Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
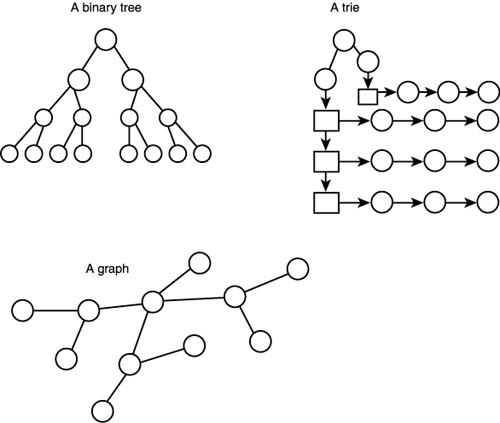
TreesThe next class of advanced data structures, trees, are processed by recursive algorithms, so that's why I took the preceding detour. Anyway, take a look at Figure 11.6 to see a number of different tree-like data structures. Figure 11.6. Some tree topologies.
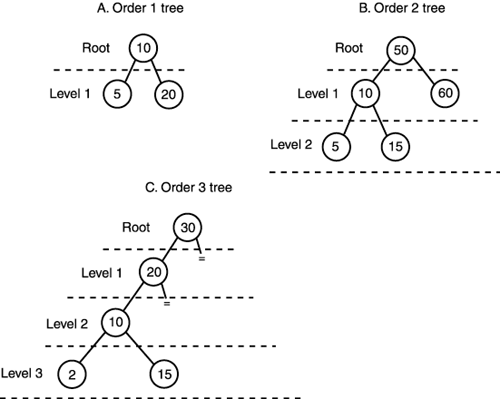
Trees were invented to help with the storage and searching of large amounts of data. The most popular kind of tree is the binary tree, AKA B-tree or BST (Binary Search Tree), a tree data structure emanating from a single root that is composed of a collection of nodes. Each node has one or two children nodes (siblings) descending from it; hence the term binary. Moreover, we can talk of the order or number of levels of a tree, meaning how many layers it has. The B-trees in Figure 11.7 are shown with their various orders. Figure 11.7. Some binary trees and their orders.
The interesting thing about trees is how fast the information can be searched. Most B-trees use a single search key to order the data. Then a searching algorithm searches the tree for the data. For example, say you wanted to create a B-tree that contained records of game objects, each with a number of properties. You could use the time of creation as the key, or you could make each node represent a person in a database. Here's the data structure that you would use to hold a single person node:
typedef struct TNODE_TYP
{
int age; // age of person
char name[32]; // name of person
NODE_TYP *right; // link to right node
NODE_TYP *left; // link to left node
} TNODE, *TNODE_PTR;
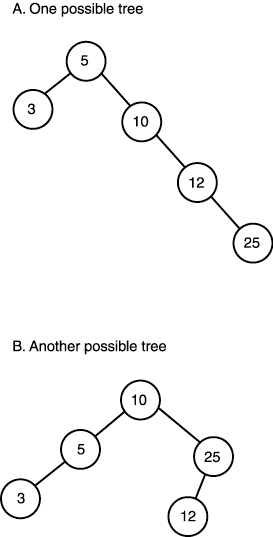
Notice the similarity between the tree node and the linked list node! The only difference is the way you use the data structure and build up the tree. Continuing with the example, let's say that you have five objects (people) with the following ages: 5, 25, 3, 12, and 10. Figure 11.8 depicts two different B-trees that contain this data. However, there are more you could create that would maintain the properties of a B-tree depending on the order that the data is presented to the insertion algorithm. Figure 11.8. B-tree encoding of data set age{ 5,25,3,12,10}.
