no data in the table, once the table has been populated with data we should avoid changing data types or we may find that data gets corrupted or changed.
Should we go further and make StockId a primary key field? In this table it's not actually the StockId that's primary for looking up a record. In fact, to uniquely identify a record we need to look up the OrderNo and StockId fields, so they must both be indexed as primary fields. Although we can have only one primary key index, it can consist of more than one field. To index these, we need to click the gray box to the left of each field. First click the OrderNo field, and then holding down the Ctrl key, click the StockId field, so that both fields are blacked out. Now click the primary key icon in the toolbar and both fields will be indexed as primary keys.
Remember to save the table before closing it.
One of the issues we mentioned regarding the Stock and OrderItem tables is ensuring that there are no products in the OrderItem table that don't exist in the Stock table. We could say that there is a relationship between the two tables, in particular regarding the StockId field. This relationship is that for each item of stock in the Stock table there may be zero or more occurrences of that item in the OrderItem table. So, while there is only one definition in the Stock table of the GruntMaster 7000, we may have lots of orders in which a GruntMaster 7000 was sold and hence many occurrences of it in the OrderItem table. We call this a one-to-many relationship between the tables. There are also one-to-one relationships and many-to-many relationships. The one-to-many relationship is probably the most common.
Databases allow us to define these relationships, but why would we want to do so?
An important aspect of relationships is enforcing data integrity. We've already said that it's illogical to have orders for items that CompBitsCo doesn't sell. In terms of the database, this means that we shouldn't have items in the OrderItem table for which the StockId does not exist in the Stock table. Careful programming should prevent us from ever entering illogical data like this, but there's nothing to stop someone from adding values to the database directly, and it's always possible that a bug in our program could allow invalid data to creep in. After a database contains some invalid data, it can be an awful job cleaning it up.
If, however, we specify a relationship rule in the database itself that says we can only insert a StockId into the OrderItem table if it exists in the Stock table, then we are enforcing this rule regardless of whether data is entered by directly typing it in or by programming. With relationships we can guarantee the validity of our data.
So how do we go about defining a relationship in Access?
Let's create a one-to-many relationship between the OrderItem table and Stock table based on the StockId field.
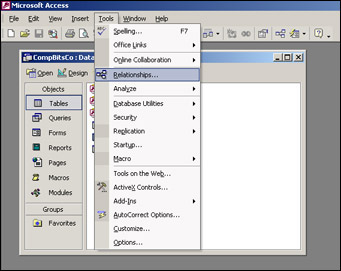
First we need to choose Relationships from the Tools menu, as shown in Figure 17-15.
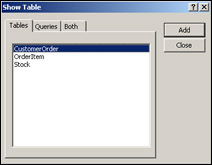
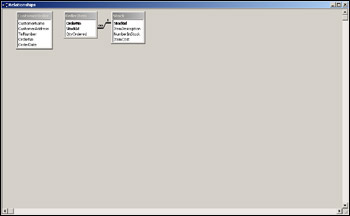
Because this is the first time we've opened up the relationship tool, we'll be given the option of adding tables from our database onto the relationship diagram in the Show Table window. Double-clicking each of the tables in turn will add it to the diagram. After all three tables have been added to the diagram, as shown in Figure 17-16, click Close.
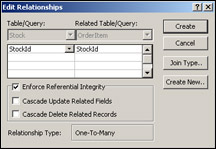
In the Relationships window, click the StockId field in the OrderItem table and, keeping your mouse button down, drag over to the StockId field in the Stock table before releasing your mouse button; the Edit Relationships dialog box will appear. We want to ensure that the relationship is enforced, so make sure the Enforce Referential Integrity box is checked. Once we've done this, we click the Create button and the new relationship will be defined and data integrity enforced. (See Figure 17-17.)
The relationship is displayed on the diagram by a line connecting the related fields in each table. It also indicates the type of relationship, such as one-to-one, one-to-many, or many-to-many. We can see in Figure 17-18 that Access has put a 1 next to the StockId field in the Stock table and has put an infinity symbol (Ґ) next to the OrderItem table indicating that there can be as many of the same StockId values in this table as we wish.
If we want to examine any relationship, we just double-click the relationship lines between tables. If we want to delete a relationship, we just right-click the line and choose Delete.
Before closing the Relationships diagram, be sure to click the Save icon to store the newly defined relationships to the database.
That completes our very brief look at creating a database, which is now at an acceptable stage for an example database. If we were to use it in a live situation, we would probably want to refine its structure even further and add more relationships.
