JavaScript Validator
JavaScript Editor
JavaScript Validator
JavaScript Editor
The good news is we learned most of what we need to manipulate XML in a web browser from the previous chapter when we learned all about manipulating the DOM. The bad news is that while browser support for XML JavaScript is getting better and better with each new browser release, it's still far from perfect and there are still a lot of cross-browser issues. We'll be concentrating in IE 5.5+ (on Windows; the Mac version of IE doesn't support XML) and Netscape 6+ cross-browser-compatible script because these browsers have much improved XML JavaScript support.
Our first task is to read in the XML document. This is where the most cross-browser problems are because IE and NN have quite different ways of reading documents, NN being the more standards-compliant and IE being the easier and more comprehensive route. The good news is that once the XML document is loaded, the differences between NN and IE are smaller, although Microsoft has added a lot of useful nonstandards-compliant extensions to its implementation.
The key is the load() method of the DOM document object, which is supported by Netscape and IE browsers. Let's create a new page, JS_XML.htm, and load our pdalist.xml file into it.
In IE 5+, we rely on the ActiveXObject() object to fetch an XML file.
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM"); xmlDoc.load("myfile.xml");
With the preceding, IE 5 loads "myfile.xml" into browser memory and awaits further instructions from you.
In NN 6, the syntax required is equally straightforward.
var xmlDoc= document.implementation.createDocument("","doc",null); xmlDoc.load("myfile.xml");
An unavoidable step these days, let's combine the code to create something that'll work with IE and Netscape.
if (window.ActiveXObject) var xmlDoc = new ActiveXObject("Microsoft.XMLDOM"); else if (document.implementation && document.implementation.createDocument) var xmlDoc= document.implementation.createDocument("","doc",null); xmlDoc.load("myfile.xml");
Notice how two levels of object detection are required in NN's case.
Before we actually attempt to manipulate the XML file, we should first make sure it has completely loaded into the client's browser cache. Otherwise, we're rolling the dice each time our page is viewed and running the risk of a JavaScript error being thrown whenever the execution of our script precedes the complete downloading of the XML file in question. Fortunately, there are ways to detect the current download state of an XML file, albeit some more refined than others. Let's start with the crude methods first.
In IE and now Netscape 7.1, the async property denotes whether IE should wait for the specified XML file to fully load before proceeding with the download of the rest of the page. Short for asynchronous, by default this property is set to true, meaning the browser will not wait on the XML file before rendering everything else that follows. By setting this property to false instead, we can instruct IE to load the file first, then, and only then, the rest of the page.
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM"); xmlDoc.async=false //Download XML file first, then load rest of page (IE only) xmlDoc.load("myfile.xml");
In NN, the onLoad event handler is supported for XML objects, so we can simply use that.
var xmlDoc= document.implementation.createDocument("","doc",null); xmlDoc.load("myfile.xml"); xmlDoc.onload=customfunction //Detect complete loading of XML file (NN only)
Most XML-related scripts we've seen rely on the previous two techniques to ensure a connection between the XML file and the script that manipulates it. There is more we can do, however, especially in IE.
For IE, the simplicity of the async property is not without its flaw: When we set this property to false, IE will stall the page until it makes contact and has fully received the info that is our specified XML file. When the browser is having trouble connecting/downloading the file, our page is left hanging like a monkey on a branch. This is where the readyState property can help so long as we haven't set the async property to false.
The readyState property of IE exists for XML objects and many HTML objects, and returns the current loading status of the object. The following table shows the five possible return values.
|
Return Values for the readyState Property |
Description |
|---|---|
|
0 |
The object has not yet started initializing (uninitialized). |
|
1 |
The object is initializing, but no data is being read (loading). |
|
2 |
Data is being loaded into the object and parsed (loaded). |
|
3 |
Parts of the object's data has been read and parsed, so the object model is available. However, the complete object data is not yet ready (interactive). |
|
4 |
The object has been loaded, its content parsed (completed). |
The value we're interested in here is the last one, 4, which indicates the object has fully loaded. Using it, the following code will return true if our XML file has completely loaded:
if (xmlDoc.readyState==4) alert("XML file loaded!")
