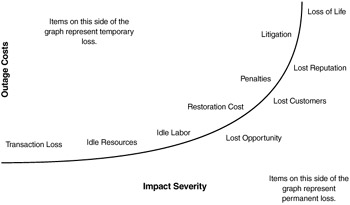
Many organizations will initially attempt to deploy Web services for non-mission-critical applications. For others, who are using Web services to generate revenue, making your services highly available becomes mandatory. Before starting the journey to deploying mission-critical systems, you must consider the cost of downtime, lost opportunities, lost revenue, and any stranded fixed cost your organization would need to pay whether productive or not.
Damage is sometimes harder to calculate. Loss of good will with customers, partners, and suppliers affected by unavailable services will give the impression that your organization is poorly run and incapable of fulfilling their needs. If your organization is in the public health or safety area, an unavailable service could potentially cost lives.
An organization must weigh the high cost of downtime. The higher the cost of downtime, the more robust your availability plans must be. Figure 16.3 outlines the relative severity of an impact and its resulting costs. The architects of a Java-based Web service must analyze and document what is affected when a system goes down. Here are some additional thoughts to consider:
Managers and users may find themselves without information necessary to make intelligent decisions. With lost information, standard activities in an organization may be delayed or incorrectly executed. Downstream systems may also make incorrect decisions based on missing or corrupted information.
Deadlines may be missed, with catastrophic results. Imagine a Web service that accepts change orders for an expensive, custom-made product. What would happen if a customer could not submit a change before the cutoff time?
The Internet allows consumers choice. If customers use your service and it does not work, they are unlikely to come back. Consider the effect your service may have on downstream systems, such as order and inventory management, financial reporting, human resources, emergency notification, identification, ATM and other wire transfer facilities, and life-sustaining medical systems.
Consider the impact on morale and legal implications of not being available. Imagine if the military developed a Web service that fed enemy movement information to a central command center, and it was down.
Availability refers to the time a service is operational and is expressed as a percentage. High availability usually refers to running for extended periods, exceeding 99.99%, with minimal unplanned outages. . This is referred to as four nines. Similarly, 99.999% is referred to as five nines, which requires all components of your service, including the operating system, network, human errors, and so on to have no more than five minutes of downtime a year (Table 16.4).
|
Measurement |
Number of nines |
Time lost in one year |
|---|---|---|
|
90% |
One |
36 days (876 hours) |
|
99% |
Two |
3.6 days (87 hours) |
|
99.9% |
Three |
8.8 hours |
|
99.99% |
Four |
53 minutes |
|
99.999% |
Five |
5 minutes |
|
99.9999% |
Six |
32 seconds |
To provide a highly available service, every component of your infrastructure must support high availability. The level of availability can be no better than that of the weakest link. Increasing availability requires incremental improvement to each component in your network. This is preferable to seeking 100% availability for a specific component.
Many organizations assume that achieving higher levels of availability is expensive. This is not necessarily true. Availability is not free. It requires executive management attention, hard work, and due diligence to assemble the right people, processes, and tools. It starts with reliable, stable components. Higher levels of availability require methodical system integration and detailed application design.
The real cause of many outages tends to be human error. Many organizations have spent millions of dollars on high-availability solutions, only to have a network administrator accidentally unplug a crucial component. Other outages arise from fixing problems that are not the root cause but appear so because of inadequate documentation. To achieve the highest levels of availability, implement a comprehensive change-management strategy that defines repeatable processes.
To increase the availability of your Web service, include your consumers' requirements for performance, reliability, and availability. Availability is hard to incorporate after the fact and must be included initially in application design. Using a Web service to integrate with legacy systems may require these applications to be redesigned.
Architects and developers alike must be educated about the cost of outages, to make the appropriate tradeoffs. They should also make sure components are suitable for the negotiated availability needs.
