Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Building a Scripting LanguageThe first technique we will explore is building a scripting language from scratch. This used to be common some years ago, when each team had to devote many hours to get a flexible scripting language to work. But recent advances in programming languages have made this technique less and less popular, as newer and better methods have appeared through the years. Today, you can have a top-class scripting engine up and running in just a few hours, with little or no trouble at all. However, for completeness, let me give you some idea of how creating your own programming language might work. I will deliberately only provide some hints, because programming language creation is a very in-depth subject to which you can devote many years (and several books as thick as this one). Check out Appendix E, "Further Reading," at the end of the book for some suggested reading on compilers, parsers, and other tools. Generally speaking, creating a programming language involves a three-step process. The first step entails defining the programming language syntax. This can be done on paper, because it is basically a matter of deciding which features you need and which syntax those features will be exposed through. The second step involves the creation of a program loader, which takes a file written in the said programming language and loads it into memory for execution. In this step, we must check for syntactic validity and take the appropriate steps to ensure efficient execution. The third and final step is the execution of the program itself. Depending on the coding strategy, this can range from just executing a binary module written in machine code to interpreting a high-level language such as BASIC, to something in between like Java. Whichever route you choose, the complexity of the task will largely depend on the syntax of the language of choice. As an example, we will now focus on two popular choices: a simple language that we will use to code a symbolic rule system and a full-blown structured language similar to BASIC or C. Parsing Simple LanguagesIn this section, I will describe the process of creating the parser and execution module for a simple language. I have chosen a language that is to be used to specify rule systems via scripting. The language is very similar to that used in the Age of Empires series. It is composed of a list of rules, and each rule is made up of a condition and an action, so the run-time engine selects the first one (in order) whose condition is active and executes the associated action. Following the preceding scheme, we will begin by deciding the syntax of our programming language: which constructs will be supported, the keywords, and so on. There are dozens of different approaches to this problem. But for this example, we will use the following syntax:
defrule
condition1
condition2
...
=>
action1
action2
...
Each rule can have multiple conditions (which are ANDed) and multiple actions (which are run sequentially). As an example, let's define a very simple scripting language that we will use as a case study. We will build the parser manually because the syntax is very simple. Each condition, for example, can be defined by the simple grammar: condition -> [float_function] [operator] float | [boolean_function] float_function -> DISTANCE | ANGLE | LIFE operator -> GREATER | SMALLER | EQUAL boolean_function -> LEFT | RIGHT So we can query the Euclidean distance, angular distance, and life level of the enemy. We can also test whether he is to our left or to the right. As you may already have guessed, this rule system is designed for controlling an action AI such as a ship. The actions we can perform can be defined as: action -> [float_action] float | [unary_action] float_action -> ROTATE | ADVANCE unary_action -> SHOOT Thus, here is a complete rule system built using these rules to demonstrate the expressive potential of the language:
defrule
distance smaller 5
left
=>
rotate 0.01
advance 0.1
defrule
distance smaller 5
right
=>
rotate -0.01
advance 0.1
defrule
angle < 0.25
=>
shoot
defrule
left
=>
rotate -0.01
advance 0.1
defrule
right
=>
rotate 0.01
advance 0.1
Because rules are executed in order, the previous example enacts a ship that tries to shoot down the player while avoiding collisions. The first two rules detect whether the player is too close and evades the player (rotating in the opposite direction, in radians). The next rule detects whether we can actually shoot down the player because he's at a small angular distance, whereas the last two rules implement a chasing behavior. These kinds of languages are really easy to load because their syntax is very regular. For each rule, you just have to parse the conditions, and depending on its value, parse the right parameter list. Then we repeat the process for each action. Thus, we will start by defining the data structure we will use to hold the rules. For our case, this can be defined as
typedef struct
{
int opcode;
int operation;
float param;
} fact;
typedef struct
{
list<fact> condition;
list<fact> action;
} rule;
Thus, the whole virtual machine would be
class vmachine
{
int pc;
int numrules;
rule *program;
public:
void load(char *); // Loads from the provided file name
void run();
};
The first phase (language definition) is complete. Now it is time to implement the loader and parser, so we can initialize the data structures while checking for the validity of the script. Because the language is very regular in its structure, the loader is not a big issue. Here is a portion of its code, which begins by computing the number of rules by counting the number of defrule apparitions in the source file:
void load(char *filename)
{
(...)
for (i=0;i<numrules;i++)
{
while (convert_to_opcode(readtoken(file))!=THEN)
{
fact f;
// read a condition
char *stropcode=readtoken(file);
f.opcode=convert_to_opcode(stropcode);
switch (f.opcode)
{
case ANGLE:
char *operation=readtoken(file);
f.operation(convert_to_opcode(operation);
// GREATER, etc
f.param=atoi(readtoken(file));
rules[i].condition.push_back(f);
break;
(...)