With the readyState property, it's easy to create a mechanism for detecting when an XML object has loaded, and abort the rest of the script should this process take longer than the designated time frame (5 seconds). This keeps the unwelcome surprises at bay as far as dealing with slow or nonloading XML files. Take a look at the following code:
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM"); xmlDoc.load("myfile.xml"); var times_up=false var expiretime=5000 //set expire time to abort. 5 seconds. function XMLloadcontrol() { if (times_up==true) { //if designated time frame has expired alert ("XML Load Aborting"); xmlDoc.abort(); return; } else if (xmlDoc.readyState==4) { //if xml file has loaded within time frame myFunction() //execute the rest of the script return } else //else call this function again, setTimeout("XMLloadcontrol ()",100) } if (window.ActiveXObject) { setTimeout("times_up=true", expiretime) //set abort download time (5 sec). XMLloadcontrol() } }
All that our routine really does is continuously check the readyState of the XML file until 5 seconds has elapsed, and performs two different actions depending on the outcome. Here we assume myFunction() is the function that is to be run should the XML file download successfully.
OK, with the potential hazards of our eager script too quickly accessing the XML file avoided, we can now move on to see how to actually manipulate the file.
We've seen how to load an XML file into browser memory as follows:
if (window.ActiveXObject) { var xmlDoc = new ActiveXObject("Microsoft.XMLDOM"); xmlDoc.async=false; //Enforce download of XML file first. IE only. } else if (document.implementation && document.implementation.createDocument) var xmlDoc= document.implementation.createDocument("","doc",null); xmlDoc.load("myfile.xml");
Once an XML file is retrieved, manipulating it is the same as manipulating any web page using the DOM. We use the relevant DOM methods. That's the beauty of the DOM; it doesn't discriminate.
Using the following simple XML file, let's retrieve and display a daily message using DHTML.
<?xml version="1.0"?> <messages> <daily>Today is Sunday.</daily> <daily>Today is Monday.</daily> <daily>Today is Tuesday.</daily> <daily>Today is Wednesday.</daily> <daily>Today is Thursday.</daily> <daily>Today is Friday.</daily> <daily>Today is Saturday.</daily> </messages>
Here we have a basic XML file populated with a different message for each day of the week. Following is the corresponding script to retrieve and display today's message.
<body> <div id="container" style="background-color:yellow"></div> <script language="javascript" type="text/javascript"> //load xml file if (window.ActiveXObject) { var xmlDoc = new ActiveXObject("Microsoft.XMLDOM"); xmlDoc.async=false; //Force download of XML file first. IE only. } else if (document.implementation && document.implementation.createDocument) { var xmlDoc= document.implementation.createDocument("","doc",null); } if (typeof xmlDoc!="undefined") { xmlDoc.load("dailynews.xml"); }
Regular expressions are used to match any non-whitespace character as follows:
var notWhitespace = /\S/ function getdaily() { //Cache "messages" element of xml file var msgobj=xmlDoc.getElementsByTagName("messages")[0] //Remove white spaces in XML DOM tree. Intended mainly for NN for (i=0;i<msgobj.childNodes.length;i++) { if ((msgobj.childNodes[i].nodeType == 3)&& (!notWhitespace.test(msgobj.childNodes[i].nodeValue))) { // that is, if it's a whitespace text node msgobj.removeChild(msgobj.childNodes[i]) i-- } } var dateobj=new Date() var today=dateobj.getDay() //returns 0-6. 0=Sunday //Get today's message and display it in DIV: document.getElementById("container").innerHTML= xmlDoc.getElementsByTagName("messages")[0].childNodes[today].firstChild.nodeValue } if (typeof xmlDoc!="undefined") { if (window.ActiveXObject) //if IE, simply execute script (due to async prop). getdaily() else { //else if NN6, execute script when XML object has loaded xmlDoc.onload=getdaily } </script> </body>
First, using the DOM method document.getElementsByTagName(), we create a reference to the <messages> tag of the XML DOM and store the result in msgobj.
