Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Language Analysis and ParsingBefore the user can type anything, we must define a "language" that he/she must stay within. This language consists of vocabulary and a set of rules (grammar). Together, these conventions create the overall language. Now, the whole idea of a text game is to use the English language. This means that the vocabulary should be English words and the grammar should be legal English grammar. The first request is easy. The second request is much harder. Contrary to the belief of many of my English teachers, the English language is a terribly complex language system. It's full of contradictions, points of view, different ways of doing things, and so on. In general, the English language is not robust and exact like computer languages. This means that as text-game programmers, we may have to allow the user only a very small subset of the possible grammatical constructions that could be made with a given vocabulary. This may seem like a problem, but it's not. A player of a text game gets very comfortable very quickly with a more robust, well-defined subset of English and finds that the sentences are concise and to the point. With all that in mind, the first thing that any game needs is a vocabulary. This is constructed in an ongoing manner as the game is written. The reason for this is that as the game is being written, the designer may feel that another game object needs to be added such as a "zot." This would mean that "zot" would have to be added to the vocabulary if the player were ever to be able to refer to it. Secondly, the designer might decide that more prepositions are needed to make some sentences more natural. For example, to drop an object, the player might type: "drop the keys" The meaning of this is very clear. The word "drop" is a verb, "the" is a worthless article, and "keys" is a noun. However, it might be more natural for the player to type: "drop down the keys" or "drop the keys down" Regardless of whether these two sentences are as "good," the fact of the matter is this is how people talk and that is all that is important. Therefore, the vocabulary will need words for all the objects in the game (nouns) along with a few good prepositions. As a rule of thumb, start with the prepositions of everything you can do to a mountain and that will usually suffice. Table 14.2 is a list of common prepositions used in text games.
The next class of words needed in our vocabulary is the action verbs. These are the words that mean "do something." They are usually followed by a word or phrase that describes what the action is taking place on. For example, in a text game, the action verb "move" is very useful in navigating the player about the universe. A set of possible sentences using "move" as an action verb might be
Sentence number 1 is simple enough. It says to move to the north. The second sentence also says to move to the north, but it has a prepositional phrase "to the north." Finally, sentence number 3 uses the adjective "northward" to mean the same thing. Technically, it could be argued that each of the sentences could mean different things, but to us as game programmers, they all mean the same thing. And that is to take a step in the direction of north. Therefore, we see that the use of articles such as "the" and prepositions are absolutely needed to make the sentences have a little variety even if they all mean the same thing. Back to the subject of action verbs. The game should have a large list of action verbs (many of which can be used by themselves with implied objects). For example, say that the vocabulary for your game had the action verb "smell" in it. You might say, "smell the sandwich" which is clear. However, the command smell isn't so clear. Yes, it's clear what the player wants to do, but what he/she wants to smell is ambiguous. This is where the concept of context comes into play. Since there is no direct or indirect object given to "smell," the game will assume that the player means the exterior environment or the last object acted upon. For example, if the player just picked up a rock, and then requested the game engine to "smell," the game might reply, "the rock?" and then the player would say "yes" and the proper description string would be printed. On the other hand, if the player hadn't recently picked up anything then the single command "smell" might elicit a general description of the smell within the room that the player is standing in. After you have decided on all the action verbs, nouns, prepositions, and articles that can be used in the language, the rules for the language itself must be generated. These rules describe the possible sentence constructions that are legal, and this information is used by the syntactical analyzer along with the semantic analyzer to compute the meaning of the sentence along with its validity. As an example, let's generate a vocabulary along with the rules (grammar) that govern it (see Table 14.3).
The "type name" is used to group similar word types, so they can be worked with more efficiently. Now that we have the vocabulary, let's construct the language with it. This means creating the rules for legal sentences. Not all these sentences may make sense, but they will all be legal. These rules are usually referred to as "the syntax of the language" or the productions. I prefer to call them productions (see Table 14.4).
Where the "|" means logical OR, "+" means concatenate, and NULL means NULL string. Now if you try to build sentences using the production for "SENTENCE," then there are quite a few sentences that can be constructed. However, some of them may not make any semantic sense. For example, the sentence "put the rock onto the table" makes perfect sense, but the sentence "get the rock onto the table" is unclear; it could mean place the rock on the table. This is where one of two things must be done: Either more productions must be incorporated into the language to separate specific verbs and their constructions, or the game code must test to see if sentences make "sense." To make sure you see how the productions are used, let's do a few examples of legal sentences (see Table 14.5).
