JavaScript Validator
JavaScript Editor
JavaScript Validator
JavaScript Editor
The Document Object Model (DOM) is, as we've mentioned, a way of representing the document in a browser-independent way. It allows a user to access the document via a common set of objects, properties, methods, and events, and alter the contents of the web page dynamically, using script.
Several types of script languages, such as JavaScript and VBScript, are available. Each requires a slightly different syntax and therefore a different approach when programming. Even when using a language common to all browsers, such as JavaScript, some small variations are usually added to the language by the vendor. So, to guarantee that we don't fall afoul of a particular implementation, the W3C has provided a generic set of objects, properties, and methods that should be available in all scripting languages, in the form of the DOM standard.
We've avoided talking about the DOM standard so far, and that's for a particular reason: It's not the easiest standard to follow. Supporting a generic set of properties and methods has proved to be a very complex task, and the DOM standard has been broken down into separate levels and sections to deal with the different areas. The different levels of the standard are all at differing stages of completion.
Level 0 is a bit of a misnomer, as there wasn't really a level 0 of the standard. Level 0 in fact refers to the "old way" of doing things. By the old way, we mean the methods implemented by the browser vendors before the DOM standard. Someone mentioning level 0 properties is referring to a more linear notation of accessing properties and methods. For example, typically we'd reference items on a form with the following code:
document.forms[0].elements[1].value = "button1";
We're not going to cover such properties and methods in this chapter, because they have been superceded by newer methods.
Level 1 of the standard is the first version of the standard. It is split into two sections: One is defined as core (objects, properties, and methods that can apply to both XML and HTML) and the other as HTML (HTML-specific objects, properties, and methods). The first section deals with how to go about navigating and manipulating the structure of the document. The objects, properties, and methods in this section are very abstract. The second section deals with HTML only and offers a set of objects corresponding to all the HTML elements. This chapter mainly deals with the second section—level 1 of the standard.
In 2000, level 1 was revamped and corrected, though it only made it to a working draft and not to a full W3C recommendation
Level 2 of the standard is complete and many of the properties, methods, and events have been implemented by both main browsers. It has sections that add specifications for events and style sheets to the specifications for core and HTML-specific properties and events. It also provides sections on views and traversal ranges, neither of which we will be covering in this book, but there is more information at www.w3.org/TR/2000/PR-DOM-Level-2-Views-20000927/ and www.w3.org/TR/2000/PR-DOM-Level-2-Traversal-Range-20000927/. We will be making use of some of the features of the event and style sections of this level of the DOM later in this chapter because they have been implemented in the latest versions of both browsers.
Level 3 of the standard is still under development. It attempts to resolve a lot of the complications that still exist in the event model in level 2 of the standard, and adds support for XML features, such as contents models and being able to save the DOM as an XML document.
Almost no browser has 100% compliance to any standard, although some, such as NN 6 and 7, come pretty close with the DOM. Therefore, there is no guarantee that all of the objects, properties, and methods of the DOM standard will be available in a given version of a browser, although a few level 1 and level 2 objects, properties, and methods have been available in both browsers since version 4, and in Netscape's case, as far back as version 2. However, IE 5.5 and 6, and NN 6 and 7 offer by far the closest compliance so far.
Although in previous chapters we've aimed at supporting version 4 and later browsers, in this chapter it isn't possible. Much of material in the DOM standards has only recently been clarified, and a lot of DOM features and support have been added to only the latest browser versions. For this reason, examples in this chapter will be guaranteed to work on only the latest IE and NN versions. Although cross-browser scripting is much more realistic, backwards support isn't at all.
Although the standards might still not be fully implemented, they do provide a guideline as to how a particular property or method should be implemented, and a guideline for all browser manufacturers to agree to work toward in later versions of their browsers. The DOM doesn't introduce any new HTML tags or style sheet properties to achieve its ends. The idea of the DOM is to make use of the existing technologies, and quite often the existing properties and methods of one or other of the browsers.
We've already hinted strongly at the two main differences between the Document Object Model and the Browser Object Model. However, this difference is often confused because a BOM is sometimes referred to under the name DOM. Look out for this in any literature on the subject.
First, the DOM covers only the document of the web page, whereas the BOM offers scripting access to all areas of the browsers, from buttons to the title bar, including some parts of the page.
Second, the BOM is unique to a particular browser. This makes sense if we think about it; we can't expect to standardize browsers because they have to offer competitive features. Therefore we need a different set of properties and methods and even objects to be able to manipulate them with JavaScript.
Because HTML is standardized so that web pages can contain only the standard features supported in the language, such as forms, tables, images, and the like, a common method of accessing these features is needed. This is where the DOM comes in. The way that the DOM works is to have a uniform representation of the HTML document. This is achieved by representing the entire HTML document/web page as a tree structure.
Only the more recent browser versions (5 and higher) allow us to access all parts of the web page via such a tree structure. Up until then, they would only partially represent web pages in this tree structure, and leave bits, such as the text, beyond reach and inaccessible to script.
In fact, it is possible to represent any HTML document (in fact, any XML document) as a tree structure. The only precondition is that the HTML document should be well formed. We've already mentioned earlier why this is such a desirable attribute, but it doesn't hurt to emphasize it again. While different browsers might be tolerant, to a greater or lesser extent, of quirks such as unclosed tags, or HTML form controls not being enclosed within a set of <form> tags, for the structure of the HTML document to be accurately depicted, we need to be able to always predict the structure of the document. Abuses of the structure, such as unclosed tags, stop us from depicting the structure as a true hierarchy, and therefore cannot be allowed. Accessing elements via the DOM depends on the ability to represent the page as a hierarchy.
If you're not familiar with the concept of trees, don't worry. They're just a diagrammatic way of representing a hierarchical structure.
