JavaScript Validator
JavaScript Editor
JavaScript Validator
JavaScript Editor
The main functions making use of regular expressions are the String object's split(), replace(), search() and match() methods. We've already seen their syntax, so we'll concentrate on their use with regular expressions and at the same time learn more about regular expression syntax and usage.
We've seen that the split() method allows us to split a string into various pieces with the split being made at the character or characters specified as a parameter. The result of this method is an array with each element containing one of the split pieces. For example, the following string
var myListString = "apple, banana, peach, orange"
could be split into an array where each element contains a different fruit using
var myFruitArray = myListString.split(", ");
How about if our string was instead
var myListString = "apple, 0.99, banana, 0.50, peach, 0.25, orange, 0.75";
This could, for example, contain both the names and prices of the fruit. How could we split the string, but just retrieve the names of the fruit and not the prices? We could do it without regular expressions, but it would take a number of lines of code. With regular expressions we can use the same code, and just amend the split() method's parameter.
Let's create an example that solves the problem just described—it must split our string, but only include the fruit names, not the prices.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <body> <script language="JavaScript" type="text/JavaScript"> var myListString = "apple, 0.99, banana, 0.50, peach, 0.25, orange, 0.75"; var theRegExp = /[^a-z]+/i; var myFruitArray = myListString.split(theRegExp); document.write(myFruitArray.join("<br>")); </script> </body> </html>
Save the file as ch8_examp3.htm and load it in your browser. You should see the four fruits from our string written out to the page with each fruit on a separate line.
Within the script block, first we have our string with fruit names and prices.
var myListString = "apple, 0.99, banana, 0.50, peach, 0.25, orange, 0.75";
How do we split that in such a way that only the fruit names are included? Our first thought might be to use the comma as the split() method's parameter, but of course that means we end up with the prices. What we have to ask ourselves is, "What is it that's between the items we want?" Or in other words, what is between the fruit names that we can use to define our split? The answer is that various characters are between the fruit, such as a comma, a space, numbers, a full stop, more numbers, and finally another comma. What is it that these things have in common and makes them different from the fruit names that we want? What they have in common is that none of them are the letters from a through z. If we say split the string at the point where there is a group of characters that are not between a and z, then we get the result we want. Now we know what we need to create our regular expression.
We know that what we want is not the letters a through z, so we start with this:
[^a-z]
The ^ says "match any character that does not match those specified inside the square brackets." In this case we've specified a range of characters to not to be matched, all those characters between a and z. As specified, this will only match one character, whereas we want to split wherever there is a single group of one or more characters that are not between a and z. To do this we need to add the + special repetition character, which says "match one or more of the preceding character or group specified."
[^a-z]+
Our final result is this:
var theRegExp = /[^a-z]+/i
The / and / characters mark the start and end of the regular expression whose RegExp object is stored as a reference in variable theregExp. We add the i on the end to make the match case-insensitive.
Don't panic if creating regular expressions seems a frustrating and less than obvious process. At first, it takes a lot of trial-and-error to get it right, but as you get more experienced, you'll find creating them becomes much easier and will enable you to do things that without regular expressions would be either very long-winded or virtually impossible.
In the next line of script, we pass the RegExp object to the split() method, which uses it to decide where to split the string.
var myFruitArray = myListString.split(theRegExp);
After the split, the variable myFruitArray will contain an Array with each element containing the fruit name as shown here:
|
Array Element Index |
0 |
1 |
2 |
3 |
|---|---|---|---|---|
|
Element Value |
apple |
banana |
peach |
orange |
We then join the string together again using the Array object's join() methods, which we saw in Chapter 4.
document.write(myFruitArray.join("<BR>"))
We've already looked at the syntax and usage of the replace() method. However, something unique to the replace() method is its ability to replace text based on the groups matched in the regular expression. We do this using the $ sign and the group's number. Each group in a regular expression is given a number from 1 to 99; any groups greater than 99 are not accessible. Note that in earlier browsers, groups could only go from 1 to 9 (for example, in IE 5 or earlier or Netscape 4 and earlier). To refer to a group, we write $ followed by the group's position. For example, if we had the following:
var myRegExp = /(\d)(\W)/g;
then $1 refers to the group(\d), and $2 refers to the group (\W). We've also set the global flag g to ensure all matching patterns are replaced—not just the first one.
You can see this more clearly in the next example. If we had a string defined as
var myString = "1999, 2000, 2001";
and we wanted to change this to "the year 1999, the year 2000, the year 2001", how could we do this with regular expressions?
First we need to work out the pattern as a regular expression, in this case four digits.
var myRegExp = /\d{4}/g;
But given that the year is different every time, how can we substitute the year value into the replaced string?