The code that follows removes all potential white space within the child elements contained inside the element node, creating a common document tree across IE and NN. In NN, white spaces are considered nodes as well (TEXT), whereas in IE, they are not. To illustrate this, consider the following container:
<parent> <son>This is my son Timmy</son> </parent>
In IE, childNodes[0] of the <parent> tag returns <son>, as we might expect. In NN, however, childNodes[0] actually returns a white space, or "blank" space, between the two tags. This blank space is considered a TEXT node. Due to this, childNodes[1] is needed to correctly reference <son> in NN. One way to overcome this diverging treatment of the document by IE and NN is to remove all potential white spaces inside it, as we've done inside ours. This allows us to then use the same set of indexes for IE and NN to access the various elements inside the xml file.
Finally, we get today's date (day of the week), and use it as the index of the <daily> element for which to retrieve and display text.
Let's create an example that uses a modified version of our PDA XML file.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>JS And XML</title> <script language="javascript" type="text/javascript"> var xmlDocument; // IE5+ if (window.clipboardData) { xmlDocument = new ActiveXObject("Microsoft.XMLDOM"); xmlDocument.load("pdalist6.xml"); } // NN6+ else if (.implementation && document.implementation.createDocument) { xmlDocument = document.implementation.createDocument("","",null); xmlDocument.load("pdalist6.xml"); } function displayPDAS() { var xmlNode = xmlDocument.getElementsByTagName('pda'); var newTableElement = document.createElement('TABLE'); newTableElement.setAttribute('cellPadding',5); var tempElement = document.createElement('TBODY'); newTableElement.appendChild(tempElement); var tableRow = document.createElement('TR'); // Create table heading for ( iRow = 0; iRow < xmlNode[0].childNodes.length; iRow++) { if (xmlNode[0].childNodes[iRow].nodeType != 1) continue; var tableheadElement = document.createElement('TH'); var textData = document.createTextNode(xmlNode[0].childNodes[iRow].nodeName); tableheadElement.appendChild(textData); tableRow.appendChild(tableheadElement); } tempElement.appendChild(tableRow ); var i; var iRow; for (i=0; i < xmlNode.length;i++) { var tableRow = document.createElement('TR'); for (iRow=0; iRow < xmlNode[i].childNodes.length; iRow++) { if (xmlNode[i].childNodes[iRow].nodeType != 1) { continue; } var tdElement = document.createElement('TD'); var textData = document.createTextNode(xmlNode[i].childNodes[iRow].firstChild.nodeValue); tdElement.appendChild(textData); tableRow.appendChild(tdElement); } tempElement.appendChild(tableRow); } // remove old table before adding new one if (document.all) { // IE specific code document.all.displayPDAInfo.innerHTML = ""; } else { // NN code var child = document.getElementById('displayPDAInfo').childNodes.item(0); document.getElementById('displayPDAInfo').removeChild(child) } document.getElementById('displayPDAInfo').appendChild(newTableElement); } </script> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> </head> <body> <p><A HREF="javascript:displayPDAS()">Display PDA Info</A></p> <p id="displayPDAInfo"> </p> <p> </p> </body> </html>
Save this as JS_XML.htm. Now let's modify the pdalist.xml file so it looks like this:
<?xml version="1.0" encoding="iso-8859-1"?> <pdalist> <pda> <manufacturer>Palm</manufacturer> <name> Tungsten T3</name> <os> Palm 5.2.1</os> <processor> Intel XScale 400MHz</processor> <price>$399</price> </pda> <pda> <manufacturer>Sony</manufacturer> <name>Clie PEG-NX73V</name> <os>Palm 5</os> <processor>Intel XScale 200MHz</processor> <price>$450</price> </pda> <pda> <manufacturer>HP</manufacturer> <name>iPAQ H5550</name> <os>Pocket PC2003</os> <processor>Intel XScale 400MHz </processor> <price>$550</price> </pda> </pdalist>
Save this as pdalist6.xml.