As you can see from the table, if a production doesn't exist for a particular sentence form, then the sentence is illegal regardless of whether it makes sense. This is because the computer will not know that it is a legal sentence unless there is an implementation of the production or syntactic rule that governs the construction of the desired sentence. To put it another way, you must program in every single sentence type as a logical construction of the elements in the vocabulary, and you must be able to test each sentence to see if it follows the production rules. Of course, I was joking about the "clearly" part! Once the sentence has been broken down and the meaning is starting to become clear, then comes the semantic checking. This phase tests if a valid sentence makes sense. For example, the sentence "get the key onto the table" is a legal construction, but it is unclear what the user wants. It should probably be flagged as unclear and the user should be requested to say it in another way, possibly: "put the key on table" The question that should be burning in your mind is, "How do I make the program do what the sentence says to do after I have figured out what the user wanted to say?" The answer is with action functions. Action functions are called based on the action verb of the sentence. These action functions can act as syntax checkers, semantic checkers, or a combination of both or neither (it's up to you). But, one thing the action function should do is make something happen. This is accomplished by having a separate function for each action function. The action functions themselves are responsible for figuring out what object(s) the action verb is supposed to be applied to and then performing the requested action. For example, the action function for the verb "get" might step through the following set of operations:
The first step (extracting the object) is accomplished by "consuming" words that don't change the meaning of the sentence. For instance, the prepositions and articles in our language Glish don't change the meaning much of any particular sentence. Take a look below: "put the key" The article "the" can be taken out of the sentence without changing the meaning. This consumption of irrelevant words is transparent to the player, but allows him/her to write sentences that make more sense from his point of view. Even though our language parser might like "put key on table" a human player may feel more comfortable with "put the key onto the table" In any case, the action function will take care of this logic. Once the action function has figured out what needs to be done, doing it is easy. In the case of the original example of getting something, the object would be taken out of the universe database and inserted into the player's inventory, where the player's inventory might just be an array of characters or structures that list the objects the player is holding. For example, in the game Shadow Land, the player's inventory and everything about him is contained within the single structure shown in Listing 14.2. Listing 14.2 The Structure That Holds the Player in Shadow Land
// this structure holds everything pertaining to the player
typedef struct player_typ
{
char name[16]; // name of player
int x,y; // position of player
int direction; // direction of player, east,west north,south
char inventory[8]; // objects player is holding (like pockets)
int num_objects; // number of objects player is holding
} player, *player_ptr;
The inventory in this case is an array of characters that represent the objects the player is holding. For example, 's' stands for sandwich. This data structure is just an example; you may want to do it differently. In essence, all a text game has to do is break a sentence down, figure out the action requested, call the appropriate action function(s), and perform the action. Performing the action is accomplished by updating data structures, changing coordinates, and printing out text. The majority of the problem in a text game is the translation of the input command string into something the computer can deal with, such as numbers (as you have probably surmised). This process is called tokenization or lexical analysis and is the next topic of discussion. Lexical AnalysisWhen the player types in a sentence using the vocabulary we supply him with, the sentence must be converted from strings into tokens (integers) so that syntactic and semantic phases of analysis can proceed. The reason lexical analysis is necessary is due to the fact that working with strings is much more difficult, time consuming, and memory intensive than working with tokens (which are usually integers). Hence, one of the functions of the lexical analyzer is to convert the input sentence from string form to token form. There are three parts to this translation. The first part of lexical analysis is simply separating the "words" in a sentence and extracting them. By words, it is meant strings of characters separated by "white space." White space is usually considered to be the space character (ASCII 32) and the horizontal tab (ASCII 9). For example, the sentence "This is a test." has four words (tokens). They are
