Before getting into the details of Web services, it is important to understand the history of computing systems and how they have evolved. Computer hardware has become more powerful, and more complex software is being built to take advantage of that power. However, the most striking aspect of the physical evolution of computing systems has been the advent of networking.
In the past, applications were initially limited to execution on one or a few interconnected machines. As networking grew, so did application size, complexity, and power. Today, vast interconnected computing resources on the Internet are available for applications to exploit. Yet the only way to do so is to develop new logical models for application development.
Traditionally, the main technique for managing program complexity has been to create more modular programs. Functions, objects, components, and services have allowed software developers to build units of reusable code whose implementations (data, behavior, and structure) are increasingly hidden from the consumer.
Another driving factor in this evolution is the business consumer's expectation that a company will provide more online access to information and a means for conducting business electronically. To satisfy this expectation, businesses have broadened the scope of their applications from small departments to the enterprise to the Internet. For instance, a company's inventory system became online procurement, and brochures became Web pages. Today, companies find themselves integrating enterprise applications to provide a single online experience for users.
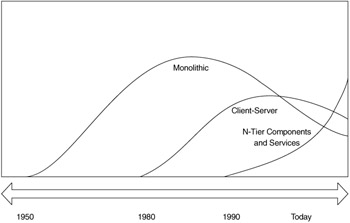
Historically, the physical evolution of systems has centered on the use of networking. Figure 1.1 and Table 1.1 show how faster and more available networks have changed the way applications are written. Networks connect multiple disparate computers into a distributed computing resource for a single application. In the early days, monolithic programs were written to run on a single machine. As departmental networks became popular, client-server and n-tier development became the standard. Now, the Internet has connected millions of computers into a vast sea of computing resources. Web services take advantage of this.
|
Monolithic |
Client-server |
N-tier |
WWW |
|
|---|---|---|---|---|
|
Data formats |
Proprietary |
Proprietary |
Open |
Standard |
|
Protocols |
Proprietary |
Proprietary |
Open |
Standard |
|
Scalability |
Low |
Low |
Medium |
High |
|
Number of nodes |
Very small |
Small |
Medium |
Huge |
|
Pervasiveness |
Not |
Somewhat |
Somewhat |
Extremely |
From the 1950s through the 1980s, programmers developed systems mostly on closed, monolithic mainframe systems, using languages such as COBOL and FORTRAN. These procedural methods for systems development, represented in Figure 1.2, required that all parts of a software system run on the same machine and that the program have direct access to the data upon which it was acting. The software was developed in a handful of languages and required an intricate knowledge of the physical storage of the data.
Software designers and programmers quickly realized that system and software decomposition were necessary to deal with software complexity and change. They implemented structured programs and shared libraries of code to separate software systems into different modules. These modules still had many dependencies with each other, and change was still difficult to manage.
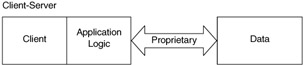
In the 1980s, client-server computing fostered a leap forward in the decomposition of system components. As Figure 1.3 shows, client-server developers separated the processor of the data (client) from the keeper of the data (server). This separation was both logical and physical. The client process retrieved the data from a server across a network connection. This enhanced flexibility, because the data was encapsulated into a database server. Database designers and administrators wrapped the data in referential integrity constraints and stored procedures to ensure that no client program could corrupt the data. The relational database also insulated the client from having to know the physical layout of the data.
However, the layers of the application that presented the data to the user were usually intermingled with the layers of the application that acted on the data in the database. More separation of the presentation from the data manipulation logic was necessary. N-tier development attempted to do this.
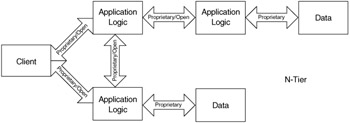
N-tier development, which started in the early 1990s, reduced the coupling between the client and the business logic. As Figure 1.4 shows, developers created a business-logic layer that was responsible for accessing data and providing application logic for the client. This additional layer also allowed multiple clients to access the business logic. The clients converse with the business logic tier in less interoperable protocols, such as DCOM.
