JavaScript Validator
JavaScript Editor
JavaScript Validator
JavaScript Editor
The advantage of XML over other document formats is that it specifies a protocol by which a document can describe itself. As an example, this document might describe itself as a title, followed by a brief introduction, and then sections: each section might have a heading and be broken into one or more paragraphs. This description is called a Document Type Declaration (DTD). The DTD appears as a prologue in the document and can be included as text in the document or linked in as a separate file, allowing it to be shared by many documents. The declaration of the elements that make up this article might look like this:
<!DOCTYPE chapterOfABook [ <!ELEMENT title (#PCDATA)> <!ELEMENT intro (#PCDATA)> <!ELEMENT section (heading,paragraph+)> <!ELEMENT heading (#PCDATA)> <!ELEMENT paragraph (#PCDATA)> ]>
Some elements contain other elements. In the preceding example, the element section contains one heading and one or more paragraphs, while others contain data in the form of text (intro contains #PCDATA; #PCDATA refers to character data). These elements then become tags to be used in the document. For example, the title might appear like this:
<title>This is my title</title>
A DTD defines a clear set of rules that allow documents to be validated. According to the example DTD, any document that follows these rules is a document type known as a chapterOfABook.
In my example, a document is something that contains and organizes text. While this is often the case, an XML document is also capable of organizing data that is not human readable. Examples of non-human-readable data are multimedia files (images, digital recordings, and so on) and instructions that have been compiled for use by a computer. Thinking of a document as a generic container for any type of data helps us understand the potential use of XML.
The information provided by the DTD, known as metadata, is used to suggest what information the document should contain. It provides the grammar against which an XML document can be checked and validated, though manipulation is possible without DTDs. Because XML is a non-proprietary standard, the opportunity exists for varied applications to create and share documents without prior knowledge of their intended target. The inclusion of metadata in a document increases XML's potential yet again.
The next thing we need to learn is the basic syntax of XML. The syntax rules of XML are very simple and very strict. Unlike HTML, which is fairly forgiving of syntax errors, XML won't let us get away with sloppy syntax. However the good news is that the rules are very easy to learn and very easy to use.
It's time to put all the theory we've learned into practice. XML is all about data, so we need data for our example. For this tutorial we will use information about handheld computers or PDAs (Personal Digital Assistants). Here are some data fields we might want to know about:
Manufacturer
Name
Operating System
Processor
Color or Gray Scale Screen
Screen Size In Pixels
Memory: RAM/ROM
Price
Let's fill in some actual data about three PDAs. Following is a table with the data we are going to use.
|
Data Fields / PDAs |
PDA 1 |
PDA 2 |
PDA 3 |
|---|---|---|---|
|
Manufacturer |
Palm |
Sony |
HP |
|
Name |
Tungsten T3 |
Clie PEG-NX73V |
iPAQ H5550 |
|
Operating System |
Palm 5.2.1 |
Palm 5 |
Pocket PC2003 |
|
Processor |
Intel XScale 400MHz |
Intel XScale 200MHz |
Intel XScale 400MHz |
|
Color/Grey Scale Screen |
16 bit Color |
16 bit Color |
16 bit Color |
|
Screen Size (Pixels) |
320 * 480 |
320 * 480 |
240 * 320 |
|
Memory (RAM/ROM) Meg |
64/16 |
16/32 |
128/48 |
|
Price |
$399 |
$450 |
$550 |
OK, lets take that information and create an XML document that we'll be saving as pdalist.xml. Use NotePad or any text editor to create the document.
<?xml version="1.0" encoding="iso-8859-1"?> <pdalist> <pda> <name> </name> <os> </os> <processor> </processor> <screen> <color> </color> <pixels> <width> </width> <height> </height> </pixels> </screen> <memory> <ram> </ram> <rom> </rom> </memory> <price> </price> </pda> </pdalist>
We have entered just the tags we are going to be using. We will fill in the data after explaining what we have typed here.