We also see that periods will have to be taken into consideration since they separate sentences. If the user is going to be inputting only a single line at a time, he may or may not put a period at the end of each input sentence. Alas, the period can be thought of as white space. On the other hand, if it is legal for the player to type multiple commands separated by a period or other phrase separator like the colon ":" or semi-colon ";" then extra logic may be needed since the sentences should be parsed separately. For example, if the period is assumed to be white space in a single sentence construction, as in "This is a test." then the meaning to the parser is the same as "This is a test" However, when two sentences are placed next to each other with the period being interpreted as white space, then the following problem can occur. This sentence "This is a test. Get the book." will be interpreted as "This is a test get the book" which has no meaning. The moral of the story is to be careful what you elect to call "white space" and what you don't. Moving on, we need to figure out a way to extract the "words" in a sentence that are separated by white space. The C library actually has a string function to do this, called strtok(), but it doesn't work properly on some compilers and we will summarily dismiss it since we like to re-invent the wheel. What we need is a function that will separate the words out for us. This is actually a fairly easy function to write as long as you take your time and take all the cases into consideration that can occur, such as NULL terminators, white space, and the return character. Anyway, Listing 14.3 is one such implementation of a token extraction function. Listing 14.3 A Function to Extract Tokens from an Input Sentence (Excerpted from Shadow Land)
int Get_Token(char *input,char *output,int *current_pos)
{
int index, // loop index and working index
start, // points to start of token
end; // points to end of token
// set current positions
index=start=end=*current_pos;
// eat white space
while(isspace(input[index]) || ispunct(input[index]))
{
index++;
} // end while
// test if end of string found
if (input[index]==NULL)
{
// emit nothing
strcpy(output,"");
return(0);
} // end if no more tokens
// at this point, we must have a token of some kind, so find the end of it
start = index; // mark front of it
end = index;
// find end of Token
while(!isspace(input[end]) && !ispunct(input[end]) && input[end]!=NULL)
{
end++;
} // end while
// build up output string
for (index=start; index<end; index++)
{
output[index-start] = toupper(input[index]);
} // end copy string
// place terminator
output[index-start] = 0;
// update current string position
*current_pos = end;
return(end);
} // end Get_Token
The function takes three inputs: an input string to be parsed, an output string that holds the token extracted, and the current position in the string that is being processed. For example, let's see how a string can be parsed using the function. First we need to declare a couple of variables:
int position=0; // used as index from call to call
// to keep track of current string
// position
char output[16]; // output string
// begin program
Get_Token("This is a test",output,&position);
After this call, the variable output would have a "This" in it and position would be equal to 4. Let's do one more call…
Get_Token("This is a test",output,&position);
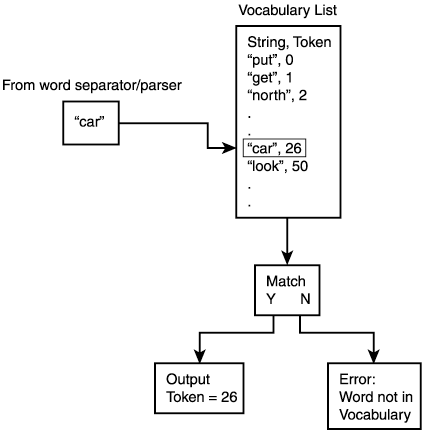
Now, the variable output would have "is" in it and position would now be updated to 7. If Get_Token() is repeatedly called in this fashion, each "word" in the sentence will be extracted and be placed in the buffer output (of course, each previous string in output will be overwritten by the next token word). Consequently, we now have a method of obtaining the "words" that make up a sentence. The next task is to convert these strings into integer tokens so that they can be worked with more easily. This is done with a function that has a table of strings along with the token for each of the vocabulary words. A search through the table is done for each word and when and if the string is found in the table, then it is converted to an integer token (see Figure 14.2). Figure 14.2. A word being tested to see if it's in the vocabulary of the game.
During this phase of lexical analysis is where the vocabulary checking is done. If a word is not in the vocabulary, then it is not in the language and hence is illegal. As an example, the game Shadow Land has the following data structure to hold each word in the vocabulary (see Listing 14.4). Listing 14.4 The Data Structure for a Token in Shadow Land
// this is the structure for a single token
typedef struct token_typ
{
char symbol[16]; // the string that represents the token
int value; // the integer value of the token
} token, *token_ptr;
This structure has a place for both the string and a value to be associated with it. The string is the actual vocabulary word, while the value is arbitrary. However, the values for tokens should be mutually exclusive unless you wish to make words synonyms. Using the above structure and some defines, you can create a vocabulary table in very compact form that can be used as a reference in the lexical analysis to convert words to tokens and to check their validity. Listing 14.5 is the vocabulary table used in Shadow Land. Listing 14.5 The Static Initialization of the Vocabulary Table for Shadow Land
// this is the entire "language" of the language in Shadow Land.
