Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
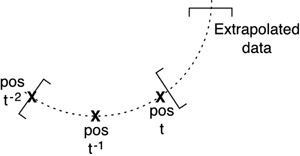
Massively Multiplayer GamesA massively multiplayer game (MMG) is a dream come true for devoted network programmers. The techniques, problems, and solutions found in their design and programming are as complex as network programming can get: lots of connections, lots of data transfer, and very restrictive time constraints. Add the ever-present lag to the equation and, well, you get the picture. To begin with, I'll describe MMGs as those games that serve a large community, using a single machine (or more) as dedicated game servers. The players run clients that update the servers with player state information, whereas the servers basically broadcast information to the playing community. MMGs are hard to code, not because they are an inherently complex problem, but because of their sheer size: Coding an eight-player game with a dedicated game server is not complex "per se." The problems arise when you try to cover thousands of players. So, all we need to do is work on techniques that allow us to "tame the size" of the problem. Let's explore a few of these methods. Data ExtrapolationUnfortunately, networks are sometimes slower than we would like them to be. We code our client-server systems assuming that the network is an infinitely fast and reliable highway, but this is seldom the case. Lags occur, and many times gameplay gets interrupted as we wait for the next position update from the other end of the wire. Under these circumstances, we must take every possible step to try to minimize the lag's impact on the gameplay, so the player can enjoy our game despite the network's problems. In a slow-paced game, speed will seldom be the problem. However, if you are playing a fast-action game, the last thing you expect is your opponent to freeze due to a network malfunction. Clearly, we need to put some math to work to ensure that we "smooth out" these network irregularities. The technique that we will use tries to determine the value of any player state characteristic at the present time, even when we haven't had a recent update. It works for any continuous value, so I will demonstrate its use with the most common parameter in any networked game: a player's position. For simplicity, I will assume we are in a 2D world with a player's position expressed using an x,z pair of floating-point values. Under these circumstances, all we have to do is store the last N position updates (I will demonstrate with N=3) as well as a time stamp (provided by timeGetTime()) for each one of them. As you already know, three values can be interpolated with a quadratic polynomial. If our positions are labeled P0, P1, and P2 (P2 being the most recent) and time stamps are respectively T0, T1, and T2, we can create a function: P(T) which gives us a position given a time stamp. To create the polynomial, we must only remember: P(T) = aT^2 + bT + c By substituting P0, P1, and P2 and T0, T1, and T2 in the preceding equation we get: P0x = ax T0^2 + bxT0 + cx P1x = ax T1^2 + bxT1 + cx P2x = ax T2^2 + bxT2 + cx Remember that P0.x, P1.x, P2.x, T0, T1, and T2 are well known, so the only unknown values are ax, bx, and cx. This system can easily be solved by triangulation. Once solved for x and z, we have two polynomials: Px(T) = axT^2 + bxT + c Pz(T) = azT^2 + bzT + c These polynomials compute, given a certain value for T, a pair x,z that corresponds to that time stamp. If T represents one of the initial values (T0, T1, T2), obviously the polynomial will return P0, P1, and P2, respectively (because we used them to compute the polynomial). But because we have chosen a parabolic curve (a polynomial of grade 2), values in between P0, P1, and P2 will be smoothly interpolated, so we will get an approximation of the value of a smooth trajectory going from P0 to P1 and P2. A more interesting property of polynomials tells us that they are continuous functions, meaning that values located close in parameter space (T, in this case) have similar return values (x,z pairs). Thus, if we extrapolate (which means we choose a value close but beyond P2), the value returned by the polynomial will still be valid (as shown in Figure 10.4) as an approximation of the trajectory in the vicinity of P2. In other words, a car performing a curve at time stamp T will very likely follow a smooth trajectory for a while, and thus we can assume the polynomial will be an accurate approximation. Figure 10.4. Extrapolating data to cover network lags.