CORBA was and still is a technology that made client interaction with the application layer more open and flexible. However, CORBA did not allow clients across the Internet to easily access internal application logic. The CORBA protocol is not firewall-friendly. CORBA also has not produced a large enough following to make it a universal standard for interoperability.
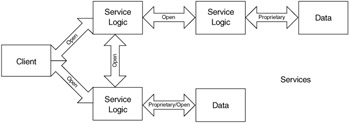
With the introduction of the World Wide Web, n-tier development has been taken a step further. As Figure 1.5 shows, developers create independent services accessible through the firewall. Services are modules that support one discrete function. For instance, a checking account service supports all the functions of managing checking accounts, and no other function. Clients interact with services using open technologies. Services are built from standard technologies, such as the ones used by the Internet. Applications are assemblies of services. Services do not "know" into which applications they are assembled.
The Internet itself has evolved and matured. Initially, it began as a way to publish scientific papers and was essentially static. The static system evolved into dynamic HTML, generated through CGI programs. Eventually, the dot-com era of the late 1990s brought a tremendous explosion of new technologies for creating full, robust Internet applications, including application servers such as J2EE and .NET.
Since its inception, software development has gone through several different logical models. Each development method shift, shown in Table 1.2, occurs in part to manage greater levels of software complexity. That complexity has been managed by continuously inventing coarser-grained software constructs, such as functions, classes, and components. These constructs are software "black boxes." Through an interface, a software black box hides its implementation by providing controlled access to its behavior and data. For example, objects hide behavior and data at a fine level of granularity. Components hide behavior and data at a coarser level of granularity.
|
Structured development |
Object-oriented development |
Component-based development |
Service-based development |
|
|---|---|---|---|---|
|
Granularity |
Very fine |
Fine |
Medium |
Coarse |
|
Contract |
Defined |
Private/public |
Public |
Published |
|
Reusability |
Low |
Low |
Medium |
High |
|
Coupling |
Tight |
Tight |
Loose |
Very Loose |
|
Dependencies |
Compile-time |
Compile-time |
Compile-time |
Runtime |
|
Communication scope |
Intra-application |
Intra-application |
Interapplication |
Interenterprise |
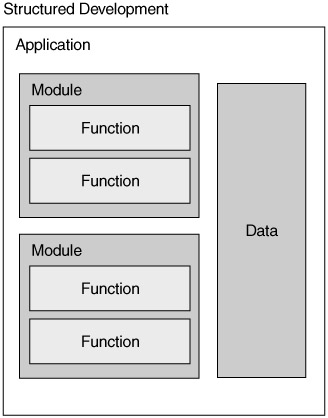
Structured design and development (Yourdon and Constantine 1975), diagrammed in Figure 1.6, involves decomposing larger processes into smaller ones. Designers break down larger processes into smaller ones to reduce complexity and increase reusability. Structured design addresses the behavior portion of a software system separately from the data portion. Breaking down a program's structure helps develop more complex applications, but managing data within the application is difficult, because different functions act on much of the same data.
Structured development helps hide information about a program's structure and processes but does not hide details of the data within the program. A standard design principle known as information hiding (Parnas 1972) involves limiting the knowledge one part of a program has about another part. This includes data, data formats, internal structures, and internal processes. Object-oriented development allows developers to hide program behavior and data inside objects.
Object-oriented development (Booch 1990), represented by Figure 1.7, allows software designers and developers to encapsulate both data and behavior into classes and objects. This places the data near the code that acts on the data and reduces the dependencies between objects. An additional benefit to object orientation is that software structures more easily map to real-world entities. Object-based development advances the information-hiding principles of software design by providing more support for hiding behavior and data.