Well, we change our regular expression, so that it's inside a group as follows:
var myRegExp = /(\d{4})/g;
Now we can use the group, which has group number 1, inside the replacement string like this:
myString = myString.replace(myRegExp, "the year $1");
The variable myString would then contain the required string "the year 1999, the year 2000, the year 2001".
Let's look at another example in which we want to convert single quotes in text to double quotes. Our test string is
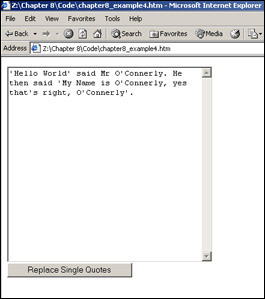
'Hello World' said Mr O'Connerly. He then said 'My Name is O'Connerly, yes that's right, O'Connerly'.
One problem that the test string makes clear is that we only want to replace the single quote mark with a double where it is used in pairs around speech, not when acting as an apostrophe, such as in the word that's, or when part of someone's name, such as in O'Connerly.
Let's start by defining our regular expression. First we know that it must include a single quote as shown in the following:
var myRegExp = /'/;
However, as it is this would replace every single quote, which is not what we want.
Looking at the text, something else we notice is that quotes are always at the start or end of a word, that is, they are at a boundary. On first glance it might be easy to assume that it would be a word boundary. However don't forget that the ' is a non-word character so the boundary will be between it and another non-word character, such as a space. So the boundary will be a non-word boundary, or in other words, \B.
Therefore, the character pattern we are looking for is either a non-word boundary followed by a single quote, or a single quote followed by a non-word boundary. The key is the "or," for which we use | in regular expressions. This leaves our regular expression as
var myRegExp = /\B'|'\B/g;
This will match the pattern on the left of the | or the character pattern on the right. We want to replace all the single quotes with double quotes, so the g has been added at the end indicating a global match should take place.
Let's look at an example using the regular expression just defined.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>example</title> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <script language="JavaScript" type="text/JavaScript"> function replaceQuote(textAreaControl) { var myText = textAreaControl.value; var myRegExp = /\B'|'\B/g; myText = myText.replace(myRegExp,'"'); textAreaControl.value = myText; } </script> </head> <body> <form name=form1> <textarea rows=20 cols=40 name=textarea1 wrap=hard> 'Hello World' said Mr O'Connerly. He then said 'My Name is O'Connerly, yes that's right, O'Connerly'. </textarea> <br> <input type="button" VALUE="Replace Single Quotes" name=buttonSplit onclick="replaceQuote(document.form1.textarea1)"> </form> </body> </html>
Save the page as ch8_examp4.htm. Load the page into your browser as shown in Figure 8-10.
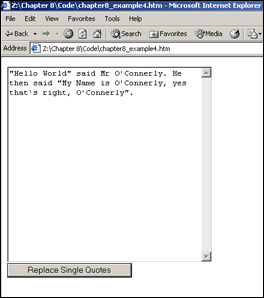
Click the Replace Single Quotes button to see the single quotes in the textarea replaced as shown in Figure 8-11.
Try entering your own text with single quotes into the textarea and check the results.
You can see that by using regular expressions, we have completed a task in a couple of lines of simple code. Without regular expressions, it would probably take four or five times that amount.
Let's look first at the replaceQuote() function in the head of the page where all the action is.
function replaceQuote(textAreaControl) { var myText = textAreaControl.value; var myRegExp = /\B'|'\B/g; myText = myText.replace(myRegExp,'"'); textAreaControl.value = myText; }
The function's parameter is the textarea object defined further down the page—this is the textarea where we want to replace the single quotes. We can see how the textarea object was passed in the button's tag definition.
<input type="button" value="Replace Single Quotes" name=buttonSplit onclick="replaceQuote(document.form1.textarea1)">
In the onclick event handler, we call replaceQuote() and pass document.form1.textarea1 as the parameter—that is the textarea object.
Returning to the function, we get the value of the textarea on the first line and place it in the variable myText. Then we define our regular expression as we discussed previously, which matches any non-word boundary followed by a single quote or any single quote followed by a non-word boundary. For example, 'H will match, as will H', but O'R won't because the quote is between two word boundaries. Don't forget that a word boundary is the position between the start or end of a word and a non-word character, such as a space or punctuation mark.
In the function's final two lines, we first use the replace() method to do the character pattern search and replace, and finally we set the textarea object's value to the changed string.
The search() method allows you to search a string for a pattern of characters. If the pattern is found, the character position at which it was found is returned, otherwise –1 is returned. The method takes only one parameter, the RegExp object you have created.
While for basic searches the indexOf() method is fine, if you want more complex searches, such as a pattern of any digits or where a word must be in between a certain boundary, then search() provides a much more powerful and flexible, but sometimes more complex, approach.