Let's consider the example of a book, which has several chapters. If instructed to, we could find the third line on page 543 after a little searching. If an updated edition of the book were printed with extra chapters, more likely than not, we'd fail to find the same text if we followed those same instructions. However, if the instructions were changed to, say, find the chapter on still-life painting, the section on using watercolors, and the paragraph on positioning light sources, we'd still be able to find it even in a reprinted edition with extra pages and chapters, albeit with perhaps a little more effort than the first request required.
Books aren't particularly dynamic examples, but given something like a web page, where the information could be changed daily, or even hourly, can you see why it would be of more use to give the second set of directions rather than the first? The same principle applies with the DOM. Navigating the DOM in a hierarchical fashion, rather than in a strictly linear way, makes much more sense. When we treat the DOM as a tree, it becomes easy to navigate the page in this fashion. Consider how we locate files on Windows using Windows Explorer, which creates a tree view of folders through which we can drill down. Instead of looking for a file alphabetically, we locate it by going into a particular folder.
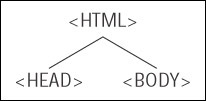
The rules for creating trees are simple. We start at the top of the tree with the document and the element that contains all other elements in the page. The document is the root node. A node is just a point on the tree representing a particular element or attribute of an element or even the text that an element contains. The root node contains all other nodes, such as the DTD declaration, the XML declaration, and the root element (the HTML or XML element that contains all other elements). The root element should always be the <html> tag in an HTML document. Underneath the root element comes the HTML elements that the root element contains. Typically an HTML page will have <head> and <body> elements inside the <html> element. These elements are represented as nodes underneath the root element's node, which itself is underneath the root node at the top of the tree. (See Figure 13-1.)
The two nodes representing the <head> and <body> elements are examples of child nodes and the <html> element's node above them is a parent node. Since the <head> and <body> elements are both child nodes of the <html> element, they both go on the same level underneath the parent node/<html> element. The <head> and <body> elements in turn contain other child nodes/HTML elements, which will appear at a level underneath their nodes. So, child nodes can also be parent nodes. Each time you encounter a set of HTML elements within another element, they each form a separate node at the same level on the tree. The easiest way of explaining this clearly is with an example.
Let's consider a basic HTML page such as this:
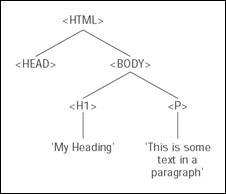
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> </head> <body> <H1>My Heading</H1> <P>This is some text in a paragraph</P> </body> </html>
The <html> element contains <head> and <body> elements. Only the <body> element actually con-tains anything. It contains an <H1> element and a <P> element. The <H1> element contains the text My Heading. When we reach an item, such as text, an image, or an element, that contains no others, the tree-structure will terminate at that node. Such a node is termed a leaf node. We then continue to the <P> node, which contains some text, which is also a node in the document. We can depict this as the tree structure shown in Figure 13-2.
Simple, eh? This example is almost too straightforward, so let's move on to a slightly more complex one that involves a table as well.
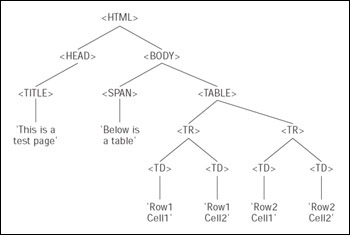
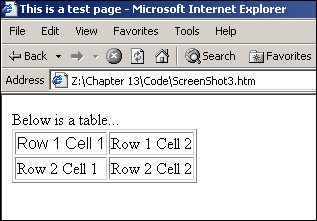
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>This is a test page</title> </head> <body> <span>Below is a table...</span> <table border=1> <TR> <TD>Row 1 Cell 1</TD> <TD>Row 1 Cell 2</TD> </TR> <TR> <TD>Row 2 Cell 1</TD> <TD>Row 2 Cell 2</TD> </TR> </table> </body> </html>
There is nothing out of the ordinary here. The document just contains a table with two rows, and two cells in each row. We can once again represent the hierarchical structure of our page (for example, the fact that the <html> tag contains a <head> and a <body> tag, and that the <head> tag contains a <title> tag, and so on) using our tree structure, as shown in Figure 13-3.
The top level of the tree is simple enough; the <html> element contains <head> and <body> elements. The <head> element in turn contains a <title> element and the <title> element contains some text. This text node is a child node that terminates the branch (a leaf node). We can then go back to the next node, the <body> element node, and go down that branch. Here we have two elements contained within the <body> element, the <span> and <table> elements. While the <span> element contains only text and terminates there, the <table> element contains two rows <TR>, and the two <TR> elements contain two table cell <TD> elements. Only then do we get to the bottom of the tree with the text contained in each table cell. Our tree is now a complete representation of our HTML code.
What we have seen so far has been highly theoretical, so let's get a little more practical now.
The DOM provides us with a concrete set of objects, properties, and methods accessible through JavaScript to navigate the tree structure of the DOM. Let's start with the set of objects, within the DOM, that is used to represent the nodes (elements, attributes, or text) on our tree.
Three objects are known as the base DOM objects. These are as follows:
|
Object |
Description |
|---|---|
|
Node |
Each node in the document has its own Node object. |
|
NodeList |
This is a list of all Node objects. |
|
NamedNodeMap |
This provides access by name rather than by index to all of the Node objects. |
This is where DOM differs from the BOM quite extensively. In the BOM objects have names that relate to a specific part of the browser, such as the window object, or the forms and images arrays. We've already explained that to be able to navigate in the web page as though it were a tree, we have to do it on a more abstract basis. We can have no prior knowledge of the structure of the page; everything ultimately is just a node. To move around from HTML element to element, or element to attribute, we have to go from node to node. This also means we can add, replace, or remove parts of our web page without affecting the structure as a whole, as we're just changing nodes. This is why we have three rather obscure sounding objects that represent our tree structure.
