JavaScript Debugger
JavaScript Editor
JavaScript Debugger
JavaScript Editor
Communicating something from the browser to the server without a round trip is a useful technique, but much more can be accomplished if JavaScript can also receive a return value. In this section, we cover a number of ways to implement two-way communication (true RPC), from the primitive to the mature. The techniques we discuss are not, however, the only mechanism by which to do RPC. You could use JavaScript to pull in other kinds of dynamic content, to control a Java applet that talks to the server, to drive an ActiveX control that handles networking, or to leverage proprietary browser enhancements such as IE’s data source features.
Since the height and width properties of an Image are automatically filled in by the browser once an image has been downloaded, your server can return images of varying dimensions to communicate messages to your JavaScript. For example, your site might have Java-based chat functionality that users can fire up if their friends are also currently browsing your site. Since you probably wouldn’t want to start the Java applet unless the user knows there’s someone to talk to, you might use JavaScript to quickly inquire to the server about who is online. JavaScript can issue an RPC to the server via an Image object inquiring if a particular user is currently available. If someone is, the server could return an image with a 1-pixel height. If not, the server could return an image with a 2-pixel height.
Here’s an example of the technique:
<<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">>
<<html xmlns="http://www.w3.org/1999/xhtml">>
<<head>>
<<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />>
<<title>>User Online Demo<</title>>
<</head>>
<<body>>
<<script type="text/javascript">>
var commandURL = "http://demos.javascriptref.com/isuseronline.php?";
// Since requests don't necessarily complete instantaneously, we need to
// check completion status periodically on a timer.
var timer = null;
var currentRequest = null;
// Sends the RPC give in url and then invokes the function specified by
// the callback parameter when the RPC is complete.
function sendRPC(url, callback)
{
// If we've already got a request in progress, cancel it
if (currentRequest)
clearTimeout(timer);
currentRequest = new Image();
currentRequest.src = url; // Send rpc
setTimeout(callback, 50); // Check for completion in 50ms
}
// Checks to see if the RPC has completed. If so, it checks the size of the
// image and alerts the user accordingly. If not, it schedules itself to
// check again in 50ms.
function readResponse()
{
// If image hasn't downloaded yet...
if (!currentRequest.complete)
{
timer = setTimeout(readResponse, 50);
return;
}
// Else image has downloaded, so check it
if (currentRequest.height == 1)
alert("User is not online");
else
alert("User is online");
timer = currentRequest = null;
}
// Check to see if the user is online. The function readResponse will be
// invoked once a response has been received.
function isUserOnline(user)
{
var params = "user=" + user;
sendRPC(commandURL + params, readResponse);
return false;
}
<</script>>
<<!-- Test Code -->>
User: Smeagol (<<a href="#"
onclick="return isUserOnline('smeagol');">>check
online status<</a>>) [should be false] <<br />>
User: Deagol (<<a href="#"
onclick="return isUserOnline('deagol');">>check
online status<</a>>) [should be true]
<</body>>
<</html>>
Notice in the preceding script that we go to great lengths to accommodate the fact that the image may take time to download (either because of slow server processing or a slow network connection). Since the RPC (image download) may take time, we schedule the callback function to be run every 50 milliseconds. Each time it runs, readResponse() checks the complete property of the Image we’re using for the request. As discussed in Chapter 15, this property is set by the browser when the image has completed downloading. If complete is true, the JavaScript reads the response encoded in the image’s height. If complete is false, the browser needs more time to fetch the image, so readResponse() is scheduled to run again 50 milliseconds in the future.
By far the most common mistake programmers make when implementing two-way communication techniques in JavaScript is forgetting to allow for the possibility that the RPC takes longer than expected. Paranoid coding is definitely called for in these situations, and setTimeout() is a useful tool. We’ll see a more sophisticated callback-based approach in a later section.
One other noteworthy feature of the previous example is that we only allow for one outstanding RPC at a time. If a new RPC comes in while we’re still waiting for one to complete, we cancel the first and issue the second. This policy simplifies coding a bit, but in truth accommodating multiple outstanding requests at one time isn’t much more work. All it takes is carefully managing three things: references to the images executing each RPC, the functions that should be called when each RPC completes, and the timers used to periodically check if an RPC has completed.
