Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Fundamental Data Types3D pipelines are built on top of a number of basic data types, which are common regardless of the API in use. In the following sections, a concise list is provided, which should provide some "common ground" for the rest of the book. VerticesVertices are usually stored in XYZ coordinates in a sequential manner. The most frequent format uses the float type, which provides enough precision for most uses. Some applications will require using doubles for special calculations, but most of today's graphic processing units (GPUs) will only use floats as their internal format. Vertices are of little use individually. But in a serial way, they can be used to explicitly enumerate the vertices of a 3D object. A list of vertices can be interpreted, taking them in triplets as a sequence of triangles composing a 3D solid mesh. So the representation would be something like this:
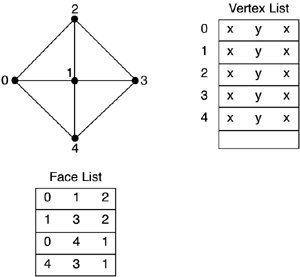
A variant of this method can be used for primitives with triangles that share vertices between their faces. Take a cube from (-1,-1,-1) to (1,1,1), for example. As you already know, a cube consists of 8 vertices and 6 faces, totaling 12 triangles. Using our initial approach, we would code this cube by enumerating the 3 vertices of each one of the 12 faces. This would yield a list of 36 entries. Because each vertex is 3 floats, and a float is 4 bytes, we have a total memory footprint for the cube of 36x3x4 = 432 bytes. Indexed PrimitivesNow, let's follow a different approach. We are repeating the same vertices many times in the list using this initial representation. A single vertex can appear as many as six times because it belongs to different triangles (see Figure 12.1). To avoid this repetition, let's put the vertices in a list (with no repetition), and then use a second list to express the topology of the faces. We will then have two lists: The first one will contain exactly eight vertices (remember, no repetition). The second one will be a list of the face loops required to build the cube. For each triangle, we will write down not the vertices themselves, but the position on the first list where they can be found. Figure 12.1. A sample mesh with its vertex and face lists.
This second list is called the index list because it provides you with the indices of the vertices for each face. If we are coding a cube, the index list will be 36 elements long (12 faces, each with 3 vertices). Each element will be a 16-bit unsigned integer value. Now we are ready to do some math and compare the results of the classic versus indexed coding. For this new variant, we will have
So, the whole cube will take up 96 + 72 = 168 bytes, which is roughly 40 percent of what it would require using the classic method. These results can be extrapolated to higher complexity meshes, with triangle indexing cutting the memory footprint in half, approximately. Triangle indexing is a very good technique to use to reduce memory footprint for your games. Most 3D packages can directly export indexed primitives, which you can plug into your engine. Indexing is essential for economizing memory in memory-limited platforms (read: all of them), but is also relevant to your engine's performance. Do not forget that data transfer through the bus has a cost, which depends on the amount of data. Thus, sending half the data is approximately twice as fast. Moreover, this technique has an additional advantage: Most graphics cards and applications have internal support for indexed primitives, so it all becomes a cradle-to-the-grave solution. All phases in the pipeline can work with this efficient strategy, yielding an overall improvement on the performance and the memory use at zero CPU cost. They say every rose has its thorn, so it shouldn't surprise us that this technique has a potential problem. As you will soon see, texture coordinates and materials, which are essential to convey a sense of realism, are applied to vertices on a triangle basis. Imagine a vertex shared by two faces that have different material identifiers and texture coordinates depending on the triangle you are looking at. Handling these situations in an indexed list is an additional burden. You need to reenter the vertex in the vertex list as many times as the different "impersonations" it appears under. If it's shared between four triangles, each one with different texture coordinates and materials, that vertex must appear as many as four times in your vertex list. QuantizationVertex indexing can reduce the memory hit in 3D meshes at no cost. There is no CPU overhead involved, nor does the data suffer any loss of quality in the process. Now we will explore a different technique aimed in the same direction. This time we will be using a lossy technique (meaning some quality will be lost along the way). Under the right circumstances, we will be able to minimize the loss and achieve additional gain, keeping a very good quality. The method is data quantization. The core idea behind quantization is very simple: Keep the data compressed in memory, and uncompress it whenever you need to use it. In fact, quantization is really the name of