We've already mentioned that the top of our tree structure is the root node, and that the root node contains the XML declaration, the DTD, and the root element. Therefore we need more than just these three objects to represent our document. In fact there are different objects to represent the different types of nodes on the tree.
As we have seen, nodes come in a variety of types. Is it an element, an attribute, or just plain text? The Node object has different objects to represent each possible type of node. The following is a complete list of all the different node type objects that can be accessed via the DOM. A lot of them won't concern us in this book because they pertain to only XML documents and not HTML documents, but you should notice that our three main types of node, namely element, attribute, and text, are all covered.
|
Object |
Description |
|---|---|
|
Document |
The root node of the document |
|
DocumentType |
The DTD or schema type of the XML document |
|
DocumentFragment |
A temporary storage space for parts of the document |
|
EntityReference |
A reference to an entity in the XML document |
|
Element |
An element in the document |
|
Attr |
An attribute of an element in the document |
|
ProcessingInstruction |
A processing instruction |
|
Comment |
A comment in an XML document or HTML document |
|
Text |
Text that must form a child node of a element |
|
CDATASection |
A CDATA section within the XML document |
|
Entity |
An unparsed entity in the DTD |
|
Notation |
A notation declared within a DTD |
We're not going to cover most of these objects in this chapter, but if we need to navigate the DOM of an XML document, we will find ourselves having to use them.
Each of these objects inherits all the properties and methods of the Node object, but also has some properties and methods of its own. We will be looking at some examples of these in the next section.
If we tried to look at the properties and methods of all the objects in the DOM, it would take up half the book. Instead we're going to actively consider only three of the objects, namely the node object, the element object, and the document object. This is all we'll need to be able to create, amend, and navigate our tree structure. Also, we're not going to spend ages trawling through each of the properties and methods of these objects, but rather we'll pick some of the most useful properties and methods and use them to achieve specific ends. We'll start with two of the most useful methods of the document object itself.
Let's begin at the most basic level. We have our HTML web page, so how do we go about getting back a particular element on the page in script? We're going to ignore the way used in IE 4 and IE 5 (the document.all collection) and the NN4 way of doing this (for example, with the document.layers collection), and instead concentrate on the two cross-browser ways of doing this in IE 5.x and 6 and NN 6 and 7. (See the following table.)
|
Methods of the document Object |
Description |
|---|---|
|
getElementById(idvalue) |
Returns a reference (a node) to an element, when supplied with the value of the id attribute of that element |
|
getElementsByTagName(tagname) |
Returns a reference (a node list) to a set of elements that have the same tag as the one supplied in the argument |
The first of the two methods, getElementById(), requires us to ensure that every element we want to access in the page uses an id attribute, otherwise a null value (a word indicating a missing or unknown value) will be returned by our method. Let's go back to our first example and add some id attributes to our elements.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head><title>example</title></head> <body> <H1 id="Heading1">My Heading</H1> <P id="Paragraph1">This is some text in a paragraph</P> </body> </html>
Now we can use the getElementById() method to return a reference to any of the HTML elements with id attributes on our page. For example, if we add the following code, we can reference the <H1> element:
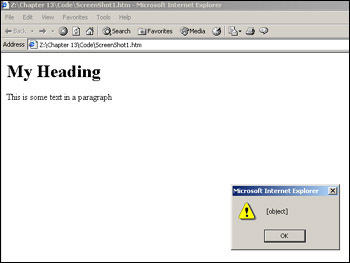
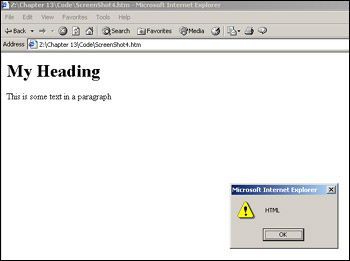
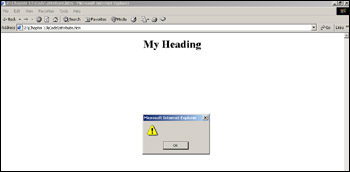
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>example</title> </head> <body> <H1 id="Heading1">My Heading</H1> <P id="Paragraph1">This is some text in a paragraph</P> <script language="Javascript" type="text/javascript"> alert(document.getElementById("Heading1")); </script> </body> </html>
This will display the page shown in Figure 13-4.
You might have been expecting it to return something along the lines of <H1> or <H1 id="Heading1">, but all it's actually returning is a reference to the <H1> element. This reference to the H1 element is more useful though, as we can use this to alter attributes of the <H1> element, such as to change the color or size. We can do this via the style object.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>example</title> </head> <body> <H1 id="Heading1">My Heading</H1> <P id="Paragraph1">This is some text in a paragraph</P> <script language="Javascript" type="text/javascript"> var H1Element = document.getElementById("Heading1"); H1Element.style.fontFamily = "Arial"; </script> </body> </html>
If we display this in the browser, we see that we can directly influence the attributes of the <H1> element in script, as we have done here by changing its font type to Arial. (See Figure 13-5.)
The second of the two methods, getElementsByTagName(), works in the same way, but, as its name implies, it can return more than one element. If we were to go back to our second example with the table and use this method to return the table cells <TD> in our code, we would get a total of four table cells returned to our object. We'd still have only one object returned, but this object would be a collection of elements. To reference a particular element in the collection, we would have to be more precise. We need to specify an index number, which we do using the item() method.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>This is a test page</title> </head> <body> <span>Below is a table... </span> <table border=1> <TR> <TD>Row 1 Cell 1</TD> <TD>Row 1 Cell 2</TD> </TR> <TR> <TD>Row 2 Cell 1</TD> <TD>Row 2 Cell 2</TD> </TR> </table> <script language="Javascript" type="text/javascript"> var TDElement = document.getElementsByTagName("TD").item(0); TDElement .style.fontFamily = "arial"; </script> </body> </html>
Like arrays, collections are zero-based and so the first element in the table would correspond to the index number zero. If we ran this example, once again using the style object, it would alter the style of the contents of the first table cell only in the table, as shown in Figure 13-6.