A thread is an execution stream in the operating system. Code executing in a thread can do exactly one thing at a time; to achieve multiprocessing, an application needs to be multi-threaded (i.e., be able to execute multiple streams of instructions at once).
Almost without exception, JavaScript interpreters are single-threaded, and they often share the browser’s UI thread. This means that when your JavaScript is doing something, no other JavaScript can execute, nor can the browser react to user events such as mouse movement or button clicks. For this reason, it is never a good idea to “block” your JavaScript waiting for some condition.
For example, instead of registering a timer to check whether the request in the previous example had completed, we might have done away with the timers and written readResponse() as
function readResponse()
{
// Wait until the image downloads...
while (!currentRequest.complete); // do nothing
if (currentRequest.height == 1)
alert("User is not online");
else
alert("User is online");
}
“Spinning” on the currentRequest.complete value in this way is a very bad idea. Not only are you most likely preventing the user from doing anything while waiting for the image to download, you run the risk of completely locking up the browser if the image download somehow fails. If currentRequest.complete is never true, you’ll just sit in the tight loop forever while the user frantically tries to regain control.
If the first rule of good JavaScript RPC habits is to accommodate RPC taking longer than expected, the second is definitely to use timeouts or callbacks to signal events such as completion of the call.
Instead of communicating the return value via properties of the image, your server could return the value in a cookie. In response to a request for an RPC URL, your server would issue a Set-cookie HTTP header along with the image or whatever other response you’ve decided on. This technique is nearly identical to using an image, but you read the return value from document.cookie instead of Image.height.
One thing to keep in mind is that, by default, Internet Explorer 6 rejects “third-party” cookies unless they’re accompanied by P3P headers. The cookie you’re attempting to set is considered “third-party” if it is set in response to a request to a domain other than that from which the document was fetched. So, if your site is www.mysite.com and your JavaScript makes a cookie-based RPC to www.example.com, the www.example.com server must include P3P headers in its response in order for IE6 to accept any cookies it sets.
P3P is the Platform for Privacy Preferences, a W3C standard driven primarily by Microsoft. Web servers can include special P3P HTTP headers in their responses and these headers encode the privacy policy for the site, for example, whether they share your personally identifiable information with marketers and the like. Browsers can use this information and a policy set by the user to make decisions about how much to trust the Web site. For example, if a site’s privacy policy is very permissive with respect to information sharing, users might wish to never accept persistent cookies from the site and to be warned before submitting personal information. You can learn more about P3P, including how to configure your Web server to use it, at www.w3.org/P3P/.
Although the DHTML techniques in Chapter 15 enable you to dynamically modify and update your pages, those techniques are somewhat limited in the sense that all the logic and content you wish to use needs to be a part of the page (i.e., coded into your script). Aside from images and frames, there really is no provision for dynamically updating the page with HTML retrieved from a server. However, with some carefully written JavaScript and some server-side programming, you actually can realize truly dynamic content with DHTML.
One fundamental vehicle enabling server-fetched content is externally linked scripts. When you wish to retrieve content from the server, you use JavaScript to write a <<script>> tag into the page and point its src to a URL at which a server-side program will run. You can pass “arguments” to your server-side program via the query parameters in the URL, much like we saw before with the image-, cookie-, and redirect-based techniques. When your server-side program receives a request, it processes the information encoded in the URL and then returns as its response JavaScript that writes out the required dynamic content. The JavaScript in the response has been linked into the page with the <<script>> tag, so the browser downloads and executes it, with the presumable result of updating the page with the content it writes out.
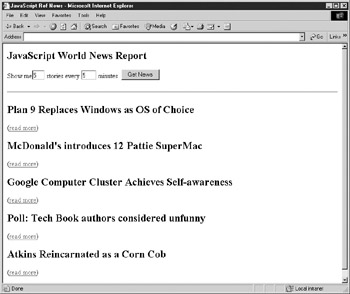
To illustrate the concept, consider the following page, which has a content area for displaying top news stories. Every five minutes, the JavaScript makes an RPC to the server to retrieve new content for the news area.