Tags should be descriptive. That is what XML is all about. We create the tags (markups) to describe the data the XML it will contain. Tags can be more than one word and the use of spaces and capitalization is the developer's prerogative. Remember that XML is case-sensitive, unlike the more forgiving HTML.
<?xml version="1.0" encoding="iso-8859-1"?>
This is the XML declaration we saw earlier. It tells the application that is going to use this XML document which version of the specification we are using. Right now there is only version 1.0, so we don't have to state it. Most XML parsers (more on this later) assume XML version 1.0, and the next draft of the XML standard will specify which version the parser should assume if this is missing. Next, notice that the line starts with "<?" and ends with "?>". These are the delimiters that indicate there is an XML declaration instruction in between them. In this case, the instruction tells which version of XML we are using. The declaration also states the character encoding used in the document. In this case the document conforms to the 1.0 specification of XML and uses the ISO-8859-1 (Latin-1/West European) character set.
Now let's discuss our tags: Every tag must have an opening and a closing. The first tag set we have describes the type of data our XML file contains, which is a PDA list. Thus we have the following tags:
<pdalist> </pdalist>
The rest of the file, except for the declaration, must be between these tags. The section between these tags is also known as the root element. Remember the case sensitivity: pdaList is different than PDAList so the starting and ending tags must match!
Our next set of tags is shown here:
<pdalist>
<pda>
<name> </name>
<os> </os>
<processor> </processor>
<screen>
<color> </color>
<pixels>
<width> </width>
<height> </height>
</pixels>
</screen>
<memory>
<ram> </ram>
<rom> </rom>
</memory>
<price> </price>
</pda>
</pdalist>
Notice we have an opening and closing tag for <pda>, and in our listing, there are many more elements in between. This is where actual information about a PDA will be entered. Unlike our <pdalist> tag, of which there can be only one, we could have multiple <pda> tag sets, one for each PDA. Each <pda> tag represents a node. A tag that has data is called an element. See how our tags describe the data. Going back to our tags, we have two data types that are associated with the screen: color and pixels. We can nest these tags within the screen tag so they are logically grouped. Then, within pixels we have the number of pixels for height and width and again we nested these. This hierarchy of nodes, subnodes, and elements allows us to create data records in a descriptive and logical manner that might not be easy to represent in a row/table model of relational databases unless we used linked tables.
Let's recap our syntax rules as they apply to elements. Following is a list with a brief description of each. These are essential to XML.
Elements can have attributes: These are values that are passed to the application (in our case the Internet browser such as IE or Netscape) but are not part of the element content. Attributes are contained in the opening tag of the element and must be in quotes. Some people use attributes in place of creating a child node. Here is an example that we might use in place of our memory child node:
<Memory type="RAM">64</RAM> <Memory type="ROM">16</RAM>
Elements can have entities: Entities are used in a document as a way to avoid retyping long repetitive pieces of text. They provide a way to associate a name with the text so wherever we might have the text appear, we use only the entity name instead. We can include comments: We all know that we should comment our code. XML documents are no different. Using comments allows others to understand what you are doing.
We can include processing instructions: These are used as instructions to the application using the XML file. A processing instruction takes the following form:
<?NameOfTargetApplication InstructionForApplication?>
We've not as yet added the PDA information into the tags, so let's do that now.