Once again, all of the attributes of each element are available to the DOM. We can use these to alter any aspect of the element, from presentation to the actual links contained. If we wanted to reference all of the cells in this way, we would have to mention each one explicitly in the code, and assign a new variable for each element as follows:
<script language="Javascript" type="text/javascript"> var TDElement0 = document.getElementsByTagName("TD").item(0); var TDElement1 = document.getElementsByTagName("TD").item(1); var TDElement2 = document.getElementsByTagName("TD").item(2); var TDElement3 = document.getElementsByTagName("TD").item(3); TDElement0.style.fontFamily = "arial"; TDElement1.style.fontFamily = "arial"; TDElement2.style.fontFamily = "arial"; TDElement3.style.fontFamily = "arial"; </script>
One thing to note about the getElementsByTagName() method is that it takes the element names within quotation marks and without the angle brackets <> that normally surround tags. The tag name should also be in uppercase.
One quick point to consider here is that in the previous set of examples we've used a feature that we introduced in the previous chapter under the heading of the Browser Object Model to access the style properties of an element, namely the style object. However, we're still using part of the DOM. This is a common point of confusion, because while the DOM is concerned with only the contents of the browser window, the BOM concerns itself with some features inside the browser window as well as the different parts of the actual browser. This overlap inside the browser window where both object models can be used is where things aren't quite so clear. This is due to the fact that browsers had object models for the contents of the document long before there were standards outlining them. Style is one major area where both browsers have supported changing style through scripting properties and methods, which is definitely part of the document, but currently still browser dependent.
Given this information, the style object (discussed in Chapter 12) might appear to be part of the Browser Object Model and not the Document Object Model because it is browser dependent. However, although the style object isn't addressed in level 1 of the DOM, it isn't because the style object is non-standard. The style object isn't covered in the standard because the first version of the standard wasn't able to address all things, and it left styles to the second level. They're not totally resolved there either, and it will probably be the third version before they get properly sorted. While being browser dependent, the style object actually works well in both browsers and supplies a very similar set of properties in IE 5.5 and 6 and NN 6 and 7, which is why we chose it for this example. We could also use the DOM method setAttribute() (which we will look at shortly) to set the style attributes, but this is a lot messier and currently works only in NN 6 and 7. Even NN 6 and 7 won't allow us to set the attribute to a variable name (as opposed to a text string).
We've now got a reference to individual elements on the page, but what about the tree structure we've discussed? The tree structure encompasses all of the elements and nodes on the page and gives them a hierarchical structure. If we want to reference that, we need a particular property of the document object that returns the outermost element of our document. In HTML, this should always be the <html> element. The property that does this is documentElement, as shown in the following table.
|
Property of the document Object |
Description |
|---|---|
|
documentElement |
Returns a reference to the outermost element of the document (the root element, for example <html>) |
We can use documentElement as follows. If we go back to our previous example code, we can transfer our entire DOM into one variable as follows:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>example</title>
</head>
<body>
<H1 id="Heading1">My Heading</H1>
<P id="Paragraph1">This is some text in a paragraph</P>
<script language="Javascript" type="text/javascript">
var Container = document.documentElement;
</script>
</body>
</html>
The variable Container now contains the root element, which is <html>. The documentElement property has returned a reference to this element in the form of an object, an Element object to be precise. The Element object has its own set of properties and methods. If we want to use them, we can refer to them by using the variable name, followed by the method or property name.
Container.elementobjectproperty
Fortunately, the Element object has only one property.
The property of the Element object is a reference to the tag name of the element, as shown in the following table.
|
Property of the Element Object |
Description |
|---|---|
|
tagName |
Can return the element tag name |
In our previous example the variable Container contained the <html> element, but using this property we can demonstrate that property. Add the following highlighted line, which makes use of the tagName property.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>example</title>
</head>
<body>
<H1 id="Heading1">My Heading</H1>
<P id="Paragraph1">This is some text in a paragraph</P>
<script language="Javascript" type="text/javascript">
var Container = document.documentElement;
alert(Container.tagName);
</script>
</body>
</html>
This code will now return proof that our variable Container holds the outermost element, and by implication all other elements within. (See Figure 13-7.)
Now that we can return any individual element, and the root element, we can look at how we can start navigating our tree structure.
We now have our element or elements from the web page, but what happens if we want to move through our page systematically, from element to element, or from attribute to attribute? This is where we need to step back to a higher level. To move between elements, attributes, and text, we have to move between nodes in our tree structure. It doesn't matter what is contained within the node, or rather, what sort of node it is. This is why we need to go back to one of the objects we called base objects. Our whole tree structure is made up of these base-level Node objects.
Following is a list of some common properties of the Node object that provide information about the node, whether it is an element, attribute, or text, and allow us to move from one node to another.