<<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">> <<html xmlns="http://www.w3.org/1999/xhtml">> <<head>> <<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />> <<title>>JavaScript Ref News<</title>> <</head>> <<body>> <<h2>>JavaScript World News Report<</h2>> <<form name="newsform" id="newsform" action="#" method="get">> Show me<<input type="text" name="numstories" id="numstories" size="1" value="5" />> stories every <<input type="text" name="howoften" id="howoften" size="2" value="5" />> minutes. <<input type="button" value="Get News" onclick="updateNews();" />> <</form>> <<hr />> <<div id="news">> Fetching news stories... <</div>> <<br />> <<script type="text/javascript">> var commandURL = "http://demos.javascriptref.com/getnews.php?"; // Sends the RPC given in url. The server will return JavaScript that will // carry out the required actions. function sendRPC(url) { var newScript = document.createElement('script'); newScript.src = url; newScript.type = "text/javascript"; document.body.appendChild(newScript); } // Fetch some news from the server by sending an RPC. Once it's sent, set // a timer to update the news stories at some point in the future. function updateNews() { var params = "numstories=" + document.newsform.numstories.value; sendRPC(commandURL + params); var checkAgain = 5 * 60 * 1000; // default: 5 minutes if (parseInt(document.forms.newsform.howoften)) checkAgain = parseInt(document.forms.newsform.howoften) * 60 * 1000; setTimeout(updateNews, checkAgain); } updateNews(); <</script>> <</body>> <</html>>
| Note |
One potential problem with this example is that because it repeatedly adds new <<script>>s to the page, the user’s browser might end up consuming lots of memory if the page is left to sit for hours or days. For this reason, it might be a good idea to re-target the src of an existing script instead, though in neither case are you guaranteed not to have memory issues over the long term. |
The server-side script implementing the RPC would grab the new stories from a source and then construct and return JavaScript writing them into the page. For example, the JavaScript returned for http://demos.javascriptref.com/getnews.php?numstories=4 might be something like this:
var news = new Array();
news[0] = "<<h2>>Plan 9 Replaces Windows as OS of Choice<</h2>>" +
"(<<a href='/news/stories?id=431'>>read more<</a>>)";
news[1] = "<<h2>>McDonald's introduces 12 Pattie SuperMac<</h2>>" +
"(<<a href='/news/stories?id=193'>>read more<</a>>)";
news[2] = "<<h2>>Google Computer Cluster Achieves Self-awareness<</h2>>" +
"(<<a href='/news/stories?id=731'>>read more<</a>>)";
news[3] = "<<h2>>Poll: Tech Book authors considered unfunny<</h2>>" +
"(<<a href='/news/stories?id=80'>>read more<</a>>)";
var el = document.getElementById("news"); // Where to put the content
el.innerHTML = ""; // Clear current content
for (var i=0; i<<news.length; i++)
el.innerHTML += news[i]; // Write content into page
The news demo is shown in Figure 19-1.
While it’s clear you could achieve a similar effect using meta-refreshes or JavaScript redirects, the dynamic content approach doesn’t require reloading the page and allows you to update multiple content areas independently from different sources. You just need to be careful to keep your naming consistent so the scripts returned by the server can access the appropriate parts of the page.
| Note |
Those familiar with JavaScript’s same origin policy (Chapter 22) might wonder if this technique would work if the RPC is made to a server other than that from which the document was fetched. The answer is yes, because externally linked scripts are not subject to the same origin policy. |
You need to be extremely careful to avoid cross-site scripting vulnerabilities when implementing dynamic content fetching. Chapter 22 has more information, but the basic idea is that if your server-side script takes query parameters and then writes them back out in the response without escaping them, an attacker could pass JavaScript in the URL, which would then be executed by the browser in the context of your site. For example, an attacker could construct a URL that includes JavaScript to steal users’ cookies and then send spam out.
The dynamic content approach isn’t limited to fetching content; you can use it to carry out server-side computation that would be impossible (or at least very inconvenient) to do with JavaScript. As an example, suppose you wished to provide a spelling correction feature for a <<textarea>> on your page. To include a dictionary and spelling-correction code in your script would be unwieldy at best, so the feature is better implemented via RPC to a server.
The following example illustrates the basic concept. To keep things simple, this script only checks a single word entered in an <<input>>, but you could extend it to check an entire <<textarea>>. Notice how we use a variable to signal that the RPC is complete.