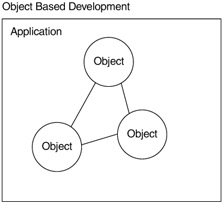
However, a large number of interconnected objects create dependencies that can be difficult to manage. In a large system, objects tend to know a lot about each other's structures and internal states. Objects are relatively fine-grained. Although interfaces control access to object internals, a large number of fine-grained objects make dependencies difficult to control in large applications. Component-based development helps construct large object-oriented applications.
Components are larger and coarser grained than objects and do not allow programs to access private data, structure, or state. Component-based development allows developers to create more complex, high-quality systems faster than ever before, because it is a better means of managing complexities and dependencies within an application.
Szyperski (1998) defines a software component as "a unit of composition with contractually specified interfaces and explicit context dependencies only. A software component can be deployed independently and is subject to composition by third parties." A component is a small group of objects with a contractually specified interface, working together to provide an application function, as shown in Figure 1.8. For example, a claim, automobile, and claimant object can work together in a claims component to provide the claim function for a large insurance application. The claim and automobile objects are not accessible to any other part of the system except the claim component. This means that no other part of the system can become dependent on these objects, since they are completely hidden.
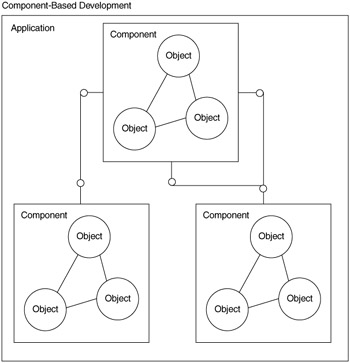
The protocols used to access components cannot easily pass through a firewall, making these protocols less interoperable. In addition, components are composed into applications at the time the developer compiles the program (compile time). An application that uses a component must have the interface definition at compile time, so the interface can be bound to and executed at runtime. Service-based development helps solve these problems.
With service-based development, represented in Figure 1.9, services are usually components wrapped in a service layer. A service tends to aggregate multiple components into a single interface and is thus coarser-grained. Also, the consumer of a service does not know the location or the interface of the service until runtime. This is called "late binding." The consumer finds the location of the service at runtime by looking it up in a registry, which also contains a pointer to the service contract. The contract describes the interface for the service and how to invoke it.
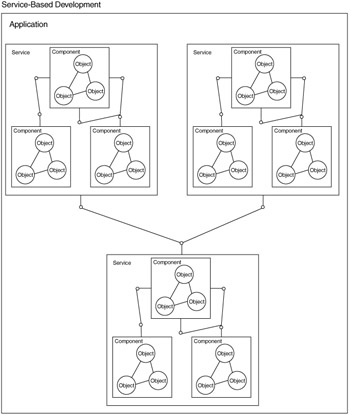
The service contract is discovered dynamically at runtime, bound to, and then executed. This feature of service-based development allows the consumer to perform real-time contract negotiation with several services in a dynamic fashion. For example, if several credit-card authorization services are available, the service consumer may use the service that offers the best rate for the transaction at the moment of execution.
While pure runtime binding is possible, it is important to note that many service consumers use the service contract to generate a proxy class at compile time that is used at runtime. When service consumers use this method to invoke a service, the service consumers are technically bound to the service contract at compile time.
Service-based development has solved the interoperability issue by adopting Web-based interoperability standards. Web services use the HTTP protocol to transfer data and XML for the data format. This allows service requests to easily pass through firewalls. Service-based development has been enabled through the advent of the Internet, the World Wide Web, and the ubiquitous technologies they have promoted. As we will see in Chapter 2, services have also realized true information hiding between parts of the application. This is done by separating the service's interface from its implementation.
In addition, the potential for reusing services in applications has greatly increased, because of the use of standard technologies, which have also enabled broader interorganization service use. Standards bodies have formed to develop definitions for XML messaging within trading partner communities, to externalize the semantics of services. Trading partners adopt these messaging standards rather than creating their own. The data formats are standardized by external bodies, which reduces idiosyncrasies in the way an organization's services must be used. This allows organizations to use each other's services more freely.