|
Properties of the Node Object |
Description of Property |
|---|---|
|
firstChild |
Returns the first child node of an element |
|
lastChild |
Returns the last child node of an element |
|
previousSibling |
Returns the previous child node of an element at the same level as the current child node |
|
nextSibling |
Returns the next child node of an element at the same level as the current child node |
|
ownerDocument |
Returns the root node of the document that contains the node. Note this is not available in IE 5 or 5.5. |
|
parentNode |
Returns the element that contains the current node in the tree structure |
|
nodeName |
Returns the name of the node |
|
nodeType |
Returns the type of the node as a number |
|
nodeValue |
Sets the value of the node in plain text format |
Let's take a quick look at how some of these properties work. Consider once more our first example.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>example</title>
</head>
<body>
<H1 id="Heading1">My Heading</H1>
<P id="Paragraph1">This is some text in a paragraph</P>
<script language="Javascript" type="text/javascript">
var H1Element = document.getElementById("Heading1");
H1Element.style.fontFamily = "Arial";
</script>
</body>
</html>
We can now use H1Element to navigate our tree structure, access the contents of the text, and change it. Note that Netscape 6 and 7 insert blank text nodes and so this example won't work on Netscape 7. If we add the following lines, we are setting the reference in the variable PElement to the next element in the tree structure on the same level.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>example</title>
</head>
<body>
<H1 id="Heading1">My Heading</H1>
<P id="Paragraph1">This is some text in a paragraph</P>
<script language="Javascript" type="text/javascript">
var H1Element = document.getElementById("Heading1");
H1Element.style.fontFamily = "Arial";
var PElement = H1Element.nextSibling;
PElement.style.fontFamily = "Arial";
</script>
</body>
</html>
In effect, we are navigating through the tree structure as shown in Figure 13-8.
The same principles also work in reverse. We can go back and add yet more code that navigates back to the previous node and changes the text of our previous element to our example.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
</head>
<body>
<H1 id="Heading1">My Heading</H1>
<P id="Paragraph1">This is some text in a paragraph</P>
<script language="Javascript" type="text/javascript">
var H1Element = document.getElementById("Heading1");
H1Element.style.fontFamily = "Arial";
var PElement = H1Element.nextSibling;
PElement.style.fontFamily = "Arial";
H1Element = PElement.previousSibling;
H1Element.style.fontFamily = "Courier";
</script>
</body>
</html>
What we're doing here is setting the first <H1> element to the font Arial; we're then navigating across to the next sibling, which is the next child node of our <body> element. The first child is the <H1> element; the second one is the <P> element. Note that with Mozilla things are different; there are lots of white space text nodes as child nodes in the body between the element nodes.
We set the font to Arial here as well. Our new two lines of code then use the previousSibling property to jump back to our <H1> element, and then we again change the fontFamily style, but this time we change it to Courier. So the sum effect of our program is to change the <H1> element to Courier, and the <P> element to Arial.
I've now got a confession to make. Up until now we've been cheating, because we haven't truly navigated our HTML document. We've just used document.getElementById() to return an element and navigated to different nodes from there. Now let's use the documentElement property of the document object and do this properly. We'll start at the top of our tree and move down through the child nodes to get at those elements; then we'll navigate through our child nodes and change the properties the same way as before.
Type the following into your text editor:
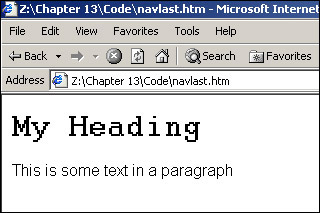
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>example</title> </head> <body> <H1 id="Heading1">My Heading</H1> <P id="Paragraph1">This is some text in a paragraph</P> <script language="Javascript"> var htmlElement; // htmlElement stores reference to <html> var HeadingElement; // HeadingElement stores reference to <head> var BodyElement; // BodyElement stores refrence to <body> var H1Element; // H1Element stores reference to <H1> var PElement; // PElement stores reference to <P> htmlElement = document.documentElement; HeadingElement = htmlElement.firstChild; alert(HeadingElement.tagName); if(HeadingElement.nextSibling.nodeType==3) { BodyElement = HeadingElement.nextSibling.nextSibling; } else { BodyElement = HeadingElement.nextSibling; } alert(BodyElement.tagName); if(BodyElement.firstChild.nodeType==3) { H1Element = BodyElement.firstChild.nextSibling; } else { H1Element = BodyElement.firstChild; } alert(H1Element.tagName); H1Element.style.fontFamily = "Arial"; if(H1Element.nextSibling.nodeType==3) { PElement = H1Element.nextSibling.nextSibling; } else { PElement = H1Element.nextSibling; } alert(PElement.tagName); PElement.style.fontFamily = "Arial"; if(PElement.previousSibling.nodeType==3) { H1Element = PElement.previousSibling.previousSibling } else { H1Element = PElement.previousSibling } H1Element.style.fontFamily = "Courier" </script> </body> </html>
Save this as navlast.htm. Then open the page in your browser, clicking on OK in each of the message boxes until you see the page shown in Figure 13-9.
We've hopefully made this example very transparent by adding several alerts to demonstrate where we are along each section of the tree. We've also named the variables with their various different elements, to give a clearer idea of what is stored in each variable. We could just as easily have named them a, b, c, d, and e, so don't think we need to be bound by this naming convention.
We start at the top of the script block by retrieving our whole document using the documentElement property.
var htmlElement = document.documentElement;
The root element is the <html> element, hence the name of our first variable. Now if we refer to our tree, we'll see that the HTML element must have two child nodes: one containing the <head> element and the other containing the <body> element. We start by moving to the <head> element as follows:
var HeadingElement = htmlElement.firstChild;
We get there using the firstChild property of our Node object, which contains our <html> element. We use our first alert to demonstrate that this is true.
alert(HeadingElement.tagName);
Our <body> element is our next sibling across from the <head> element, so we navigate across by creating a variable that is the next sibling from the <head> element.
if(HeadingElement.nextSibling.nodeType==3) { BodyElement = HeadingElement.nextSibling.nextSibling; } else { BodyElement = HeadingElement.nextSibling; } alert(BodyElement.tagName);
Here we check to see what the nodeType of the nextSibling of HeadingElement is. If it returns 3, we set BodyElement to be the nextSibling of the nextSibling of HeadingElement; otherwise we just set it to the nextSibling of HeadingElement. Why do we do this? The answer lies with the implementation of the DOM in NN 6. We would think that the next sibling of the <head> element in the tree would be the <body> element, and indeed it is in IE 5.5 and 6. However, because of the way Netscape has interpreted the DOM, NN 6 and 7 add text nodes to every element in the tree as long as there is at least white space, regardless of whether or not the element contains text. This is explained more fully later in the chapter. To navigate through the tree in a way that works in IE and NN, we check to see whether the next sibling has a nodeType of 3. If it does, it is a text node, and we need to move along the next node.