the compression scheme, but the overall compress-in-memory philosophy could be implemented with other compression schemes as well. The reason it's called quantization is because this specific compression technique is very fast, so it can be used in real-time applications. Decompressing a different format (say, ZIP files) would definitely have a significant processing time, which makes it less attractive to game developers. Quantizing can be defined as storing values in lower precision data types, thus saving precious space in the process. You can downsample a double to a float, and you will be taking up half the memory space. You will have lost bits of precision along the way, but in many cases, that extra precision conveyed little or no information anyway, so the results look almost identical. However, quantizing does not usually involve doubles and floats. Those types have good precision and usually can fit any value perfectly. Quantizing has more to do with coding floats into unsigned shorts (16 bits) or even unsigned bytes (8 bits). For example, imagine that you want to store the geometry for a human being. You have modeled him in a 3D package and centered his feet in the origin. Thus, you can expect him to be bound by a box 2 meters high, 80 centimeters wide, and maybe 50 centimeters deep. In other words, the vertex coordinates you will be storing are (assuming you model in meters):
Then, if you store each vertex coordinate in a floating-point value, chances are you will be using IEEE 754-compliant floats (IEEE is the Institute of Electrical and Electronics Engineers, and 754 is the name of the standard). Under this standard, a floating-point value is encoded in a 32-bit sequence consisting of:
As a result of this coding scheme, the range of the float type is, as specified in the standard: +- (3.4E–38 to 3.4E+38) which means you can represent incredibly small and very large numbers on both the positive and negative ends of the spectrum. But we don't need to encode a huge number. We are only trying to encode numbers in a 2-meter range at most. So, do we really need to occupy that much storage space? Let's try a different way. Take a smaller precision data type (shorts or bytes usually) and encode the floating-point coordinates into that data type. For example, to encode numbers in the range from MINVALUE to MAXVALUE, we could do the following: Compressed_value=Compressed_type_size*(original_value-minvalue)/(maxvalue-minvalue) This would map the float value range limited by MIN and MAX linearly to the compressed type. For example, to encode the Y value of our human model into unsigned shorts (16 bits), we would do the following, because an unsigned short is in the range of 0 to 65535 (2^16 – 1): Compressed_value=65536*(original_value-0)/(2-0) Using this approach, we would divide by two the memory requirements for our geometry, but would lose some precision in the process. If we do the math, we will see that the loss of precision is relatively small. Generally speaking, the precision of a quantization will be Precision = (MAXVALUE-MINVALUE)/Compressed_type_size which in this case yields a precision of: Precision = 2/65535= 0,00003 This is about three hundredths of a millimeter. We can even compress this into a byte, yielding the following:
Compressed_value=255x(original_value-0)/(2-0)
Precision = 2/256 = 0,007 meters
So the maximum error we can incur when compressing is about 7 millimeters, which is quite likely acceptable for many uses. The decompression routine (sometimes called "reconstruction") is again relatively simple and follows the equation: Reconstructed_value=Precision*compressed_value+Min_value There are several strategies for both compression and reconstruction that have slightly different results and side effects. The one I recommend using is called the TC method (because it truncates and then centers). Scale to the desired value (in the following example, a byte) and truncate the floating point to an integer. Then, to decode, decompress by adding 0.5 to make each decompressed value stay in the middle of its interval:
unsigned char encodeTC (float input)
{
float value = (input-input_min)/(input_max-input_min);
unsigned char = (int)(value * 255);
return result;
}
float decodeTC(int encoded)
{
float value= (float)(encoded + 0.5f)/255;
return value* (input_max - input_min) + input_min;
}
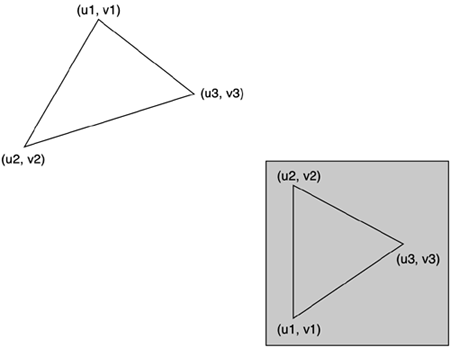
Color3D games mainly use the RGB (or RGBA) color space. For simple applications and demos, using floating-point values is again the format of choice. Using floats is handy if you need to work with software illumination algorithms or need to do color interpolation. Usually, floats are restricted to the range from 0 to 1 in each of the three components, with black being (0,0,0) and white being (1,1,1). The other color spaces, such as Hue-Saturation-Brightness, Cyan-Magenta-Yellow, and so on are mostly useful when working in printed media or to perform image-processing algorithms. So, they are used in games only on very few occasions. Coding colors in float values is somehow an excess. If you remember the explanation about quantization, the same ideas can be applied here: We have way too much