<?xml version="1.0" encoding="iso-8859-1"?> <pdalist> <pda> <name>Tungsten T3</name> <os> Palm 5.2.1</os> <processor>Intel XScale 400MHz</processor> <screen> <color>Yes</color> <pixels> <width>320</width> <height>480</height> </pixels> </screen> <memory> <ram>64</ram> <rom>16</rom> </memory> <price>$399</price> </pda> <pda> <name>Clie PEG-NX73V</name> <os>Palm 5</os> <processor>Intel XScale 200MHz</processor> <screen> <color>Yes</color> <pixels> <width>320</width> <height>480</height> </pixels> </screen> <memory> <ram>16</ram> <rom>32</rom> </memory> <price>$450</price> </pda> <pda> <name>iPAQ H5550</name> <os>Pocket PC2003</os> <processor>Intel XScale 400MHz </processor> <screen> <color>Yes</color> <pixels> <width>240</width> <height>320</height> </pixels> </screen> <memory> <ram>128</ram> <rom>48</rom> </memory> <price>$550</price> </pda> </pdalist>
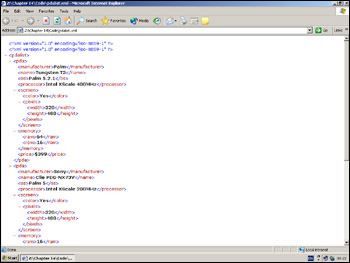
Save the file as pdalist.xml and load it into a browser. In IE 6, we should see a page like the one shown in Figure 14-1.
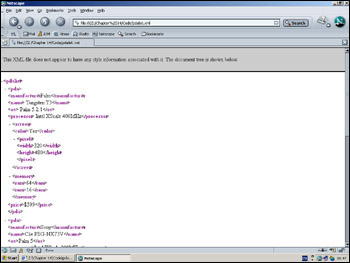
And in Navigator 7.1, our page will look like the one in Figure 14-2.
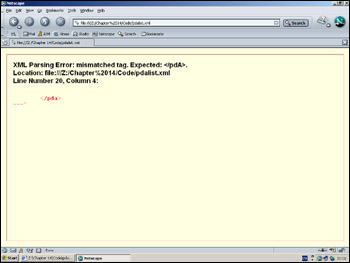
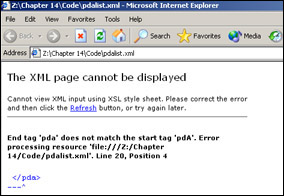
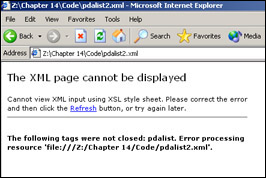
If we make a mistake, even a small one, our browser will display a message like the one in Figure 14-3 or Figure 14-4.
The deliberate mistake is I changed <pda> to <pdA>.
Because the browser can display XML, it also checks the tags to make sure they match or are correctly ordered. Note that you may see a different look depending on the browser. Both IE and Netscape have used XSLT, which formats the look (we'll learn more about XSLT later in the chapter). However, Opera doesn't have that.
Here is something else: If we look at the XML file in our browser (see Figure 14-1) and find the tag for <memory>, we will see a red dash. Click on it, and that part of the hierarchy is closed up. We can expand and collapse elements/nodes that have children. You can collapse an entire PDA or the whole list.
The reason you can display this XML file in IE5+ and Netscape 7.1+ and have it colored and be collapsible is that they have a default style sheet built in for those XML files that don't reference a style sheet of their own. Using a style sheet with XML is termed eXtensible Stylesheet Language (XSL). (More on this later.)
If we make a layout mistake in building our XML file, the browser will tell us where things don't match up; it will not inform us if the mistake is related to the actual data. We are all human and prone to mistakes (not often, but they do happen!).
In this section, we introduce two new terms that relate to this issue. They are well formed and valid. XML documents must be well formed or they can be valid, or they can be both.
Well-formed documents are those that comply with the rules of XML syntax. This includes, and this is not an all-inclusive list, the following:
All elements having a closing tag, or a closing slash in the empty element.
The document must contain one or more elements.
Elements must be nested correctly within the root element.
So was our first XML file well formed? It was well formed but it was not valid. For our original data of "color/gray scale" screens, for the tag <color>, we used Yes and No as the data. In the other PDAs we could have used Color and Grey Scale. Making a DTD and thus making our XML file valid prevents these changes or discrepancies from happening.