The design should keep the scope of a failure small by isolating important processes, such as sessioning, and tightly coupling integration with other components. Those who have worked in mainframe shops may have observed that these machines cannot run a batch cycle while online applications are available. Make sure your service does not depend on other components being available. Also take into account that recovery in case of failure should be fast, intuitive, and should not require a lot of internal or external coordination.
The one step any IT shop can take is to employ standard processes and procedures. Naming conventions help reduce errors and improve communications immensely. By having a standardized process such as naming conventions, compilers can serve as a built-in check for change management and other related activities.
Managing your Web services should take into account the end-to-end view from a business perspective. All resources the Web service uses should be managed within the context of a business process. This allow administrators and the business community to ascertain and understand the business impact on any one resource. It has the additional advantage of allowing administrators to prioritize their next steps in outages, performance slowdowns, and other business-critical situations based on quantifiable business needs.
Another important consideration is a unified view of security. A breach will cause downtime. The main problem is that different roles within an organization, such as architects, developers, security administrators, and operations, typically have their own views of the world. They usually administer security policies on the resources they directly manage. Organizations that don't use single sign-on usually have multiple identities spread across multiple parties. Even the simplest task of disabling a user ID will repeatedly produce inconsistent levels of access throughout the services offered.
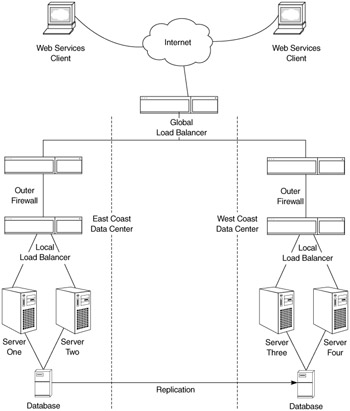
Redundant, reliable components in your infrastructure are the key to availability. Redundancy in components, systems, and data can eliminate single points of failure (Figure 16.4). Consider incorporating clustering (hardware and/or software) into the infrastructure. The essential principle is to present a common addressing scheme to the underlying components.
As an example, a load-balancing appliance (e.g. Alteon, Cisco CSS, F5 Big IP) provides a single IP address for a group of servers. A Web service consumer needs only direct a request to the IP address exposed by the load-balancing appliance. The appliance, in turn, directs the request to the server with the least utilization. The appliance also determines when a server in the cluster is not functioning and routes requests away from it. The added benefit of this approach is the ability to take servers offline one at a time for maintenance without affecting users. Many appliances allow you to implement several algorithms for determining where to direct Web service requests, such as load balancing, server utilization, or application affinity.
Many white papers published by industry analysts such as the Gartner Group and Forrester Research cover the business aspects of high availability and help an organization determine whether it requires "five nines." The technology aspect of high availability especially in Java Web service, requires additional thinking and architectural planning. Let us outline some questions you should ask your-self about each tier:
Hardware. Do the components in your infrastructure (servers, routers, switches, and other appliances) have uninterruptible power supplies or fault tolerant memory or I/O? Do they have redundant disks, controllers, network interfaces, and CPUs?
Network. Is there more than one path (route) to your Web service? What are the characteristics of your network, and do they provide self-healing? Are you connected to more than one Internet service provider? Does your Java Web service have hard-coded host names embedded in it?
Database. Have you consider employing replication, online backup, or other strategies? Does your Java Web service delegate connections to a JDBC pool provided by an application server, so that the J2EE containers can failover connections?
Management. Can your application detect failures and alert the appropriate personnel? Have you turned on SNMP support provided by your application server? Have you built a logging mechanism into your architecture and put the hooks in the appropriate locations of your service?
Web servers. Have you configured appropriate response pages when a service is unavailable? Have you considered using load-balancing appliances, such as those from Cisco, Alteon, Coyote Point, or F5?
Application servers. Are you taking full advantage of the capabilities provided by your Java application server and its support for clustering, hot deployment of components, replicated session state, and a global JNDI namespace?