<<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">>
<<html xmlns="http://www.w3.org/1999/xhtml">>
<<head>>
<<title>>RPC Spellchecker<</title>>
<<meta http-equiv="content-type" content="text/html; charset=utf-8" />>
<<script type="text/javascript">>
<<!--
var commandURL = "http://demos.javascriptref.com/checkspelling.php?";
var rpcComplete = false;
var rpcResult = null;
var timer = null;
// Sends the RPC given in url. The server will return JavaScript that sets
// rpcComplete to true and rpcResult to either true (meaning the word is
// spelled correctly) or a string (containing the corrected spelling).
function sendRPC(url)
{
// If an rpc is pending, wait for it to complete.
if (timer)
{
setTimeout("sendRPC('" + url + "')", 71); // Try again in 71ms
return;
}
rpcComplete = false;
var newScript = document.createElement('script');
newScript.src = url;
newScript.type = "text/javascript";
document.body.appendChild(newScript);
readResponse();
}
function checkSpelling(word)
{
var params = "word=" + word;
sendRPC(commandURL + params);
}
function readResponse()
{
if (!rpcComplete)
{
timer = setTimeout(readResponse, 50);
return;
}
// RPC is complete, so check the result
if (rpcResult === true)
alert("Word is spelled correctly.");
else
alert("Word appears to be misspelled. Correct spelling might be " +
rpcResult);
timer = rpcResult = null;
}
//-->>
<</script>>
<</head>>
<<body>>
<<h2>>Server-side Spelling Correction<</h2>>
<<form name="spellform" id="spellform" action="#" method="get">>
Check the spelling of
<<input type="text" name="word" id="word" value="absquatalate" />>
<<input type="button" value="check" onclick="checkSpelling(document.spellform.word.value);" />>
<</form>>
<</body>>
<</html>>
When you enter “the” into the input box in the previous example, the server-side CGI script might return
rpcComplete = true; rpcResult = true;
If you enter a misspelled word, for example, “absquatalate,” the server should return the corrected spelling:
rpcComplete = true; rpcResult = "absquatulate";
This example is shown in action in Figure 19-2.
One aspect of the previous script is particularly noteworthy: If we want to send an RPC request while one is already pending, we must wait for the first request to complete. Once the browser has begun loading the first RPC’s <<script>>, we can’t stop it, and if we start another RPC while it’s loading we run the risk of clobbering the return values. There are ways around this problem. For example, you can keep arrays of timers and return values in order to manage multiple requests concurrently. Another, more elegant approach is to use a callback.
A callback is a function that will be called when an RPC completes. The idea is simple: instead of periodically checking whether an RPC has completed, have the script returned by the server call a function instead.
Using a callback simplifies our spelling correction script:
<<script type="text/javascript">>
var commandURL = "http://demos.javascriptref.com/checkspelling.php?";
// Sends the RPC given in url. The server will return JavaScript that calls
// RPCComplete() with the result.
function sendRPC(url)
{
var newScript = document.createElement('script');
newScript.src = url;
newScript.type = "text/javascript";
document.body.appendChild(newScript);
}
function checkSpelling(word)
{
var params = "word=" + word;
sendRPC(commandURL + params);
}
function RPCComplete(rpcResult)
{
if (rpcResult === true)
alert("Word is spelled correctly.");
else
alert("Word appears to be misspelled. Correct spelling might be " +
rpcResult);
}
<</script>>
In this new incarnation the server-side script would return something like the following when you enter “the” into the input box:
RPCComplete(true);
If you enter a misspelled word like “absquatalate,” the server should pass the correct spelling to the completion function:
RPCComplete("absquatulate");
Most developers choose to use the flag technique when loading external JavaScript libraries, but a callback when performing RPC. This is because the former is easier to coordinate if you have multiple external scripts whereas the latter is simpler when you’re only loading one script to do RPC.
It is also possible to perform two-way remote communications using a combination of <<iframe>>s and JavaScript. In some ways, inline frames are somewhat easier than other RPC approaches because each <<iframe>> represents a complete document that can easily be targeted. For example, if you have an inline frame like
<<iframe name="iframe1" id="iframe1">> <</iframe>>
you can target the frame with a form like so,
<<form name="myform" id="myform" action="load.cgi" method="get" target="iframe1">> <<input type="text" name="username" id="username" />> <<input type="submit" value="send" />> <</form>>
and the result of the form submission will appear in the <<iframe>> rather than the main window since the target attribute is set to the <<iframe>>. The server-side then could deliver a result that would appear in the <<iframe>>, which could then be viewed by the user or read by JavaScript.