token language[MAX_TOKENS] = {
{"LAMP", OBJECT_LAMP } ,
{"SANDWICH", OBJECT_SANDWICH } ,
{"KEYS", OBJECT_KEYS } ,
{"EAST", DIR_1_EAST } ,
{"WEST", DIR_1_WEST } ,
{"NORTH", DIR_1_NORTH } ,
{"SOUTH", DIR_1_SOUTH } ,
{"FORWARD", DIR_2_FORWARD } ,
{"BACKWARD", DIR_2_BACKWARD } ,
{"RIGHT", DIR_2_RIGHT } ,
{"LEFT", DIR_2_LEFT } ,
{"MOVE", ACTION_MOVE } ,
{"TURN", ACTION_TURN } ,
{"SMELL", ACTION_SMELL } ,
{"LOOK", ACTION_LOOK } ,
{"LISTEN", ACTION_LISTEN } ,
{"PUT", ACTION_PUT } ,
{"GET", ACTION_GET } ,
{"EAT", ACTION_EAT } ,
{"INVENTORY", ACTION_INVENTORY} ,
{"WHERE", ACTION_WHERE } ,
{"EXIT", ACTION_EXIT } ,
{"THE", ART_THE } ,
{"IN", PREP_IN } ,
{"ON", PREP_ON } ,
{"TO", PREP_TO } ,
{"DOWN", PREP_DOWN } ,
} ;
As you see, there are character strings followed by defined symbols (the value of which are irrelevant as long as they are different). You will notice the defined symbols have familiar prefixes such as PREP (preposition), ART (article), and ACTION (verb). Once a table like this exists in some such form, the token strings can be compared to the elements in the table and the character strings representing the tokens can be converted to integers. At that point, the input sentence will be a string of numbers, which can be processed in a more convenient fashion. A sample tokenizer is shown in Listing 14.6. It is also from the game Shadow Land, but if you have seen one, you have seen them all. Don't worry about the defined constants, just concentrate on the overall operation of the function. Listing 14.6 A Function That Converts Token Strings of an Input Sentence into Integer Tokens
int Extract_Tokens(char *string)
{
// this function breaks the input string down into tokens and fills up
// the global sentence array with the tokens so that it can be processed
int curr_pos=0, // current position in string
curr_token=0, // current token number
found, // used to flag if the token is valid in language
index; // loop index
char output[16];
// reset number of tokens and clear the sentence out
num_tokens=0;
for (index=0; index<8; index++)
sentence[index]=0;
// extract all the words in the sentence (tokens)
while(Get_Token(string,output,&curr_pos))
{
// test to see if this is a valid token
for (index=0,found=0; index<NUM_TOKENS; index++)
{
// do we have a match?
if (strcmp(output,language[index].symbol)==0)
{
// set found flag
found=1;
// enter token into sentence
sentence[curr_token++] = language[index].value;
break;
} // end if
} // end for index
// test if token was part of language (grammar)
if (!found)
{
printf("\n%s, I don't know what \"%s\" means.",you.name
,output);
// failure
return(0);
} // end if not found
// else
num_tokens++;
} // end while
} // end Extract_Tokens
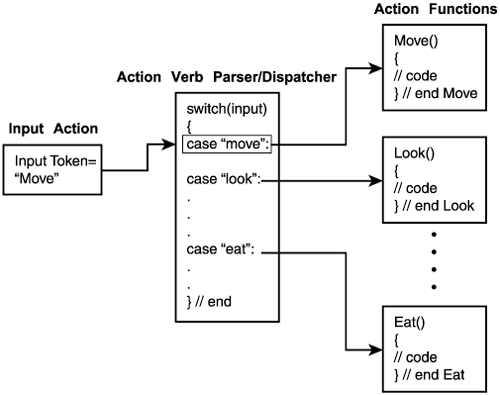
The function operates with an input string passed to it containing the user's commands. The function then proceeds to break the sentence down into separate "words" using the Get_Token() function. Each word is then scanned for in the vocabulary table, and when a match is made, the word is converted into a token and inserted into a token sentence, which is basically a version of the input sentence in token form (integers instead of strings). If the "word" is not found in the vocabulary table, then there is a problem and the code will emit an error. I have highlighted this section in the function above, so that you may see how easy it is. Let's take a brief detour for a moment to cover two topics. The first is error handling. This is always an important part of any program, and I can't emphasis how important it is especially in a text-based game where a bad input can "trickle" down into the bowels of the game engine and logic and really mess things up (you Perl scripters should know something about this). Therefore, it can't hurt to have too much error checking in a text game. Even if you are 99% sure an input to a function should be of the correct form, always test that one last case to make sure. Secondly, you will notice that I use very primitive data structures. Sure, a linked list or binary tree might be a more elegant solution, but is it really worth it for a dozen or so vocabulary words? The answer is no. My rule of thumb is that the data structure should fit the problem and arrays fit a lot of small problems. When the problems get large, then it's time to bring in the big guns such as linked lists, B-trees, graphs, and so forth. But for small problems, get the code working with simple data structures or else you will be forever trying to figure out why you keep getting NULL pointer errors, GP faults, and other bothersome features! All right, now that we finally know how to convert the sentence into tokens, it's time for the syntactic and semantic analysis phases—let's cover the syntactic phase first. Syntactical AnalysisHold on tight because here is where things start getting a bit cloudy. Strictly speaking, syntactic analysis is defined in compiler texts as the phase where the input token stream is converted into grammatical phrases so that these phrases can be processed. Since the languages we have