For example we could add an Order table, and move the OrderNo and OrderDate fields from the CustomerOrder table to the Order table. We could then add an extra field to both tables to relate the two tables. Why would we do this? Currently if the same customer places an order on two or more occasions, we are creating duplicate information; we store that customer's name and address more than once in the CustomerOrder table. After you've read this chapter you might want to look again at this database and see how you could improve it.
Our next task is to look at how we can query the database to find information stored inside it and then add, update, or delete records. To do this we need to use Structured Query Language (SQL), which is the topic of the next section.
To access data inside a database we need to use a special data manipulation language called Structured Query Language (SQL, pronounced "sequel"). The vast majority of relational databases support SQL, including Microsoft Access.
We'll be concentrating on just a small part of the language, enough to perform essential functions, such as getting information out of the database, updating records, adding new records, and deleting records.
Pieces of SQL code are normally referred to as queries. Initially we'll be using Access to run our SQL queries to see how they work, but later in the chapter we'll see how we can run the queries from JavaScript in a web page.
Let's start by looking at how we can retrieve information from the database.
SQL provides the select statement, which enables us to specify which fields we want to retrieve information for. Note the capitalization: For good programming, all SQL command keywords are written in capitals, although SQL itself is case insensitive.
For example, if we want to retrieve records with just the fields StockId, ItemDescription, and NumberInStock, our query would start as follows:
select StockId, ItemDescription, NumberInStock
We then need to specify which table the fields are selected from. StockId appears in two tables, Stock and OrderItems, so there could be some confusion if no table is specified. To specify the table, we write from and then the name of the table (or tables) from which the fields are being selected.
select StockId, ItemDescription, NumberInStock from Stock
Let's try this out in Access and see the results. In our CompBitsCo Access database, click on Queries under the Objects tab, as shown in Figure 17-19.
Now double-click Create query in Design view and the design dialog box shown in Figure 17-20 will open.
Because we're learning about SQL, we want to create the SQL ourselves rather than have Access do it for us. To switch to the SQL view, we first need to click the Close button in the Show Table window. Next click the SQL icon in the toolbar and we'll be taken to the SQL view, with just the word select; inside the SQL editing box, as shown in Figure 17-21.
Change the SQL inside the text box to our query.
select StockId, ItemDescription, NumberInStock
from Stock
| Note |
Note that, like JavaScript, the end of a SQL statement is indicated by a semicolon, and again like JavaScript, most of the time leaving it off won't cause problems. |
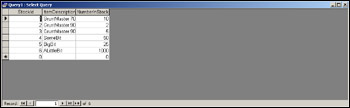
To run the query we need to either click the Run icon (the exclamation mark) from the toolbar, select Run from the Query menu, or select Datasheet View from the View menu. Access will process our query and display the results in a grid like the one shown in Figure 17-22.
To return to the SQL view, choose SQL View from the View menu.
In addition to specifying which fields we want to view, we can also select which records are displayed by using a where clause that we add to our select statement. For example, if we wanted just those records in which the number of items in stock was less than ten we would write the following:
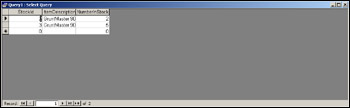
select StockId, ItemDescription, NumberInStock from Stock where NumberInStock < 10
Because the field we are searching is a numerical field, we don't place 10 in quotes. However, if it is a text field, we must put the 10 in quotes, just as we do with JavaScript strings.
Alter the SQL in our Access query to read as shown in the previous code and rerun it. This time only records matching our where clause's criteria are returned to the set of records, as shown in Figure 17-23.
If we want to specify more than one criterion in the where clause, we can use Boolean operators, such as AND and OR. For example, if we wanted all records where the NumberInStock was less than 10 and the StockId was 2, we'd change our SQL to the following:
select StockId, ItemDescription, NumberInStock from Stock where NumberInStock < 10 AND StockId = 2
Before we leave the select statement, we'll look at how we can order the records returned using the order by clause.