Before we proceed, let's take a look at why our document was well formed:
We had an XML declaration. Remember this: <?xml version="1.0"?>. It is in lowercase, without preceding spaces or other characters. Although not essential, we should also specify the character set we are using. This is important if we are using a character set other than the standard ASCII:
<?xml version="1.0" encoding="iso-8859-1" ?>
We have a unique tag for our document and it has a matching ending tag and the case matches! This was <pdalist> and </pdalist>. This is our root element. Note that tags can start with a letter, an underscore, or a colon character followed by any combination of letters, digits, hyphens, underscores, colons, and periods. We cannot start a tag with the letters XML in any combination of upper- or lowercase.
We have more than our required root element. We have a PDA element and each PDA element has several other elements.
Our elements are nested. height and width are nested inside of pixels. pixels are nested under screen, as is the color element. Nothing is out of order.
This is just the bare minimum. Other rules exist concerning attributes, processing instructions, namespaces, CDATA sections, and even general entities and parameter entities.
Badly formed documents will give us errors when we try to load them into the browser. Here is just a portion of our XML file. Copy and paste it into a new text file, save it as pdalist2.xml, and then load it in a browser.
<?xml version="1.0" encoding="iso-8859-1"?> <pdalist> <pda> <name> Tungsten T3</name> <os> Palm 5.2.1</os> <processor> Intel XScale 400MHz</processor> <screen> <color>Yes</color> <pixels> <width>320</width> <height>480</height> </pixels> </screen> <memory> <ram>64</ram> <rom>16</rom> </memory> <price>$399</price> </pda> <pda> <name>Clie PEG-NX73V</name> <os>Palm 5</os> <processor>Intel XScale 200MHz</processor> <screen> <color>Yes</color> <pixels> <width>320</width> <height>480</height> </pixels> </screen> <memory> <ram>16</ram> <rom>32</rom> </memory> <price>$450</price> </pda> <pda> <name>iPAQ H5550</name> <os>Pocket PC2003</os> <processor>Intel XScale 400MHz </processor> <screen> <color>Yes</color> <pixels> <width>240</width> <height>320</height> </pixels> </screen> <memory> <ram>128</ram> <rom>48</rom> </memory> <price>$550</price> </pda>
Figure 14-5 shows what we will get first. Notice that we missed the closing tag for our root element <pdalist>. Thus our document was not well formed.
As mentioned earlier, valid documents are well-formed documents that also conform to a DTD. A DTD provides the structure for an XML document. Look at an e-mail; it has structure. The e-mail has the T: field, a Subject field, and the body. There are even optional cc and bcc fields. The e-mail program fills in the From field, and the date and time sent, for us, but they are there. The structure is so familiar to us we don't really notice it, unless it gets messed up in the transmission! This structure makes it intelligible, familiar, and easy to read. Now if another program processes this e-mail (which is data, when you get down to it), it must be parsed. Knowing a structure means it can be parsed and parsed correctly each and every time, time after time.
DTDs lay out the way an XML file is to be marked up. Anyone following this DTD could process an XML file from others who have also built their XML files to the same DTD. We could even read it and know what the data was and understand it. Following a DTD also means that we can trap for errors if a file that is not well formed or had the wrong data is passed to us. Examples of DTDs that are not well formed include those in which tags are out of order or a required field is blank and, yes, DTDs that are not well formed might even include the wrong data or type of data.
Enough about what a DTD can do. Let's build one and see.
The purposes of a DTD are as follows:
Declare what our markup is
Declare what our markup means.
But how do we build one? There is an entire specification on how to write DTDs. We will only touch on some of the items that can be used in a DTD as we build ours.