In order to create a basic RPC example using an inline frame, we need to create the <<iframe>> dynamically using the DOM and then hide it using CSS. Once we do that, we are free to set the <<iframe>>‘s src or location and then read responses in its body or use script to pass the contents back to the enclosing window. The following simple example demonstrates this idea.
<<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">>
<<html xmlns="http://www.w3.org/1999/xhtml">>
<<head>>
<<title>>Iframe RPC<</title>>
<<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />>
<</head>>
<<body>>
<<form action="#" method="get">>
<<input type="text" name="username" id="username" />>
<<input type="button" value="send" onclick="send(this.form.username.value);" />>
<</form>>
<<h1>>The Server Response<</h1>>
<<div id="response">><</div>>
<<script type="text/javascript">>
<<!--
var theIframe = document.createElement("iframe");
theIframe.setAttribute("src", "");
theIframe.setAttribute("id", "myIframe");
theIframe.style.visibility='hidden';
document.body.appendChild(theIframe);
function send(sendValue)
{
var newLocation = 'iframeResponse.php?sendvalue='+escape(sendValue);
theIframe.src = newLocation;
}
function RPCComplete(msg)
{
var region = document.getElementById('response');
region.innerText = msg;
}
//-->>
<</script>>
<</body>>
<</html>>
In this case the iframeResponse.php program takes the message and responds back to the user by invoking the RPCComplete() function in the main window. Here is a fragment of a possible server-side script in PHP to handle the RPC. The value $message was calculated previously—we aim here only to show how the callback works.
<<?php
echo "<<script>>" ;
$call = "window.parent.RPCComplete('".$message."');";
echo $call;
echo "<</script>>";
?>>
In order to see this in action, you would have to put the two files up on a server. If that isn’t possible, go to http://demos.javascriptref.com/iframedemo.html to see an online demo. As you progress to more complex JavaScript, you should try to become more comfortable using <<iframe>>s as they are useful not only for remote scripting but also for holding XML data.
| Note |
Because <<iframe>>s are full windows many browsers will consider them part of the navigation history and using the Back button may cause trouble. |
The techniques we’ve covered so far use standard browser features for purposes other than that for which they were intended. As such, they lack many features you might want out of RPC-over-HTTP, such as the ability to check HTTP return codes and to specify username/password authentication information for requests. Modern browsers let you do JavaScript RPCs in a much cleaner, more elegant fashion with a flexible interface supporting the needed features missing from the previously discussed hacks.
Internet Explorer 5 and later support the XMLHTTP object and Mozilla-based browsers provide an XMLHTTPRequest object. These objects allow you to create arbitrary HTTP requests (including POSTs), send them to a server, and read the full response, including headers. Table 19-1 shows the properties and methods of the XMLHTTP object.
|
Property or Method |
Description |
|---|---|
|
readyState |
Integer indicating the state of the request, either |
|
Onreadystatechange |
Function to call whenever the readyState changes. |
|
status |
HTTP status code returned by the server (e.g., “200”). |
|
statusText |
Full status HTTP status line returned by the server (e.g., “200 OK”). |
|
responseText |
Full response from the server as a string. |
|
responseXML |
A Document object representing the server's response parsed as an XML document. |
|
abort() |
Cancels an asynchronous HTTP request. |
|
getAllResponseHeaders() |
Returns a string containing all the HTTP headers the server sent in its response. Each header is a name/value pair separated by a colon, and header lines are separated by |
|
getResponseHeader(headerName) |
Returns a string corresponding to the value of the headerName header returned by the server (e.g., request.getResponseHeader("Set-cookie")). |
|
open(method, url [, asynchronous
|
Initializes the request in preparation for sending to the server. The method parameter is the HTTP method to use, for example, GET or POST. The url is the URL the request will be sent to. The optional asynchronous parameter indicates whether send() returns immediately or after the request is complete (default is true, meaning it returns immediately). The optional user and password arguments are to be used if the URL requires HTTP authentication. If no parameters are specified by the URL requiring authentication, the user will be prompted to enter it. |
|
setRequestHeader(name, value) |
Adds the HTTP header given by the name (without the colon) and value parameters. |
|
send(body) |
Initiates the request to the server. The body parameter should contain the body of the request, i.e., a string containing fieldname=value&fieldname2=value2… for POSTs or the empty string ("") for GETs. |
| Note |
Since the interfaces of these objects as well as their functionality are identical, we’ll arbitrarily refer to both as XMLHTTP objects. |
| Note |
Internet Explorer supports two properties not listed in Table 19-1. The responseBody property holds the server’s response as a raw (undecoded) array of bytes and responseStream holds an object implementing the IStream interface through which you can access the response. Mozilla supports the onload property to which you can set a function that will be called when an asynchronous request completes. However, as these properties are all browser-specific, we don’t discuss them. You can find more information about them on the respective browser vendors’ Web sites. |
Some of the properties and methods listed in Table 19-1, such as responseText and getAllResponseHeaders(), won’t be available until the request has completed. Attempting to access them before they’re ready results in an exception being thrown.