Let's say we want to order our results by the field NumberInStock. To do this we add the order by clause to the end of the query, after any where clause we might have, and specify the fields that will determine the resulting set's order.
select StockId, ItemDescription, NumberInStock from Stock where NumberInStock < 10 order by NumberInStock
This will return results in ascending order; that is, from lowest to highest. If we want it in descending order, from highest to lowest, we type desc after the fields being ordered.
select StockId, ItemDescription, NumberInStock from Stock where NumberInStock < 10 order by NumberInStock desc
If we want to order the data by more than one field, we just add the fields to be ordered in a list separated by commas. The first field will be ordered first; then if there are two matching items, the order will be decided by the next field. If they are still the same, they will be ordered by the next field and so on. So to order by NumberInStock then StockId, we'd write the following:
select StockId, ItemDescription, NumberInStock from Stock where NumberInStock < 10 order by NumberInStock, StockId
To change the value of existing records in the database, SQL has the update statement. We can use this to update records en masse or just an individual record. It allows us to specify which fields in a table are to be updated and what value they are to be updated with. An essential part of the update statement is the where clause; if we don't specify a where clause, every record in a table will be updated.
For example, if we wanted to update the stock levels for the GruntMaster 9000 Upgrade to 5, we would create the following SQL:
update Stock
set NumberInStock = 5
where StockId = 2
First we tell the database what we want to do, that is, we want to update the table named Stock. Then we specify which fields are to be set to new values and what the values are. Here we've just set one field; if we wanted to update more than one field, we would just add a comma then the field name and value as follows:
set NumberInStock = 5, ItemCost = 150
Finally, we have our where clause, which includes a criterion that specifies the records that are to be affected by the update. Here, by specifying the StockId, which is unique for each record, we ensure that just one record is updated.
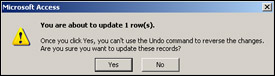
You can try this query in Access as we did for the select query by selecting Queries from the Objects tab, clicking Create query in Design view, and then switching to the SQL view. When you run the query, Access will tell you how many records will be updated and give you the chance to cancel the query, as shown in Figure 17-24. We click Yes to proceed with the update.
In addition to updating with actual values that we specify, we can also update by selecting information from the database itself. For example, let's increase our prices by 10% by running the following query:
update Stock set ItemCost = ItemCost * 1.1
To insert a new record into the database, SQL has the aptly named insert statement. To use insert we need to tell it the name of the table, the fields in that table that we want to insert data in, and the values we wish to insert.
For example, to insert a new stock item called an UltraPC that costs $5000 and that isn't in stock, our SQL would be as follows:
insert into Stock (ItemDescription, NumberInStock, ItemCost) values ('UltraPC',0,5000)
First we told the database what we wanted to do: We wanted to insert a record. Then we stated that the table into which the new record would be going was the Stock table. We then specified in parentheses which fields we were putting new data into. Finally we specified the values that would be inserted into each field.
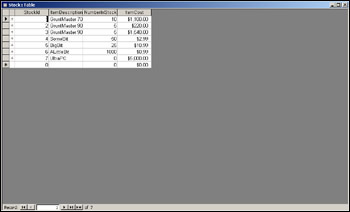
If we type the SQL into Access and run it, our Stock table should now contain the data shown in Figure 17-25.
Deleting records is very easy; we use the delete statement, with from to specify the table from which records are to be deleted, and use a where clause to specify the criteria for determining the records to be removed. If we don't include a where clause, all the records from that table will be deleted.
For example, to remove all items costing under $5, would require the following SQL:
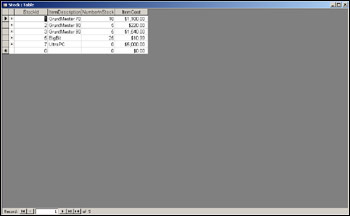
delete from Stock where ItemCost < 5
Run this query in Access. It will remove the items SomeBit and ALittleBit, leaving our table with the records shown in Figure 17-26.
The final SQL statements we will look at are the IN and NOT IN operators. These allow us to search for a list of items. Let's say we wanted to search for all items whose NumberInStock is 5, 10, or 20. We could write the following code
select StockId, NumberInStock from Stock where NumberInStock = 5 OR NumberInStock = 10 OR NumberInStock = 20
or we could use IN and write it like this:
select StockId, NumberInStock from Stock where NumberInStock IN (5, 10, 20)
Basically, in plain English this is saying "where NumberInStock is equal to any of the values in the list 5, 10, 20".
The opposite of IN is NOT IN. For example, if we wanted all stock where NumberInStock is not 5, 10 or 20, we'd change our where as follows:
select StockId, NumberInStock from Stock where NumberInStock NOT IN (5, 10, 20)
That completes our whirlwind tour of SQL in which we looked at just the basics of the language. However, it has given us enough knowledge to start creating SQL queries in web pages, the topic of the next section.
JavaScript Validator
JavaScript Editor