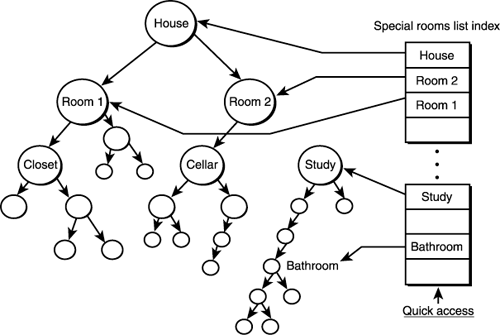
NOTE Of course, the data in this example can be anything you want. Notice that I have used the convention that any right child is greater than or equal to its parent and any left child is less than its parent. You can use a different convention, as long as you stick to it. Binary trees can hold enormous amounts of data, and that data can be searched very quickly with a binary search. This is a manifestation of the binary structure of the tree. For example, if you have a tree with one million nodes, at most it will take about 20 comparisons to find the data! Is that crazy or what? The reason for this is that during each iteration of your search, you cut half the nodes out of the search space. Basically, if there are n nodes, the average search will take log2 n; the run-time is O(log2 n). NOTE The statement about search time is only true for balanced trees—trees that have an equal number of right and left children per level. If a tree is unbalanced, it degrades into a linked list and search time degrades into a linear function. The next cool thing about B-trees is that if you take a branch (sub-tree) and process it separately, it maintains the properties of a B-tree. Hence, if you know where to look, you can search a sub-tree just for whatever it is you're looking for. Thus, you can create trees of trees or index tables that contain sub-trees so you don't need to process the whole tree. This is important in 3D world modeling. You might have one large tree of the entire world, but there are hundreds of sub-trees that represent rooms in the world. Thus, you might have yet another tree that represents a spatially sorted list of pointers into the sub-trees, as shown in Figure 11.9. More on this later in the book…. Figure 11.9. Using a secondary index table on a B-tree.
Finally, let's address when to use trees. I suggest using tree-like structures when the problem or data is tree-like to begin with. If you find yourself drawing out the problem and you see branches to the left and right, a tree is definitely for you. Building BSTsThis subject is rather complex due to the recursive nature of all the algorithms that apply to B-trees. Let's take a quick look at some of the algorithms, write some code, and finish with a demo. Similar to linked lists, there are a couple of ways to start off a BST: You can have a dummy root or a real root. I'll pick the real root because I prefer it. Hence, an empty tree has nothing in it but a root pointer pointing to NULL: TNODE_PTR root = NULL; Okay, to insert data into the BST, you have to decide what you're going to use as the insertion key. In this case, you can use the person's age or name. Use the person's age because these examples have been using age. However, using the name is just as easy; you would just use a lexicographic comparison function such as strcmp() to determine the order of the names. In any event, here's the code to insert into the BST:
TNODE_PTR root = NULL; // here's the initial tree
TNODE_PTR BST_Insert_Node(TNODE_PTR root, int id, int age, char *name)
{
// test for empty tree
if (root==NULL)
{
// insert node at root
root = new(TNODE);
root->id = id;
root->age = age;
strcpy(root->name,name);
// set links to null
root->right = NULL;
root->left = NULL;
printf("\nCreating tree");
} // end if
// else there is a node here, lets go left or right
else
if (age >= root->age)
{
printf("\nTraversing right...");
// insert on right branch
// test if branch leads to another sub-tree or is terminal
// if leads to another subtree then try to insert there, else
// create a node and link
if (root->right)
BST_Insert_Node(root->right, id, age, name);
else
{
// insert node on right link
TNODE_PTR node = new(TNODE);
node->id = id;
node->age = age;
strcpy(node->name,name);
// set links to null
node->left = NULL;
node->right = NULL;
// now set right link of current "root" to this new node
root->right = node;
printf("\nInserting right.");
} // end else
} // end if
else // age < root->age
{
printf("\nTraversing left...");
// must insert on left branch
// test if branch leads to another sub-tree or is terminal
// if leads to another subtree then try to insert there, else
// create a node and link
if (root->left)
BST_Insert_Node(root->left, id, age, name);
else
{
// insert node on left link
TNODE_PTR node = new(TNODE);
node->id = id;
node->age = age;
strcpy(node->name,name);
// set links to null
node->left = NULL;
node->right = NULL;
// now set right link of current "root" to this new node
root->left = node;
printf("\nInserting left.");
} // end else
} // end else
// return the root
return(root);
} // end BST_Insert_Node
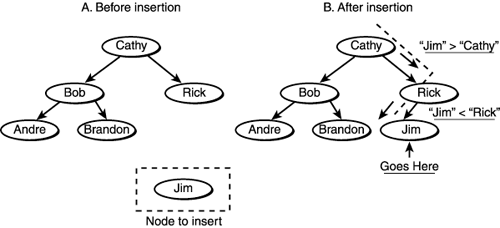
Basically, you first test for an empty tree and then create the root, if needed, with this first item. Hence, the first item or record inserted into the BST should represent something that is in the middle of the search space so that the tree is nicely balanced. Anyway, if the tree has more than one node, you traverse it, taking branches to the right or left depending on the record that you're trying to insert. When you find a leaf or terminal branch, you insert the new node there: root = BST_Insert_Node(root, 4, 30, "jim"); Figure 11.10 shows an example of inserting "Jim" into a tree. Figure 11.10. Inserting into a BST.