XMLHTTP requests can be either synchronous or asynchronous, as specified by the optional third parameter to open(). The send() method of a synchronous request will return only once the request is complete, that is, the request completes “while you wait.” The send() method of an asynchronous request returns immediately, and the download happens in the background. In order to see if an asynchronous request has completed, you need to check its readyState. The advantage of an asynchronous request is that your script can go on to other things while it is made and the response received, for example, you could download a bunch of requests in parallel.
To create an XMLHTTP object in Mozilla-based browsers, you use the XMLHttpRequest constructor:
var xmlhttp = new XMLHttpRequest();
In IE, you instantiate a new MSXML XHMLHTTP ActiveX object:
var xmlhttp = new ActiveXObject("Msxml2.XMLHTTP");
Once you have an XMLHTTP object, the basic usage for synchronous requests is
Parameterize the request with open().
Set any custom headers you wish to send with setRequestHeader().
Send the request with send().
Read the response from one of the response-related properties.
The following example illustrates the concept:
if (document.all)
var xmlhttp = new ActiveXObject("Msxml2.XMLHTTP");
else
var xmlhttp = new XMLHttpRequest();
xmlhttp.open("GET", "http://www.example.com/somefile.html", false);
xmlhttp.send("");
alert("Response code was: " + xmlhttp.status)
The sequence of steps for an asynchronous request is similar:
Parameterize the request with open().
Set any custom headers you wish to send with setRequestHeader().
Set the onreadystatechange property to a function to be called when the request is complete.
Send the request with send().
The following example illustrates an asynchronous request:
if (document.all)
var xmlhttp = new ActiveXObject("Msxml2.XMLHTTP");
else
var xmlhttp = new XMLHttpRequest();
xmlhttp.open("GET", window.location);
xmlhttp.onreadystatechange = function() {
if (xmlhttp.readyState == 4)
alert("The text of this page is: " + xmlhttp.responseText);
};
xmlhttp.setRequestHeader("Cookie", "FakeValue=yes");
xmlhttp.send("");
When working with asynchronous requests, you don’t have to use the onreadystatechange handler. Instead, you could periodically check the request’s readyState for completion.
You can POST form data to a server in much the same way as issuing a GET. The only differences are using the POST method and setting the content type of the request appropriately (i.e., to “application/x-www-form-urlencoded”).
var formData = "username=billybob&password=angelina5";
var xmlhttp = null;
if (document.all)
xmlhttp = new ActiveXObject("Msxml2.XMLHTTP");
else if (XMLHttpRequest)
xmlhttp = new XMLHttpRequest();
if (xmlhttp)
{
xmlhttp.open("POST", "http://demos.javascriptref.com/xmlecho.php", false);
xmlhttp.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
xmlhttp.send(formData);
document.write("<<hr />>" + xmlhttp.responseText + "<<hr />>");
}
We’ll see how you can send not just form data, but actual XML, in Chapter 20. But before we do, we need to issue a few warnings with respect to these capabilities.
If you attempt to issue an XMLHTTP request to a server other than that from which the document containing the script was fetched, the user must confirm the request in a security dialog. To see why this is a good thing, suppose that no confirmation was necessary. Then, if you went from your online banking site to a page at evilsite.com without first logging out, a script on evilsite.com could issue an XMLHTTP request to silently download your banking information. The info could then be uploaded to evilsite.com, with predictable results. In essence, without the user confirmation step, XMLHTTP could be used to violate the same origin policy (Chapter 22).
JavaScript Debugger
JavaScript Editor