Start a new file, name it pdalist.dtd, and follow along. Here is what our DTD will look like:
<!-- The pdalist DTD --> <!ELEMENT pdalist (pda+) > <!-- <pda> section --> <!ELEMENT pda (name, os, processor, screen, memory, price?) > <!ELEMENT name (#PCDATA) > <!ELEMENT os (#PCDATA) > <!ELEMENT processor (#PCDATA) > <!ELEMENT screen (color,pixels) > <!-- <screen> section --> <!ELEMENT color (#PCDATA) > <!ELEMENT pixels (height, width) > <!-- <pixels> section --> <!ELEMENT height (#PCDATA) > <!ELEMENT width (#PCDATA) > <!-- end <pixels> section --> <!-- end <screen> section --> <!ELEMENT memory (ram|rom) > <!-- <memory> section --> <!ELEMENT ram (#PCDATA) > <!ELEMENT rom (#PCDATA) > <!-- end <memory> section --> <!ELEMENT price (#PCDATA) > <!-- ======= END of pdalist DTD ======= -->
The first line, which follows, is a comment. Anything in between <!— and —> will be ignored.
<!-- ======= The pdalist DTD ======= -->
It is always good to comment your code.
<!ELEMENT pdalist (pda+) >
The previous line is our root declaration and all declarations follow the format
<!ELEMENT name (content)>
This declaration is used to declare the tags we are using. Since we are at the root element we use the pdalist as the name, and under pdalist we have multiple pdas, thus the + symbol.
Next we have another comment to indicate that we are now describing our pda section.
<!-- <pda> section -->
Our element name is pda and a pda contains the following elements: name, os, processor, screen, memory, and price. The question mark after the price indicates that price is optional; it does not have to be part of a pda. The commas between each item indicate that this element has strict ordering. If any element is out of order, the file is not valid. Because screen and memory have subelements, we will further define them later. Again, remember this is like defining a tree, which has branches and leaves.
<!ELEMENT pda (name, os, processor, screen, memory, price?) >
Here is the start of our actual element type declarations. Our element name will contain character data, indicated by #PCDATA. The # symbol prevents PCDATA from being interpreted as an element name.
<!ELEMENT name (#PCDATA) >
<!ELEMENT os (#PCDATA) >
<!ELEMENT processor (#PCDATA) >
<!ELEMENT screen (color,pixels) >
<!-- <screen> section -->
<!ELEMENT color (#PCDATA) >
<!ELEMENT pixels (height, width) >
<!-- <pixels> section -->
<!ELEMENT width (#PCDATA) >
<!ELEMENT height (#PCDATA) >
<!-- end <pixels> section -->
<!-- end <screen> section -->
<!ELEMENT memory (ram,rom) >
<!-- <memory> section -->
<!ELEMENT ram (#PCDATA) >
<!ELEMENT rom (#PCDATA) >
<!-- end <memory> section -->
<!ELEMENT price (#PCDATA) >
<!-- ======= END of pdalist DTD ======= -->
That's it. Now if we go to the W3C website and read the actual spec, we will find there are many more options and choices but this is the simplest way to write our DTD. Now how do we use a DTD? That's next, of course.
Our pdalist.xml file was well formed, which we discussed earlier. We just built a DTD to make sure our pdalist.xml file was also valid. But how do we put the two together so when the XML file is loaded we know we are using a valid XML file? That requires adding a declaration to our XML file. The first line in an XML file must be the xml declaration, and nothing is allowed to come before this. This line, for a refresher, is as follows:
<?xml version="1.0" encoding="iso-8859-1"?>
To use a DTD, whether it is internal or external, we need to add a line just below the <?xml _version="1.0" encoding="iso-8859-1"?>, which has the following form:
<!DOCTYPE name SYSTEM uri>
!DOCTYPE indicates the XML parser that we are specifying a document to use as part of this file. The name is replaced with pdalist, the name of our root element. SYSTEM lets our XML file know that we are using an external DTD, a DTD found outside of the XML file. Finally, the uri is the location of the DTD. Remember that a URI is a subset of a URL. If our DTD were on a web server, the URI would be a path like http://myserver/myxmlstuff/myfile.dtd. If our DTD and the XML file reside in the same folder, we can enter just the name of the DTD; we do not need the absolute path. Here is what our declaration will look like:
<!DOCTYPE pdalist SYSTEM "pdalist.dtd">
We need to add this line to the top of our XML file so it looks like this, and save it as pdalist3.xml:
<?xml version="1.0"?> <!DOCTYPE pdalist SYSTEM "pdalist.dtd"> <pdalist> <pda>
If we load the page into our browser we won't see anything different from before. However, let's change something in the pdalist3.xml file, so we know there is a mistake. Save the file and open the pdalist3.xml file in a browser. Do we get an error? No. That is because IE and Netscape can parse XML but do not validate it. Third-party applications are available that will help us write XML, DTDs, and even test them for being well formed and valid. But for now, that is not something that all browsers do. Note that IE 5/Win allows JavaScript to validate an XML file.