We use an alert to prove that we are now at the <body> element.
alert(BodyElement.tagName);
The <body> element in this page also has two children, the <H1> and <P> elements. Using the firstChild property, we move down to the <H1> element. Again we check for the extra text node that NN might have added. We use an alert again to show that we have arrived at <H1>.
if(BodyElement.firstChild.nodeType==3) { H1Element = BodyElement.firstChild.nextSibling; } else { H1Element = BodyElement.firstChild; } alert(H1Element.tagName);
After the third alert, the style will be altered on our first element, changing the font to Arial.
H1Element.style.fontFamily = "Arial";
We then navigate across to the <P> element using the nextSibling property, again checking for the extra text node.
if(H1Element.nextSibling.nodeType==3) { PElement = H1Element.nextSibling.nextSibling; } else { PElement = H1Element.nextSibling; } alert(PElement.tagName);
We change the <P> element's font to Arial also.
PElement.style.fontFamily = "Arial";
Finally, we use the previousSibling property to move back in our tree to the <H1> element and this time change the font to Courier.
if(PElement.previousSibling.nodeType==3) { H1Element = PElement.previousSibling.previousSibling } else { H1Element = PElement.previousSibling } H1Element.style.fontFamily = "Courier"
This is a fairly easy example to follow because we're using the same tree structure we created with diagrams, but it does show how the DOM effectively creates this hierarchy and that we can move around using script within this hierarchy.
We can now move through our tree structure and alter the contents of elements as we go, but we still can't fundamentally alter the structure of our HTML document. Help is at hand, though, because the Node object's methods let us do this.
Following is a list of methods that allow us to alter the structure of an HTML document by creating new nodes and adding them to our tree.
|
Methods of the Node Objects |
Description |
|---|---|
|
appendChild(new node) |
Adds a new node object to the end of the list of child nodes |
|
cloneNode(child option) |
Creates a new node object that is identical to the node object supplied as an argument, optionally including all of the child nodes |
|
hasChildNodes() |
Returns true if a node has any child nodes |
|
insertBefore(new node, current node) |
Inserts a new node object into the list of child nodes before the node stipulated in current node |
|
removeChild(child node) |
Removes a child node from a list of child nodes of the node object |
|
replaceChild(new child, old child) |
Replaces an old child node object with a new child node object |
We'll look at how they work shortly.
In addition to the methods of the Node object listed previously, the document object itself boasts some methods for creating elements, attributes, and text, shown in the following table.
|
Methods of the document Object |
Description |
|---|---|
|
createElement(element name) |
Creates an element node with a specified name |
|
createTextNode(text) |
Creates a text node with the specified text |
|
createAttribute(attribute name) |
Creates an attribute node with a specified name. Note this is not supported by IE 5.x |
The best way to demonstrate both sets of methods for the Node object and the document object at one time is with an example.
We'll create a web page with just a paragraph <P> and heading <H1> element, but instead of HTML we'll use the DOM properties and methods to place these elements on the web page. Figure 13-10 shows IE. However, we don't have to make any changes for the example to work equally well in NN 6. Let's start up our preferred text editor and type in the following:
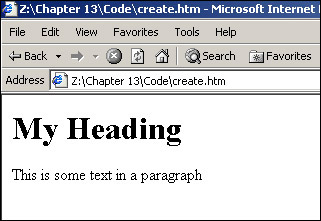
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>example</title> </head><body> <script language=JavaScript type="text/javascript"> var newText; var newElem; newText = document.createTextNode("My Heading") newElem = document.createElement("H1") newElem.appendChild(newText) document.body.appendChild(newElem) newText = document.createTextNode("This is some text in a paragraph") newElem = document.createElement("P") newElem.appendChild(newText) document.body.appendChild(newElem) </script> </body> </html>
Save this page as create.htm and open it in a browser.
It all looks a bit dull and ordinary doesn't it? And yes, we could have done this much more simply with HTML. That isn't the point though. The idea is that we use DOM properties and methods, accessed with JavaScript, to insert these features. The first two lines of the script block are just used to define the variables in our script, which will hold the text we want to insert into the page and the HTML element we wish to insert.
var newText; var newElem;
We start at the bottom of our tree first, by creating a text node with the createTextNode() method.
newText = document.createTextNode("My Heading")
We then use the createElement() method to create an HTML heading.
newElem = document.createElement("H1")
At this point the two variables are entirely separate from each other. We have a text node, and we have an <H1> element, but they're not connected. The next line allows us to attach the text node to our HTML element. We reference the HTML element we have created with the variable name newElem, use the appendChild() method of our node, and supply the contents of the newText variable we created earlier as a parameter.
newElem.appendChild(newText);
Let's recap. We created a text node and stored it in the newText variable. We created an <H1> element and stored it in the newElem variable. Then we appended the text node as a child node to the <H1> element. That still leaves us with a problem: We've created an element with a value, but it isn't part of our document. We need to attach the entirety of what we've created so far to the document body. We can do this again with the appendChild() method, but this time supply it to the document.body object.
document.body.appendChild(newElem)
This completes the first part of our code. Now all we have to do is repeat the process for the <P> element.
newText = document.createTextNode("This is some text in a paragraph") newElem = document.createElement("P") newElem.appendChild(newText) document.body.appendChild(newElem)
We create a text node first; then we create an element. We attach the text to the element, and finally we attach the element and text to the body of the document. This completes our creation of parts of the HTML document in script.
We've now created elements and changed text, but we've left out one of the important parts of the web page, namely attributes. We'll look at how we use attributes now.
Although it is still acceptable to set the style attributes through the style object, if we want to set any other element attributes, we should use the DOM-specific methods of the Element object.