In the following example, we want to find out if the word Java is contained within the string. However, we want to look just for Java as a whole word, not when it's within another word, such as JavaScript.
var myString = "Beginning JavaScript, Beginning Java 2, Professional JavaScript"; var myRegExp = /\bJava\b/i; alert(myString.search(myRegExp));
First we have defined our string, and then we've created our regular expression. We want to find the character pattern Java when it's on its own between two word boundaries. We've made our search case-insensitive by adding the i after the regular expression. Note that with the search() method, the g for global is not relevant, and its use has no effect.
On the final line we output the position where the search has located the pattern, in this case 32.
The match() method is very similar to the search() method, except that instead of returning the position where a match was found, it returns an array. Each element of the array contains the text of a match made.
For example, if we had the string
var myString = "The years were 1999, 2000 and 2001";
and wanted to extract the years from this string, we could do so using the match() method. To match each year, we are looking for four digits in between word boundaries. This requirement translates to the following regular expression:
var myRegExp = /\b\d{4}\b/g;
We want to match all the years so the g has been added to the end for a global search.
To do the match and store the results, we use the match() method and store the Array object it returns in a variable.
var resultsArray = myString.match(myRegExp);
To prove it has worked, let's use some code to output each item in the array. We've added an if statement to double-check that the results array actually contains an array. If no matches were made, the results array will contain null—doing if (resultsArray) will return true if the variable has a value and not null.
if (resultsArray) { var indexCounter; for (indexCounter = 0; indexCounter < resultsArray.length; indexCounter++) { alert(resultsArray[indexCounter]); } }
This would result in three alert boxes containing the numbers 1999, 2000, and 2001.
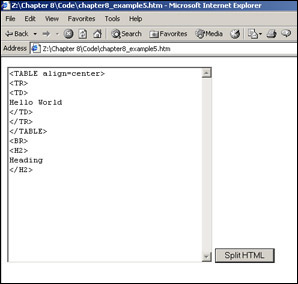
In the next example, we want to take a string of HTML and split it into its component parts. For example, we want the HTML <P>Hello</P> to become an array, with the elements having the following contents:
|
<P> |
Hello |
</P> |
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>example</title> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <script language="JavaScript" type="text/JavaScript"> function button1_onclick() { var myString = "<table align=center><tr><td>" myString = myString + "Hello World</td></tr></table>" myString = myString +"<br><h2>Heading</h2>"; var myRegExp = /<[^>\r\n]+>|[^<>\r\n]+/g var resultsArray = myString.match(myRegExp); document.form1.textarea1.value = ""; document.form1.textarea1.value = resultsArray.join ("\r\n"); } </script> </head> <body> <form name=form1> <textarea rows=20 cols=40 name=textarea1></textarea> <input type="button" value="Split HTML" name=button1 onclick="return button1_onclick()"> </form> </body> </html>
Save this file as ch8_examp5.htm. When you load the page into your browser and click the Split HTML button, a string of HTML is split, and each tag is placed on a separate line in the textarea, as shown in Figure 8-12.
The function button1_onclick() defined at the top of the page fires when the Split HTML button is clicked. At the top, the following lines
function button1_onclick() { var myString = "<table align=center><tr><td>"; myString = myString + "Hello World</td></tr></table>"; myString = myString +"<br><h2>Heading</h2>";
define our string of HTML that we want to split.
Next we create our RegExp object and initialize it to our regular expression.
var myRegExp = /<[^>\r\n]+>|[^<>\r\n]+/g
Let's break it down to see what pattern we're trying to match. First note that the pattern is broken up by an alternation symbol: |. This means that we want the pattern on the left or the right of this symbol. We'll look at these patterns separately. On the left we have the following:
The pattern must start with a <.
In [^>\r\n]+, we specify that we want one or more of any character except the > or a \r (carriage return) or a \n (linefeed).
> specifies that the pattern must end with a >.
On the right, we have only the following:
[^<>\r\n]+ specifies that the pattern is one or more of any character, so long as that character is not a <, >, \r, or \n. This will match plain text.
After the regular expression definition we have a g, which specifies that this is a global match.
So the <[^>\r\n]+> regular expression will match any start or close tags, such as <p> or </p>. The alternative pattern is [^<>\r\n]+, which will match any character pattern that is not an opening or closing tag.
In the following line
var resultsArray = myString.match(myRegExp);
we assign the resultsArray variable to the Array object returned by the match() method.
The remainder of the code deals with populating the textarea with the split HTML. We use the Array object's join() method to join all the array's elements into one string with each element separated by a "\r\n" character, so that each tag or piece of text goes on a separate line as shown in the following:
document.form1.textarea1.value = ""; document.form1.textarea1.value = resultsArray.join("\r\n"); }
JavaScript Validator
JavaScript Editor