If we do not want an external DTD but wish to include it with our XML file, this is what a portion of it would look like:
<?xml version="1.0"?> <!DOCTYPE pdalist[ <!ELEMENT pdalist (pda+)> <!ELEMENT pda (name, os, processor, screen, memory, price?)> <!ELEMENT name (#PCDATA)> ..................(rows removed for illustration)....................... <!ELEMENT memory (ram, rom)> <!ELEMENT ram (#PCDATA)> <!ELEMENT rom (#PCDATA)> <!ELEMENT price (#PCDATA)> ]> <pdalist>
Before we look at how we can alter the look of the XML in the page, let's recap the fundamental rules of XML syntax.
The following sections will give you a quick rundown of the basic rules of XML syntax.
The first line in the following document—the XML declaration—defines the XML version and the character encoding used in the document. In this case the document conforms to the 1.0 specification of XML and uses the ISO-8859-1 (Latin-1/West European) character set.
<?xml version="1.0" encoding="iso-8859-1"?> <email> <to>you@there.com</to> <from>me@here.com</from> <subject>New products</subject> <body>Just to let you know about our new products.</body> </email>
The next line describes the start tag of the root element of the document. (In this example, it's saying "this document is an email").
<email>
The next four lines are the four child elements of the root (to, from, subject, and body).
<to>you@there.com</to> <from>me@here.com</from> <subject>New products</subject> <body>Just to let you know about our new products.</body>
And finally, the last line defines the end of the root element.
</email>
With HTML we could miss the closing tag and often it'd still work. With XML we must always include a closing tag. Indeed in HTML some elements do not have to have a closing tag. The following code is acceptable in HTML:
<p>Paragraph One <p>Paragraph Two
In XML all elements must have a closing tag, like this:
<p>This is a paragraph</p> <p>This is another paragraph</p>
You might have noticed from the previous example that the following XML declaration does not have a closing tag:
<?xml version="1.0" encoding="iso-8859-1"?>
This is not an error. The declaration is not a part of the XML document itself. It is not an XML element, and it should not have a closing tag.
Unlike HTML tags, XML tags are case-sensitive. With XML, the tag <email> is different from the tag <Email>. Opening and closing tags must therefore be written with the same case.
<Email>Invalid</email> <email>Valid</email>
Improper nesting of tags makes no sense to XML.
In HTML, some elements can be improperly nested within each other like this:
<b><i>This text is bold and italic</b></i>
In XML, all elements must be properly nested within each other like this:
<b><i>This text is bold and italic</i></b>
All XML documents must contain a single tag pair to define a root element. All other elements must be within this root element. All elements can have subelements (child elements). Subelements must be correctly nested within their parent element.
<root> <child> <subchild>.....</subchild> </child> </root>
With XML, it is illegal to omit quotation marks around attribute values.
XML elements can have attributes in name/value pairs just like in HTML. In XML the attribute value must always be inside quotation marks. Study the following two XML documents. The first one is incorrect; the second is correct.
<?xml version="1.0" encoding="ISO-8859-1"?> <note date=12/11/2002> <to>Bob</to> <from>Sarah</from> </note>
Here we see the correct version:
<?xml version="1.0" encoding="ISO-8859-1"?> <note date="12/11/2002"> <to>Bob</to> <from>Sarah</from> </note>
The error in the first document is that the date attribute in the note element is not within quotations.