As a result, we can trust this polynomial to accurately represent the future behavior of the position (assuming we don't get too far from T2 in time). So, every time a new position update arrives, we must discard the oldest update and rebuild the interpolation polynomials. Thus, we will use the interpolator to evaluate the position of the networked player until we receive a new update, and so on. If lag grows, we might perceive a "jump" in position when a new sampling point arrives (because we are moving from a very distant predicted position to a very close one). However, in real-world, moderate-lag scenarios, the preceding technique should help to significantly smooth out a player's trajectories. Hierarchical MessagingImagine a game where lots of network packets are continually being sent between players. Not all players have the same level of connection. Some players are playing on high-speed DSL or cable, whereas others are still using an analog modem. As traffic intensity increases, the modem user will begin feeling an information overload, and his playing experience will degrade. Hierarchical messaging is a technique designed to ensure that everyone gets the best information on a heterogeneous configuration. At the core of the method lies the notion that messages have different importance levels. For example, an enemy position update is more relevant than the configuration of his arms with regard to the animation system. Messages should be classified and assigned relevance levels. Then, as a new player enters the game, a network test should provide us with information on the user's expected bandwidth—how much data he can exchange per second. Then, we will decide which messages are sent to him depending on that bandwidth to ensure he gets the most important messages, but maybe loses some secondary information. Take, for example, a first-person shooter. Messages could be (in descending order of relevance):
Each "level" of transmission must be quantified in bytes per second, and then the right set of messages will be determined. Thus, in a first-person-shooter, maybe one player is just seeing positions and ignoring the rest of the information. But because he has the most relevant information, the game is still playable on a low-end machine. Spatial SubdivisionSpatial subdivision is designed specifically for massively multiplayer games. It uses spatial indexing to ensure that only relevant packets are transmitted and, by doing so, it can decrease the overall traffic by orders of magnitude. Imagine a squad-based game, where a player can join teams of up to four players in a quest—something like Diablo, for example. Obviously, we will need to send the position updates quite frequently, because the game is pretty high-paced. This is not much of a problem, because we are only dealing with four players. However, try to imagine what goes on inside a game such as Everquest—thousands of players roaming a huge game world, many of them located at days of distance (in gameplay terms) from other gamers. Under these circumstances, does it really make sense to update everyone about our current state? We might be consuming the bandwidth of a gamer at the other end of the game world with useless information. Now, imagine that players are stored in a spatial index data structure, usually held on the game servers managed by the publisher. Every time we want to broadcast new data regarding a player, we start by querying the spatial index about which players are located within a certain distance from the first one. Then, we only send the data to those players, saving lots of bandwidth. Let's stop and review an example. Think of an Everquest type of game with 100,000 players in a game world that is 100x100 kilometers across. The first alternative is to use standard broadcasts, where each packet is sent to everyone. Using very simple math, you will see that this requires sending 100,0002 packets of information if we want to update all players. Now, imagine that we divide the game world into a grid 100x100 meters. Each grid section contains the players specific to that grid. Assuming that their distribution is homogeneous, we would have 10 players per grid cell. Now, let's assume we only send the update to those players located in the current cell or in any of the nine neighboring cells. That means an update must be sent to 100 players (10 cells, 10 players per cell). Thus, the grand total of packets required to update everyone is just 10,000,000, which is 1,000 times less than if we did not use spatial subdivision. The only hidden cost is the data structure, but we can definitely afford that for a game server, which usually comes with lots of RAM. Send State Changes OnlyIf you are willing to accept some restrictions, you can greatly reduce your game's bandwidth by sending only state change information, not the actual in-game data stream. To understand how this method works and which restrictions we need to apply, think of a game like Diablo or Dungeon Siege, where two peers connected in a network are playing in cooperative multiplayer fashion. They explore the game world and solve quests. There are lots of monsters (each with its own logic routines) onscreen and lots of items to choose. In a game like this, you can choose between two networked approaches. Using one approach, you can run the game logic engine on only one of the two machines and propagate results to the other machine, which would receive all game logic information through the network and use it to drive the presentation layer. The second PC would thus only have the graphics engine and not much else, becoming a "game terminal." But the problem is ensuring that the network will be able to pump the data at the right speed, so the other player sees exactly the same game world, and the experience is seamless. This can be achieved on a local area network (LAN), but the Internet is a whole different business. Thus, we need an alternative. Basically, we keep two world simulators working in sync on both PCs. Both simulators must be 100 percent deterministic for this to work, meaning they must not depend on any outside events or random numbers. Only by ensuring this can we stop sending all game world update messages (monster positions, and so on) and focus on transmitting just player positions. This is a very popular approach, which requires checking for world syncing every now and then to make sure both game worlds don't diverge and end up being two completely different representations of the same level. If you are following such an approach, we can move one step further, changing the explicit information in our messages by using state change messages. Currently, you are sending a player position update for every logic tick, which is a waste of bandwidth. If the player is on a deterministic system (obviously, with the chaos inherent to gamer interaction), we can send only state changes and save much of this bandwidth. Instead of saying "the player is here" all the time, you only need to send "the player pressed the advance key" when a state change condition takes place. Do not forget that our player is, at the core, a finite-state machine. The player will continue performing the same action (such as walking or fighting) for many clock cycles. Sending only the state change lets you forget about all this continuous