Document Object Model (DOM) is defined by W3C as a set of recommendations. The DOM core recommendations define a set of objects, each of which represents some information relevant to the XML document. There are also well defined relationships between these objects, to represent the document's organization.
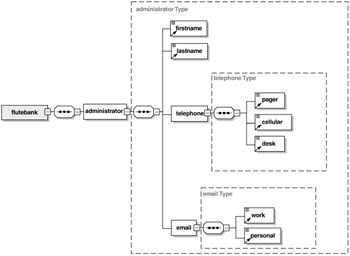
A DOM parser essentially reads the XML document and constructs a tree structure in memory that represents the original document, as Figure 9.2 shows. This tree is composed of well-defined objects. Applications can then navigate through the branches of this tree and manipulate the XML. The parser implementations, including the reference implementation, internally use a SAX parser to read the XML into memory. The XML is then analyzed for the relationships between the component parts and is organized into a tree structure that can be traversed.
DOM is organized into levels. Level 1 details the functionality and navigation of content within a document. Level 2 (also refered to as DOM 2.0) adds to Level 1 (e.g., ability to access tree members by namespace names). Level 2 is composed of a set of specifications, as shown below. Everything except the core is optional to implement for a DOM 2-compliant parser. Level 3 is a working draft.
DOM Level 2 Core: Defines the basic object model to represent structured data
DOM Level 2 Views: Allows access and update of the representation of a DOM
DOM Level 2 Style: Allows access and update of style sheets
DOM Level 2 Traversal and Range: Allows walk through, identify, modify, and delete a range of content in the DOM
Unlike SAX, DOM is specified in an implementation-independent manner and defines all its constructs for these objects via Object Management Group Interface Definition Language (OMG IDL). It then defines Java language bindings for those constructs. These Java bindings are packaged by the W3C in the org.w3c.dom package, which is also overlaid with JAXP.
JAXP endorses only the DOM 2.0 core, which is fully namespace aware. DOM specifications from the W3C can be found at www.w3.org/DOM/DOMTR.
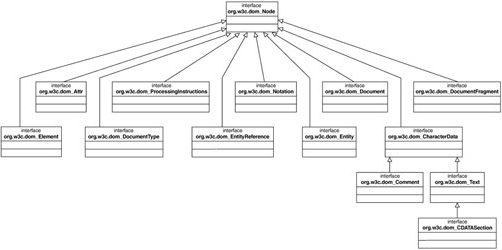
Figure 9.3 shows the class relationships between the major component interfaces of the org.w3c.dom package.
In DOM, a root element is a Node, which contains methods for working with the node name and attributes. Each subclass shown in Figure 9.3 represents a specific type of item from the XML. The Document represents the entire XML structure and is the conceptual root of the tree. It has methods that relate to creating nodes, assembling these nodes into the tree, and locating elements by name.
Listing 9.3 describes the IDL definition of the Document object, as defined in the W3C specification. Notice how the IDL constructs did directly map to Java interfaces in the org.w3c.dom package in Figure 9.3.
interface Document : Node {
readonly attribute DocumentType doctype;
readonly attribute DOMImplementation implementation;
readonly attribute Element documentElement;
Element createElement(in DOMString tagName) raises(DOMException);
DocumentFragment createDocumentFragment();
Text createTextNode(in DOMString data);
Comment createComment(in DOMString data);
CDATASection createCDATASection(in DOMString data) raises(DOMException);
ProcessingInstruction createProcessingInstruction(in DOMString target,
in DOMString data) raises(DOMException);
Attr createAttribute(in DOMString name) raises(DOMException);
EntityReference createEntityReference(in DOMString name) raises(DOMException);
NodeList getElementsByTagName(in DOMString tagname);
Node importNode(in Node importedNode, in boolean deep) raises(DOMException);
Element createElementNS(in DOMString namespaceURI, in DOMString qualifiedName)
raises(DOMException);
Attr createAttributeNS(in DOMString namespaceURI, in DOMString qualifiedName)
raises(DOMException);
NodeList getElementsByTagNameNS(in DOMString namespaceURI, in DOMString localName);
Element getElementById(in DOMString elementId);
};
JAXP includes the W3C DOM package and a JAXP layer on top of it. This is similar to the SAX portion of JAXP described earlier:
org.w3c.dom. Defines the DOM interfaces and is specified by the W3C
javax.xml.parsers. Defines the DOM portion of JAXP, as Table 9.6 shows
|
DocumentBuilder |
A DOM parser capable of reading an XML document and constructing a DOM tree conforming to the DOM specification |
|
DocumentBuilderFactory |
A factory class used to obtain a reference to the DocumentBuilder and configure it if necessay using properties |
The DocumentBuilderFactory is used to obtain a reference to the underlying DOM parser-that is, the instance of the DocumentBuilder interface. It can be used to select from different parsers, although the current implementation comes with only one DOM parser. The event sequence that occurs when the factory is instantiated is similar to that described previously for the SAXParserFactory. First, the system property javax.xml.parsers.DocumentBuilderFactory is checked, then the lib/jaxp.properties file is checked for this property, following which the JAR files are searched for the META-INF/services/javax.xml .parsers.DocumentBuilderFactory file. If none of these is found, the default DocumentBuilderFactory of JAXP is used.
The code segment below shows the earlier SAXParsing example, adapted to show the basic structure used to create a DOM tree from an XML file. The flow remains the same: a DocumentBuilderFactory is created, a DocumentBuilder instance is obtained from it, and the XML is parsed using that instance.
package com.flutebank.parsing;
import java.io.File;
import javax.xml.parsers.*;
public class DOMParsing{
public static void main(String[] arg) {
try {
String filename = arg[0];
// Create a new factory that will create the SAX parser
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setValidating(validate);
factory.setNamespaceAware(true);
// Use the factory to create a DOM parser
DocumentBuilder parser = factory.newDocumentBuilder();
// Create a new handler to handle content
parser.setErrorHandler(new MyErrorHandler());
Document xml = parser.parse(new File(filename));
// Do something useful with the XML tree represented by the Document object
} catch (Exception e) {
System.out.println(e);
}
}
}
Usually, the DOM representation in memory is not an exact replica of the conceptual model. The primary disparity is that the tree includes Text nodes for ignorable white spaces (white space that falls between tags-e.g., a carriage return). The parsing code has to normalize the tree and handle these node types.