This is correct: date="12/11/2002". This is incorrect: date=12/11/2002.
With XML, the white space in your document is not truncated. This is, unlike HTML. With HTML, we can have a sentence like this:
Hello my name is Paul,
It will be displayed as follows because HTML strips off the white space:
Hello my name is Paul,
With XML, a new line is always stored as LF.
In Windows applications, a new line in the text is normally stored as a pair of CR LF (carriage return, line feed) characters. In Unix applications, a new line is normally stored as an LF character. Macintosh applications use only a CR character to store a new line.
The syntax for writing comments in XML is similar to that of HTML.
<!-- This is a comment -->
Let's take a look at the more common XML data elements.
Character data may be any legal (Unicode) character with the exception of <. The < character is reserved for the start of a tag and the ampersand (&) character.
XML also provides a couple of useful entity references that we can use to clarify whether we are specifying character data or markup. Specifically, XML provides the following entity references:
|
Actual Character |
Entity Reference |
|---|---|
|
> |
> |
|
< |
< |
|
& |
& |
|
' |
' |
Obviously, the < entity reference is useful for character data. The other entity references can be used within markup in cases in which there could be confusion, such as the following:
<STATEMENT VALUE = "She said, "Don't go there!"">
This line should be written as follows:
<statement value = "She said, "Don't go there!"">
A pretty good rule of thumb is to consider anything outside of tags to be character data and anything inside of tags to be markup. But unfortunately, in one case this is not true. In the special case of CDATA blocks, all tags and entity references are ignored by an XML processor that treats them just like any old character data.
CDATA blocks have been provided as a convenience measure when we want to include large blocks of special characters a character data, but we do not want to have to use entity references all the time. What if we wanted to write about an XML document in XML! Consider the following example:
<example> <document> <name>mrs smith</name> <email>mrssmith@herdomain.com</email> </document> </example>
As you can see, we would be forced to use entity references for all the tags, which looks messy and makes it tricky to read.
To avoid the inconvenience of translating all special characters, we can use a CDATA block to specify that all character data should be considered character data whether or not it "looks" like a tag or entity reference.
Consider the following example:
<example> <![CDATA[ <document> <name>mrs smith </name> <email>mrssmith@herdomain.com</email> </document> ]]> </example>
Not only will we sometimes want to include tags that we want the XML processor to ignore (display as character data) in our XML documents, but sometimes we will want to put character data that we want the XML processor to ignore (not display at all) in our document. Note that comments will be displayed when using the default style sheet. This type of text is called comment text.
We are familiar with comments from HTML. In HTML, we specified comments using the <!— and —> syntax. Well, I have some good news. In XML, comments are created in just the same way! So the following would be a valid XML comment:
<!--List The Beatles --> <name>John Lennon</name> <name>George Harrison</name> <name>Paul McCartney</name> <name>Ringo Starr</name> <!-- End the names -->
When using comments in our XML documents, however, we should keep a couple of rules in mind. First, we should never have a hyphen or a double hyphen (- or —) within the text of our comment because it might be confusing to the XML processor. Second, never place a comment within a tag. Thus, the following code would be poorly formed XML:
<name <!--The name --> >John Lennon</name>
Likewise, never place a comment inside of an entity declaration and never place a comment before the XML declaration, which must always be the first line in any XML document.
Comments can be used to comment out tag sets. Thus, in the following case, all the names will be ignored except for Ringo Starr.
<!-- don't show these <!-- <name>John Lennon</name> <name>George Harrison</name> <name>Paul McCartney</name> --> <name>Ringo Starr</name>
However, if we do comment blocks of tags, we must make sure that the remaining XML is well formed.
Secondly, once we've written our XML document in our new language, we must check it against the syntax rules laid down for XML documents and the rules in the schema or the DTD to see whether the code conforms.
JavaScript Validator
JavaScript Editor