messaging, making your bandwidth requirements drop sharply. Just remember the restrictions imposed by this method: Both game worlds must be kept in sync. This will force some changes in your code, like the random number processing, for example. You can still have random numbers as long as both PCs have the same ones. Generating the same sequence in both PCs might seem like a crazy idea, but it's one of the essential tasks to ensure proper synchronization. To keep both random number generators in sync, all you have to do is have a random number table precomputed in memory (the same one for both machines, obviously) and use it instead of actually computing numbers. This change will have the desirable side effect of a significant performance gain, because random number generators are traditionally very slow, and tabulating them is a classic optimization trick as well. Working with Server ClustersNo serious MMG can be managed with a single server. As player count increases, we reach a point when we need to move to a cluster, so more users can be accommodated. This opens the door to a whole new area of programming, which deals with how to lay out the players on the servers, how to communicate with them efficiently, and so on. This is a relatively new science, but some interesting methods have already arisen. I will now comment on those, explaining the methods behind some popular solutions. To begin with, multiple servers are used to reduce the number of players that each server must handle. This might seem obvious, but most problems come from not understanding this key fact. We need each server to handle less players. So, we need:
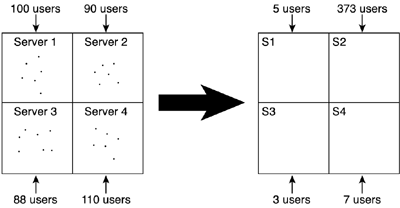
The second item in the list is the key fact. Imagine that we have 100 users, and we split them randomly into two groups of 50. Because we split them randomly, chances are that checking the collision of a player will require us to look at other players on his server, and on the other server as well, totally killing performance. We will still need to check with all the players in the game world. The solution, obviously, is to map our spatial subdivision engine to the server level. Each server will handle players located in a continuous part of the game world, thus ensuring that most tests can be solved locally. For example, we can divide the game world in half. Then, when we need to send a player update to the rest of the players, we test which other players are close to the original player. This is performed by the game server, hopefully on a local basis. All players needing the update will lie on the same machine as the original player. Once we have the list of those players that actually need to know that the original player has moved, we send the message to them only. Notice how we have improved performance in two ways. At the server level, only half of the gamers were tested. The rest of them lie on another server and did not even notice the player in the example moved. We optimized network bandwidth as well, sending the update only to those players within a certain range of the player. Now, let's generalize this to N servers in a large game world. We can divide the scenario in a gridlike fashion and assign grid quadrants to individual servers, so all players within that region are handled internally, and CPU and bandwidth are kept to a minimum. If the developer wants to add new regions to the game world, all we need to do is add extra servers to the cluster. Obviously, this approach will mostly have server-user traffic, but server-server communications will be important as well. How do we notify a server that a player has crossed the grid boundaries and must thus be relocated to the neighboring grid cell? To help visualize this, think in terms of vertical (server-user) and horizontal (server-server) messages. Vertical messages will be most frequent, whereas horizontal messages will carry control information and be less frequent. Dynamic Servers and the Braveheart SyndromeSometimes the clustered approach explained in the preceding section will fail to do its work. Basically, we have divided the game world spatially, assuming that means a homogeneous player division as well. Each cell region has approximately the same number of players. But what happens if a large number of gamers are, at a point in time, located in the same grid cell? Imagine a "hotspot" region to which many players converge for some game-related reason. Obviously, that server will sustain more workload than the rest. Imagine the "launchpad" area, where most gamers in a MMG appear when they first enter a game. It's an overpopulated area, which will make our servers stall. The first option would be to study these cases carefully and further divide the game world, much like in a quadtree, around these regions. But this implies that these hotspot regions are fixed, which doesn't really have to be the case. Imagine that one day there's an extra quest proposed by the game developers, and that quest increases traffic in a certain portion of the game world. How can we ensure that the gaming experience will not degrade that day? And how can we get things back to normal after the activity is over, and the traffic level is reduced? This is often referred to as the Braveheart syndrome: how to prevent a situation in which lots of gamers move to a small portion of the map and then leave it, much like in a battle like those portrayed in the Braveheart movie. This phenomenon is depicted in Figure 10.5. Figure 10.5. The Braveheart syndrome. Left: servers with homogeneous load. Right: players concentrate on a specific spot, bringing the system down.
Obviously, the solution is to allow dynamic server reallocation, so servers can be assigned to specific regions in real time with no user-perceived performance loss. When lots of players converge to a specific region, the server array must reconfigure itself automatically, subdividing the affected regions further so the overall number of players per server stays under control. This is a very involved solution, implemented (among others) by games such as Asheron's Call. It is also offered by many MMG creation packages, like the Game Grid by Butterfly.net. Two ways of dealing with the Braveheart problem come to mind. One approach would be to resize server zones to try to guarantee that all servers are equally loaded at all times. The idea is that if a zone gets overcrowded, this implies that other zones are emptying, and thus we can expand those zones so they assume part of the load from the crowded zone. Another approach would be to have hot-swappable servers that are basically ready and waiting for spikes. If a spike occurs, the whole game world stays the same. Only the affected server will call for help, dividing itself in two and passing part of the population to the hot-swappable server. This passing can cause some annoyances as the players are moved from one server to the other, but assuming the spike is progressive (players enter the zone one by one), we can gradually move them to the new server so performance loss is not detected. This second idea has an added benefit: If we implement hot-swappable servers, we can grow the game world dynamically without big changes in the design. We just add more servers and assign them to specific game zones, and we are all set. |
|
|
Ajax Editor
JavaScript Editor