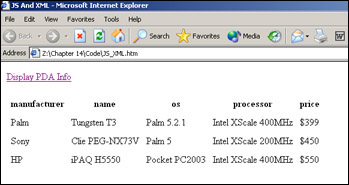
If we load this page we see a single link. Click the link, and the details of our XML file are displayed, as shown in Figure 14-13.
Let's take a closer look at the code. First of all we need to load the XML document and make it accessible through the object xmlDoc.
<script language="javascript" type="text/javascript">
var xmlDocument;
// IE5+
if (window.clipboardData)
{
xmlDocument = new ActiveXObject("Microsoft.XMLDOM");
xmlDocument.load("pdalist6.xml");
}
// NN6+
else if (window.sidebar)
{
xmlDocument = document.implementation.createDocument("","",null);
xmlDocument.load("pdalist6.xml");
}
Next the displayPDAS () function starts by creating an array of all the <pda> tags in the XML document. For each of these tags we want to create a TR containing several TDs with the data.
function displayPDAS()
{
var xmlNode = xmlDocument.getElementsByTagName('pda');
Then we create a new TABLE with CELLPADDING=5. Note the special spelling cellPadding, Explorer requires this and it doesn't hurt Netscape.
var newTableElement = document.createElement('TABLE');
newTableElement.setAttribute('cellPadding',5);
Explorer requires that we also create a TBODY and append it to the table. Without it the example doesn't work in Explorer.
var tempElement = document.createElement('TBODY');
newTableElement.appendChild(tempElement);
First of all, we need a row with THs for the headers. Create a TR as follows:
var tableRow = document.createElement('TR');
Then go through the childNodes of the first pda.
for ( iRow = 0; iRow < xmlNode[0].childNodes.length; iRow++)
{
There is a problem here. The XML document looks like this:
<pda>
<manufacturer>
This means that Netscape considers the text node between pda and name as the first child of pda. Since these nodes are only a nuisance, we have to determine if the nodeType of the childNode is 1 (meaning it's an element node). If it isn't, continue with the next child.
if (xmlNode[0].childNodes[iRow].nodeType != 1) continue;
Create a container element (TH).
var tableheadElement = document.createElement('TH');
Then we read the name of the childNode (for example, manufacturer, name, os, processor, and price). We want these names to be printed inside the TH. So first we append the name to the TH; then we append the container to the TR.
var textData = document.createTextNode(xmlNode[0].childNodes[iRow].nodeName); tableheadElement.appendChild(textData); tableRow.appendChild(tableheadElement); }
Finally, append the row to the TBODY tag.
tempElement.appendChild(tableRow );
Then we go through all elements in the pda and create a TR for each one.
for (i=0; i < xmlNode.length;i++)
{
var tableRow = document.createElement('TR');
Go through the childNodes of each pda, check to see if it's a node (tag) and create a TD to hold the data.
for (iRow=0; iRow < xmlNode[i].childNodes.length; iRow++)
{
if (xmlNode[i].childNodes[iRow].nodeType != 1) continue;
var tdElement = document.createElement('TD');
Then extract the actual data. Remember that the text inside a tag is the nodeValue of the first childNode of that tag.
var textData = document.createTextNode(xmlNode[i].childNodes[iRow].firstChild.nodeValue);
Append the text to the TD and the TD to the TR
tdElement.appendChild(textData);
tableRow.appendChild(tdElement);
}
and when we've finished going through the pda, append the TR to the TBODY.
tempElement.appendChild(tableRow); }
Next we want to remove the previous table; otherwise, if the link is clicked more than once it'll just keep appending and appending tables.
if (document.all)
{
// IE specific code
document.all.displayPDAInfo.innerHTML = "";
}
else
{
// NN code
var child = document.getElementById('displayPDAInfo').childNodes.item(0);
document.getElementById('displayPDAInfo').removeChild(child)
}
Finally, when we've gone through each pda, append the TABLE to the special P with ID="displayPDAInfo" created.
document.getElementById('displayPDAInfo').appendChild(newTableElement);
}
The table is created.
JavaScript Validator
JavaScript Editor