JavaScript Debugger
JavaScript Editor
JavaScript Debugger
JavaScript Editor
If you found the object collections of the previous chapter easier to follow compared to the DOM, you aren’t alone. Many JavaScript programmers have avoided the complexity of the DOM Level 1 in favor of old-style collections like document.forms[] and document.images[], and even proprietary collections like document.all[]. Fortunately, many of these are supported under DOM Level 0 so these folks aren’t going non-standard. Even when they do go proprietary it is for good reason as some aspects of the DOM are somewhat clunky, particularly when adding content to the document. Because of this some proprietary features like Microsoft’s innerHTML are being added to even strict standards-compliant browsers. Furthermore, other features live on simply because IE is by far the dominant browser. Because of the reality of IE’s dominance, let’s take another look at a few of the 4.x-generation Browser Object Models that refuse to die.
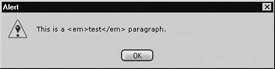
Netscape 6+, Opera 7+, and Internet Explorer 4+ all support the non-standard innerHTML property. This property allows easy reading and modification of the HTML content of an element. The innerHTML property holds a string representing the HTML contained by an element. Given this HTML markup,
<<p id="para1">>This is a <<em>>test<</em>> paragraph.<</p>>
the following script retrieves the enclosed content,
var theElement = document.getElementById("para1");
alert(theElement.innerHTML);
as shown here:
You can also set the contents of the HTML elements easily with the innerHTML property. The following simple example provides a form field to modify the contents of a <<p>> tag. Try running the example and adding in HTML markup. As you will see, it is far easier to add HTML content to nodes using this property than by creating and setting nodes using standard DOM methods.
<<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">> <<html xmlns="http://www.w3.org/1999/xhtml">> <<head>> <<title>>innerHTML Tester<</title>> <<meta http-equiv="content-type" content="text/html; charset=utf-8" />> <</head>> <<body onload="document.testForm.content.value = theElement.innerHTML;">> <<div id="div1">>This is a <<em>>test<</em>> of innerHTML.<</div>> <<script type="text/javascript">> <<!-- var theElement = document.getElementById("div1"); //-->> <</script>> <<form name="testForm" id="testForm" action="#" method="get">> Element Content: <<input type="text" name="content" id="content" size="60" />> <<input type="button" value="set" onclick="theElement.innerHTML = document.testForm.content.value;" />> <</form>> <</body>> <</html>>
Internet Explorer also supports the innerText, outerText, and outerHTML properties. The innerText property works similarly to the innerHTML property, except that any set content will be interpreted as pure text rather than HTML. Thus, inclusion of HTML markup in the string will not create corresponding HTML elements. Setting para1.innerText = "<<b>>test<</b>>" will result not in bold text but rather with the string being displayed as “<<b>>test<</b>>.” The outerHTML and outerText properties work similarly to the corresponding inner properties, except that they also modify the element itself. If you set para1.outerHTML = "<<b>>test<</b>>", you will actually remove the paragraph element and replace it with “<<b>>test<</b>>”. The following example is useful if you would like to play with these properties.
<<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">>
<<html xmlns="http://www.w3.org/1999/xhtml">>
<<head>>
<<title>>inner/outer Tester<</title>>
<<meta http-equiv="content-type" content="text/html; charset=utf-8" />>
<</head>>
<<body onload="document.testForm.content.value = theElement.innerHTML;">>
<<div style="background-color: yellow">>
<<br />>
<<p id="para1">>This is a <<em>>test<</em>> paragraph.<</p>>
<<br />>
<</div>>
<<br />><<br />><<hr />>
<<script type="text/javascript">>
<<!--
var theElement = document.getElementById("para1");
//-->>
<</script>>
<<form name="testForm" id="testForm" action="#" method="get">>
Element Content:
<<input type="text" name="content" id="content" size="60" />> <<br />>
<<input type="button" value="set innerHTML"
onclick="theElement.innerHTML = document.testForm.content.value;" />>
<<input type="button" value="set innerText"
onclick="theElement.innerText = document.testForm.content.value;" />>
<<input type="button" value="set outerText"
onclick="theElement.outerText = document.testForm.content.value;" />>
<<input type="button" value="set outerHTML"
onclick="theElement.outerHTML = document.testForm.content.value;" />>
<<input type="button" value="Reset" onclick="location.reload();" />>
<</form>>
<</body>>
<</html>>
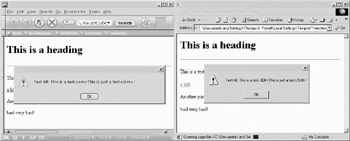
Like it or not, a great deal of script code has been written for the Internet Explorer object model discussed in the last chapter. Probably the most popular aspect of this model is document.all[]. This collection contains all the (X)HTML elements in the entire document in read order. Given that many JavaScript applications have been written to take advantage of this construct, you might wonder how it relates to the DOM. In short, it doesn’t. The DOM doesn’t support such a construct, but it’s easy enough to simulate it under DOM-aware browsers. For example, under the DOM, we might use the method document.getElementsByTagName() to fetch all elements in a document. We could then set an instance property document.all equal to document .getElementsByTagName("*") if the all[] collection did not exist. The following example illustrates this idea:
<<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">>
<<html xmlns="http://www.w3.org/1999/xhtml">>
<<head>>
<<title>>All Test<</title>>
<<meta http-equiv="content-type" content="text/html; charset=utf-8" />>
<</head>>
<<body>>
<<!-- comment 1 -->>
<<h1>>This is a heading<</h1>>
<<hr />>
<<p id="test">>This is a test.<<em>>This is just a test<</em>>!<</p>>
<<a href="/">>a link<</a>>
<<p>>Another paragraph<</p>>
<<badtag>>bad very bad!<</badtag>>
<<script type="text/javascript">>
<<!--
if (!document.all)
document.all = document.getElementsByTagName("*");
var allTags ="Document.all.length="+document.all.length+"\n";
for (i = 0; i << document.all.length; i++)
allTags += document.all[i].tagName + "\n";
alert(allTags);
alert("Test All: "+document.all['test'].innerHTML);
//-->>
<</script>>
<</body>>
<</html>>
Note that this example really doesn’t create a perfectly compatible all[] collection for Mozilla or other DOM-aware browsers, since Microsoft’s all[] collection will include comments and both the start and end tag of an unknown element. The two dialogs presented here show this difference:

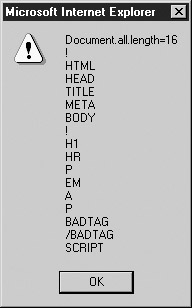
It would be possible to insert the DOCTYPE and comments into our fake all[] collection, but the bad tag “feature” of Internet Explorer presents a problem. However, as we see in the second alert() test shown in Figure 10-6, things aren’t quite that bad if you are just looking to preserve your previous scripting efforts in DOM-aware browsers!
JavaScript Debugger
JavaScript Editor