The three methods we can use to return and alter the contents of an HTML element's attributes are getAttribute(), setAttribute(), and removeAttribute(), as shown in the following table.
|
Methods of the Element Object |
Description |
|---|---|
|
getAttribute(attribute name) |
Returns the value of an attribute |
|
setAttribute(attribute name, value) |
Sets the value of an attribute |
|
removeAttribute(attribute name) |
Removes the value of an attribute and replaces it with the default value |
Let's take a quick look at how these methods work now. In the previous example, createElement() and createTextNode() were used to add HTML elements and text to our page, but we didn't actually make use of createAttribute(), which is IE6 only. That's because there's a much easier method of creating attributes: using the setAttribute() and getAttribute() methods.
We're now going to take our previous example and add some attributes to it that will affect the presentation and layout of our text. We must be sure to replicate the case of these lines when we type them because incorrect case will prevent the example from working correctly.
Open create.htm in a text editor and add the following highlighted lines:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>example</title>
</head>
<body>
<script language=JavaScript type="text/javascript">
var newText;
var newElem;
newText = document.createTextNode("My Heading")
newElem = document.createElement("H1")
newElem.setAttribute("align","center")
newElem.appendChild(newText)
document.body.appendChild(newElem)
newText = document.createTextNode("This is some text in a paragraph")
newElem = document.createElement("P")
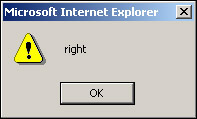
alert(newElem.getAttribute("align"))
newElem.setAttribute("align","right")
alert(newElem.getAttribute("align"))
newElem.appendChild(newText)
document.body.appendChild(newElem)
</script>
</body>
</html>
Save this as attribute.htm and open it in a browser. Our page will look like Figure 13-11.
Click OK on the alert, and the second time it should display correctly. (See Figure 13-12.)
Click OK again to reach the screen shown in Figure 13-13.
We've added four lines of code here to augment our existing document structure. The first takes our <H1> element and adds an align attribute to it.
newText = document.createTextNode("My Heading")
newElem = document.createElement("H1")
newElem.setAttribute("align","center")
Note that in the setAttribute() method, align is in lowercase per the XHTML standards recommended earlier in this chapter. If it were in uppercase, as follows, the example would fail in some browsers such as IE.
newElem.setAttribute("ALIGN","center")
The setAttribute() method takes any existing attribute, align (by existing attribute, I mean one that is specified for that particular element in the HTML specifications), and supplies it the value center. The result positions our text in the center of the page.
| Note |
Strictly speaking, the align attribute is deprecated under XHTML, but we have used it because it works and it has one of the easily demonstrable visual effects on a web page. |
So setAttribute() takes the name of the attribute first and the value second. If we set the attribute name to be a nonexistent attribute, it will have no effect on the page. You can also set the attribute to a nonexistent value, which is perfectly legal, but once again will have no effect on the page.
The second part of the code is very similar to the first.
newText = document.createTextNode("This is some text in a paragraph")
newElem = document.createElement("P")
alert(newElem.getAttribute("align"))
newElem.setAttribute("align","right")
alert(newElem.getAttribute("align"))
Once we've created our <P> element and the accompanying text, we use getAttribute() to return the value of the align attribute. Because align hasn't been set yet, it returns no value, not even the default. We then use the setAttribute() method to set the align attribute to right, and use getAttribute() to return the value. This time it returns right. This is then reflected in the final display of the web page.
What have we seen so far? We started with a nearly empty DOM hierarchy. We then returned the HTML document to a variable, navigated through the different parts of it via DOM objects outside the hierarchy itself (the Node objects), and changed the contents of objects, thus altering the content of the web page. Then we inserted DOM objects into the hierarchy, thus inserting new elements onto the page. This leaves just one area to cover in the DOM: the event model.
The DOM event model is introduced in level 2 of the DOM standard. It's a way of handling events and providing information about these events to the script. It provides guidelines for a standard way of determining what generated an event, what type of event it was, where the event occurred, and at what time.
All of this was, of course, trackable in IE 4, and to a lesser extent in NN 4, through the event object as we saw in the last chapter. However, the main problem was that the ways of accessing this object and the names of its properties were completely different between the two browsers.
The DOM event model doesn't look complete in some ways and might yet be tweaked in level 3 of the standard, but what it does do is introduce a basic set of objects, properties, and methods. It also makes some important distinctions.
First there is an event object, which provides information about the element that has generated an event and allows you to retrieve it in script. To make it available in script, it must be passed as a parameter to the function connected to the event handler, as we saw with NN 4.x in the previous chapter. It is not globally available, as the IE event object was/is.
The standard outlines several properties and methods of the event object that have long since been a source of dispute between IE and NN. We will only be using the properties, so we will just be considering them here.
|
Properties of the event Object |
Description |
|---|---|
|
bubbles |
Indicates whether an event can bubble (pass control from one element to another) |
|
cancelable |
Indicates whether an event can have its default action canceled |
|
currentTarget |
Indicates which event is currently being processed |
|
eventPhase |
Indicates which phase of the event flow an event is in |
|
target (Netscape Navigator 6 and 7 only) |
Indicates which element caused the event; in the DOM event model, text nodes are the possible target of an event |
|
timeStamp (Netscape Navigator 6 and 7 only) |
Indicates at what time the event occurred |
|
type |
Indicates the name of the event |
Secondly, the DOM introduces a mouse event object, which deals with events generated specifically by the mouse. This is introduced because we might need more specific information about the event, such as the position in pixels of the cursor, or the element the mouse has come from.