}
// rule conditions ok... move on to actions
while (!file.eof() && (convert_to_opcode(readtoken(file))!=DEFRULE))
{
fact f;
// read an action
char *stropcode=readtoken(file);
f.opcode=convert_to_opcode(stropcode);
switch (f.opcode)
{
case ROTATE:
f.param=atoi(readtoken(file));
rules[i].action.push_back(f);
break;
(...)
}
}
We only need to provide a routine to parse tokens (strings or numeric values separated by spaces or newline). Notice how we have assumed there is a define for each opcode, which we use to access its symbolic value. In our case, the define list would be #define LEFT 0 #define RIGHT 1 #define ADVANCE 2 #define ROTATE 3 #define SHOOT 4 #define ANGLE 5 #define DISTANCE 6 #define DEFRULE 7 #define THEN 8 #define GREATER 9 #define SMALLER 10 #define EQUAL 11 #define WRONG_OPCODE –1 Notice how we reserve an additional opcode to process parsing errors. By following this convention, the final code to the convert_to_opcode routine would just be
int convert_to_opcode(char *opcode)
{
if (!strcmp(opcode),"left") return LEFT;
(...)
if (!strcmp(opcode),"=>") return THEN;
return WRONG_OPCODE;
}
In this example, our language is case sensitive like C. By changing the strcmp call, you can implement case-insensitive languages as well. Once we have defined the language syntax and have coded a loader, it is time to move on to the execution module of our virtual machine. Again, because this is a relatively simple language, it is very helpful. We just have to scan the list of sentences and take the appropriate actions for each one of them. Here is the source code for part of the vmachine::run operation:
void vmachine::run()
{
rule *ru;
bool end=false;
pc=0;
while ((!end) && (!valid(rule[pc]))
{
pc++;
}
if (valid(rule[pc].condition))
{
run_action(rule[pc]);
}
}
Notice that we really scan the rules searching for the first one that has a valid condition. If we fail to find such a rule, we simply return. Otherwise, we call the action execution subroutine, which will take care of executing each and every action assigned to that rule. The real meat of the algorithm lies in the routine that evaluates whether a rule is valid and the routine that executes the actions. Here is part of the source code of the first routine:
bool valid (rule r)
{
list<fact>::iterator pos=r.condition.begin();
while (pos!=r.condition.end())
{
switch (pos->opcode)
{
case ANGLE:
// compute angle... this is internal game code
angle=...
if ((pos->operation==GREATER) && (angle<pos->param))
return false;
if ((pos->operation==SMALLER) && (angle>pos->param))
return false;
if ((pos->operation==EQUAL) && (angle!=pos->param))
return false;
break;
case DISTANCE:
(...)
break;
}
pos.next();
}
return true;
}
Basically, we test all the facts in the condition. As we AND them, all of them must be valid for the rule to be valid. Thus, the moment one of them is not valid, we reject the rule totally and return false. If we happen to reach the end of the fact list and all of the facts are true, the whole rule is true, and we must validate it. Now, here is the action execution:
void run_action(rule r)
{
list<fact>::iterator pos=r.action.begin();
while (pos!=r.action.end())
{
switch (pos->opcode)
{
case ROTATE:
yaw+=pos->param;
break;
case ADVANCE:
playerpos.x+=pos->param*cos(yaw);
playerpos.z+=pos->param*sin(yaw);
break;
(...)
}
}
}
Notice how in this case we do not test but instead execute actions sequentially, as if the routine were a regular computer program. We have seen how to parse and execute a simple programming language in the form of a symbolic rule system. From here, we can add many constructs to enhance the expressive potential. Age of Empires had well over 100 facts, so both action and conditions could be based in sophisticated routines. In an extreme case, you could end up with a very involved programming language. It all depends on your knowledge of parsing techniques and the time spent polishing the language. Efficiency, on the other hand, is quite good, especially if each sentence has strong semantics (its execution is complex and takes many clock cycles). In a language such as the one outlined earlier (and pictured in Figure 9.1), each sentence has an implicit performance hit for the loop and switch constructs. But the rule execution is just binary code. Clearly, the impact of the parsing and switch constructs will be noticeable if each rule has very light-weight binary code that takes almost no time to execute. Now, in a language where each instruction takes a lot of binary code to execute, the overhead of the loop and switch will be negligible, and performance on your scripting language will be almost identical to that of native code. Figure 9.1. Weak (top) versus strong (bottom) semantics.