The run-time performance of an insertion into the BST is the same as searching it, so an insertion will take O(log2 n) on average and O(n) in the worst case (when the keys happen to fall in linear order). Searching BSTsOnce the BST is generated, searching it is a snap. However, this is where you need to use a lot of recursion, so watch out, dog. There are three ways to search a BST:
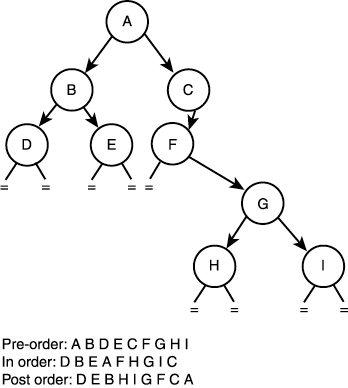
NOTE Right and left are arbitrary; the point is the order of visiting and searching. Take a look at Figure 11.11. It shows a basic tree and the three search orders. Figure 11.11. The order of node visitation for preorder, inorder, and post-order searches.
With that in mind, you can write very simple recursive algorithms to perform the traversals. Of course, the point of traversing a BST is to find something and return it. However, the following function just performs the traversals. You could add stopping code to the functions to stop them when they found a desired key; nevertheless, the way you search for the key is what you're interested in at this point: void BST_Inorder_Search(TNODE_PTR root) { // this searches a BST using the inorder search // test for NULL if (!root) return; // traverse left tree BST_Inorder_Search(root->left); // visit the node printf("name: %s, age: %d", root->name, root->age); // traverse the right tree BST_Inorder_Search(root->right); } // end BST_Inorder_Search And here's the preorder search: void BST_Preorder_Search(TNODE_PTR root) { // this searches a BST using the preorder search // test for NULL if (!root) return; // visit the node printf("name: %s, age: %d", root->name, root->age); // traverse left tree BST_Inorder_Search(root->left); // traverse the right tree BST_Inorder_Search(root->right); } // end BST_Preorder_Search And finally, the postorder search: void BST_Postorder_Search(TNODE_PTR root) { // this searches a BST using the postorder search // test for NULL if (!root) return; // traverse left tree BST_Inorder_Search(root->left); // traverse the right tree BST_Inorder_Search(root->right); // visit the node printf("name: %s, age: %d", root->name, root->age); } // end BST_Postorder_Search That's it—like magic, huh? So if you had a tree, you would do the following to traverse it in order: BST_Inorder_Search(my_tree); TIP I can't tell you how important tree-like structures are in 3D graphics, so make sure you understand this material. Otherwise, when you build binary space partitions to help solve rendering problems, you're going to be in pointer-recursion hell. :) You'll note that I have conveniently left out how to delete a node. This was intentional. It's a rather complex subject because you could kill a sub-tree's parent and disconnect all the children. Alas, deletion of nodes is left as an exercise for you to discover on your own. I suggest a good data structures text, such as Algorithms in C++ by Sedgewick, published by Addison Wesley, for a more in-depth discussion of trees and the associated algorithms. Finally, for an example of BSTs, check out DEMO11_3.CPP|EXE. It allows you to create a BST and traverse it using the three algorithms. Again, this is a console application, so compile it appropriately. |
|
|
Ajax Editor
JavaScript Editor