|
Properties of the mouse Event Object |
Description |
|---|---|
|
altKey |
Indicates whether the Alt key was pressed when the event was generated |
|
button |
Indicates which button on the mouse was pressed |
|
clientX |
Indicates where in the browser window, in horizontal coordinates, the mouse pointer was when the event was generated |
|
clientY |
Indicates where in the browser window, in vertical coordinates, the mouse pointer was when the event was generated |
|
ctrlKey |
Indicates whether the Ctrl key was pressed when the event was generated |
|
metaKey |
Indicates whether the meta key was pressed when the event was generated |
|
relatedTarget (Netscape Navigator 6 and 7 only) |
In the DOM event model text nodes are the (possible) target of the mouseover event. This is similar to IE's event.toElement and event.fromElement. |
|
screenX |
Indicates where in the browser window, in horizontal coordinates relative to the origin in the screen coordinates, the mouse pointer was when the event was generated |
|
screenY |
Indicates where in the browser window, in vertical coordinates relative to the origin in the screen coordinates, the mouse pointer was when the event was generated |
|
shiftKey |
Indicates whether the Shift key was pressed when the event was generated |
While any event might create an event object, only a select set of events can generate a mouse object. On the occurrence of a mouse event, we'd be able to access properties from the event object and the mouse object. With a non-mouse event, none of the mouse object properties in the preceding table would be available. The following mouse events can create a mouse event object:
click occurs when a mouse button is clicked (pressed and released) with the pointer over an element or text
mousedown occurs when a mouse button is pressed with the pointer over an element or text
mouseup occurs when a mouse button is released with the pointer over an element or text
mouseover occurs when a mouse button is moved onto an element or text
mousemove occurs when a mouse button is moved and it is already on top of an element or text
mouseout occurs when a mouse button is moved out and away from an element or text
To get at an event using the DOM, all we have to do is query the event object that is created by the individual element that has raised the event. For example, in the following code the <P> element will raise a ondblclick event.
<P ondblclick="handlekey(event)">Paragraph</P> <script language="JavaScript" type="text/javascript"> function handlekey(e) { alert(e.type); } </script>
We have to pass the event object that is created by the <P> element as an argument in the function call to be able to use it within the function. We can then use the parameter passed as the event object and use its general properties made available through the DOM.
However, this is where the browsers get shaky. IE 5.5 doesn't support a lot of the DOM properties mentioned in the table. IE 6 provides slightly better support, although the type property is supported by both browser versions. Instead, IE 5.5 has its own set of IE-specific properties, which we won't be discussing in a chapter on the DOM.
If we ran the previous example, it would just tell us what kind of event raised our event-handling function. This might seem self-evident in the preceding example, but if we had included the following extra lines of code, any one of three elements could have raised the function.
<P ondblclick="handlekey(event)">Paragraph</P> <H1 onclick="handle(event)">Heading 1</H1> <span onmouseover="handle(event)">Special Text</span> <script language="JavaScript" type="text/javascript"> function handlekey(e) { alert(e.type); } </script>
This makes the code much more useful. In general we will use relatively few event handlers to deal with any number of events, and we can use the event properties as a filter to determine what type of event happened and what HTML element triggered it, so that we can treat each event differently.
In the following example, we see that depending on what type of event was returned, we could take a different course of action.
<P ondblclick="handlekey(event)">Paragraph</P>
<H1 onclick="handlekey(event)">Heading 1</H1>
<span onmouseover="handlekey(event)">Special Text</span>
...
<script language="JavaScript">
function handlekey(e)
{
if (e.type == "mouseover")
{
alert("You moved over the Special Text");
}
}
</script>
Let's take a quick look at an example that creates a mouse event object when the user clicks anywhere on the screen and returns to the user the x and y coordinates of the position of the mouse pointer when the mouse button was clicked. (See Figure 13-14.) This example will work in IE 5+ and NN 6 and 7 browsers.
Open a text editor and type in the following:
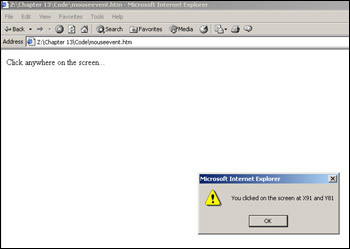
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>example</title> </head> <body onclick="handleClick(event)"> Click anywhere on the window... <script language="JavaScript" type="text/javascript"> function handleClick(e) { alert("You clicked on the screen at X" + e.clientX +" and Y" + e.clientY); } </script> </body> </html>
Save this as mouseevent.htm and run it in your browser.
Now click OK, move the pointer in the browser window, and click again. A different result appears.
This example is consistent with the event-handling behavior; the browser waits for an event, and every time a specific event occurs, it will raise the corresponding function. It will continue to wait for the event until we exit the browser or that particular web page. In this example, we use the <body> element to raise a click event.
<body onclick="handleClick(event)">
Whenever that function is encountered, the handleClick() function is raised and a new mouse event object is generated. Remember that mouse event objects give us access to event object properties as well as mouse event object properties, even though we don't use them in this example.
The function takes the mouse event object and assigns it the reference e.
function handleClick(e) { alert("You clicked on the screen at X" + e.clientX +" and Y" + e.clientY); }
Inside the function, we use the alert() statement to display the contents of the clientX and clientY properties of the mouse event object on the screen. This mouse event object is overwritten and re-created every time we generate an event, so the next time we click the mouse pointer, it returns new coordinates for the X and Y positions.
As described earlier, one problem that precludes greater discussion of the DOM event model is the fact that not all browsers support it in any detail, specifically the most popular by far browser, IE, doesn't fully support it. We will see in a later example that we are still in a position of having to dual-code for both browsers when it comes to returning information about events via properties, but this should provide a little taste for how they work, and how they will work in future browsers. We won't go into any further detail here about events, but we will be returning to the DOM event object model in an example that discusses how to cross-code for both browsers later in the chapter. In fact, let's get down to the crux of the matter right now, using the DOM to create web pages that work in both browsers.
JavaScript Validator
JavaScript Editor