range and precision, which we are not taking advantage of. Also, with RGB screens working in 24-bit modes, it doesn't make much sense to deliver color values to the GPU in anything but bytes. Any additional bits of information will be discarded, so the extra precision provided by floats will not make any difference in the final output. Additionally, colors coded as bytes are internally supported by most APIs and GPUs, so no decompression/reconstruction is required. Again, we have a winning strategy with no undesired side effects. In some special cases, you will work with BGR (and consequently, BGRA) formats. This is a regular RGB stream where you must swap the red and blue bytes before displaying. BGR colors are used for historical reasons in some applications and texture formats—one being the very popular Targa texture format. Always keep this in mind if you don't want inaccurate colors onscreen. As a helper, some APIs, like OpenGL, support these new formats internally as well, so no manual swapping is really required. In addition, some applications do not use color but instead use luminance values. For example, you might want to store only the grayscale value of the color so you can use it for static lighting. By doing so, you are losing the chromatic information, but you can save even more memory. However, you will need to decompress in a full RGB triplet if your API of choice cannot use luminance data directly. AlphaAlpha encodes transparency and can be associated with the color value to obtain a 32-bit RGBA value. The transparency value can either be used per vertex or per pixel by embedding it into texture maps. In both cases, the rule to follow is that the lower the value, the less opacity: Zero alpha would be completely invisible. Alphas closer to 1 (in floats) or 255 (in bytes) designate opaque items that will not let the light pass through them. Using alpha values embedded into texture maps should be kept to a minimum because they will make your textures grow by one fourth. If you need to do a map with constant alpha (such as a glass window, for example), you can save precious memory by using a regular RGB map and specifying alpha per vertex instead. If you think about it, you will find similar strategies to ensure that you only use alpha in a texture map whenever it's absolutely necessary. Texture MappingTexture mapping is used to increase the visual appeal of a scene by simulating the appearance of different materials, such as stone, metal, and so on, using pictures that are then mapped to the geometry. Thus, two separate issues must be dealt with. First, we must specify which texture map we will use for each primitive. Second, we need to know how the texture will wrap around it. Textures are specified by using numerical identifiers. So each of your texture maps is assigned at load time a unique identifier that you must use in order to make it current. These texture maps are assigned per face, so every triangle has a single texture map that covers it fully. An interesting side effect is that a single vertex can indeed have more than one texture. Imagine a vertex that is shared between two faces, each having different materials. The vertex will have a different texture identifier (and probably texturing coordinates) depending on the face you are looking at. Sometimes we will be able to layer several textures in the same primitive to simulate a combination of them. For example, we could have a base brick texture and a second map layered on top to create dirt. This technique (called multitexturing or multipass rendering) will be explored in Chapter 17, "Shading." It is one of the most powerful tools used to create great looking results. Now you know how textures are specified. However, the same texture can be applied in a variety of ways to the geometry, as shown in Figure 12.2. Let's stop for a second to understand how textures are mapped onto triangles. Essentially, we need to specify where in the texture map each triangle vertex will be located, so by stretching the texture according to these texturing coordinates, it is applied to the triangle. Each vertex is assigned a pair of coordinates that index the texture map's surface fully. These coordinates, which are commonly referred to as (U,V), map that vertex to a virtual texture space. By defining three (U,V) pairs (one per vertex), you can define the mapping of a triangle. Texture mapping coordinates are usually stored as floats in the range (0,1). This makes them ideal candidates for quantization and compression. Figure 12.2. Texture mapping explained.
In most cases, you will want to specify texture coordinates manually, taking them from a 3D modeling package. But some special effects will require these coordinates to be evaluated on the fly. One such example is environment mapping, which is a technique that allows you to create the illusion of reflection by applying the texture not directly to the surface but as a "reflection map." In these situations, coordinates might be manually computed by your game engine or, in most cases, by the API. We will see more of these advanced uses when we talk about shading techniques in Chapter 17. |
|
|
Ajax Editor
JavaScript Editor