been considering for implementation are fairly simple and have simple vocabularies, this highly general and elusive definition needs to be pruned down to mean something in our context. As far as we are concerned, syntactic analysis will mean "making sense out of the sentence." This means applying the verbs, determining the objects, extracting the prepositions, articles, and so on. The syntactic analysis phase of our games will occur in parallel with the action(s) processing of the sentence. This is totally acceptable, and many compilers and interpreters are designed in this way. The code is generated or interpreted "on the fly." We have already seen what the syntactic phase of analysis looks like. It is accomplished by calling functions that are responsible for all the action verbs in the language. Then these action functions further process the remainder of the input sentence, which is already in token form, and then try to do whatever is supposed to be done. For example, a syntactic parser for a text game might begin by figuring out which action verb began the sentence and then calling an appropriate action function to deal with the rest of the sentence. Of course, the rest of the sentence could be processed and tested for validity before the call to the action function, but this isn't necessary. I prefer to place the burden of further processing on the action functions. My philosophy is this: Each action function is like an object that operates on a single kind of sentence. This single sentence is one that starts with a specific word. We shouldn't hold a single function responsible for checking the syntax of all the possible sentences before making the call to the appropriate action function. As an example, Listing 14.7 is the function used in Shadow Land to dispatch each sentence to the proper action function. The single purpose of this function is to look at the first word in the sentence (which is a token, of course) and then vector to the correct action function. At that point, it's the action function's job to check the rest of the syntax of the sentence. Here is the action dispatcher. Listing 14.7 The Function Used in Shadow Land to Call the Action Functions Based on the Action Verb Used in the Input Sentence
void Verb_Parser(void)
{
// this function breaks down the sentence and based on the verb calls the
// appropriate "method" or function to apply that verb
// note: syntactic analysis could be done here, but I decided to place it
// in the action verb functions, so that you can see the way the errors are
// detected for each verb (even though there is a lot of redundancy)
// what is the verb?
switch(sentence[FIRST_WORD])
{
case ACTION_MOVE:
{
// call the appropriate function
Verb_MOVE();
} break;
case ACTION_TURN:
{
// call the appropriate function
Verb_TURN();
} break;
case ACTION_SMELL:
{
// call the appropriate function
Verb_SMELL();
} break;
case ACTION_LOOK:
{
// call the appropriate function
Verb_LOOK();
} break;
case ACTION_LISTEN:
{
// call the appropriate function
Verb_LISTEN();
} break;
case ACTION_PUT:
{
// call the appropriate function
Verb_PUT();
} break;
case ACTION_GET:
{
// call the appropriate function
Verb_GET();
} break;
case ACTION_EAT:
{
// call the appropriate function
Verb_EAT();
} break;
case ACTION_WHERE:
{
// call the appropriate function
Verb_WHERE();
} break;
case ACTION_INVENTORY:
{
// call the appropriate function
Verb_INVENTORY();
} break;
case ACTION_EXIT:
{
// call the appropriate function
Verb_EXIT();
} break;
default:
{
printf("\n%s, you must start a sentence with an action verb!",
you.name);
return;
} break;
} // end switch
} // end Verb_Parser
The function is beautifully simple. It looks at the first word in the sentence (which by definition of the language better be a verb) and then calls the corresponding action function. For a graphical representation of this, take a look at Figure 14.3. The next part of parsing analysis is the semantic analysis phase. Figure 14.3. An action verb being dispatched to the proper action function.
Semantic AnalysisSemantic analysis is where most of the error checking takes place. However, since we are doing the syntactic analysis "on the fly" along with making things happen in the game, this responsibility is merged into the action function during syntactic analysis. Syntactic analysis is supposed to break down the sentence into its meaning and then semantic analysis is used to determine if this meaning makes sense (getting confused yet?!). As you can see, this business of syntactic and semantic analysis seems to be almost circular and therefore, again we will cut to the quick and make a hard and fast rule. In a text-based game, the syntactic and semantic analyses are done simultaneously. In other words, as the sentence's meaning is being computed, the sentence is tested to make sense. I hope you understand this very subtle concept. If it helps, it's kind of like snow skiing. It easy once you can do it, but until then you have no idea how to do it. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Ajax Editor
JavaScript Editor