Parsing Structured LanguagesIt is possible to code parsers for more complex languages following the ideas outlined earlier. But coding a language such as C from scratch would definitely be a challenging task. There are hundreds of constructs, function calls, and symbols to account for. That's why specific tools, such as lexical scanners, were designed many years ago to help in the creation of programming languages. Lexical scanners are used to detect whether a token (character string in a programming language) is valid or not. The most popular example of these analyzers is called Lex. Basically, you use Lex to generate a beefed-up version of our convert_to_token routine. Lex receives a formal definition of the lexicon for the language and is able to generate C code that decodes and accepts valid tokens only. To declare this lexicon, you must use Lex's convention. For example, here is a portion of the lexicon for the C programming language:
"break" { count(); return(BREAK); }
"case" { count(); return(CASE); }
"char" { count(); return(CHAR); }
"const" { count(); return(CONST); }
"continue" { count(); return(CONTINUE); }
"default" { count(); return(DEFAULT); }
"do" { count(); return(DO); }
"double" { count(); return(DOUBLE); }
"else" { count(); return(ELSE); }
"enum" { count(); return(ENUM); }
"extern" { count(); return(EXTERN); }
(...)
"*" { count(); return('*'); }
"/" { count(); return('/'); }
"%" { count(); return('%'); }
"<" { count(); return('<'); }
">" { count(); return('>'); }
"^" { count(); return('^'); }
"|" { count(); return('|'); }
"?" { count(); return('?'); }
Once Lex has detected the lexical constructs, it is time to move higher in the abstraction scale and detect full language constructs such as an if-then-else loop. To achieve this, the syntax of the language must be described in mathematical terms. An if sequence, for example, can be described in a variety of alternative ways, such as:
Formally speaking, this sequence can be described using a mathematical construct called Context-Free Grammars (CFGs). CFGs allow us to declare languages by using a substitution rule. For example, here is the rule for the IF construct in the C language:
if_statement
: IF '(' expression ')' statement
| IF '(' expression ')' statement ELSE statement
;
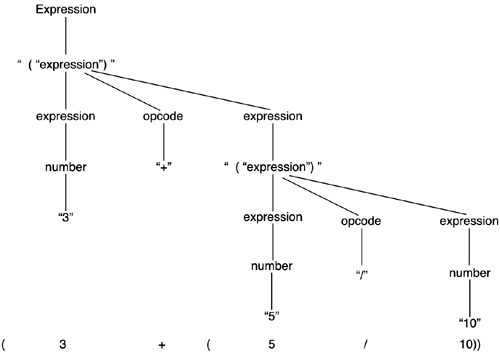
Each lowercase token is another rule we can apply. For a simpler example, here is a CFG for evaluating numeric expressions: Expression
opcode
Thus, we can apply the two rules recursively to obtain the syntactic tree shown in Figure 9.2. Figure 9.2. Syntactic tree for a mathematical expression.
Once we have specified our programming language by means of its grammar, we need a program that actually parses the input file, and once it has been converted to tokens, checks for syntactic correctness. The most popular of such applications is called Yet Another Compiler Compiler (Yacc). Yacc takes a grammar file as input and generates the C code required to parse the grammar. Then, it's up to the application developer to decide what to do with this syntax checker. We could decide to convert the input file to a different format, such as a bytecode used in the Java programming language. Alternatively, we could decide to execute the program as it's being checked for validity. We would then use an interpreter, such as BASIC. In addition, we could choose a middle-of-the-road solution and convert the input file to an intermediate representation, such as an assembly-like syntax, which is faster to execute in an interpreter-like fashion. This is usually referred to as a just-in-time (JIT) compiler. For computer game scripting, Yacc is commonly used as an interpreter or as a JIT compiler. It does not make much sense to actually output any bytecode, because we really want to run the script. |
|
|
Ajax Editor
JavaScript Editor