Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Specific TechnologiesIn the rest of this chapter, we will explore the four main AI constructs most commonly used in game programming: state machines, rule systems, state-space searches, and genetic algorithms. Finite State MachinesThe first AI technology we are going to explore is that of finite state machines (FSMs). Depending on which books you read, the same technology is also called deterministic finite automata (DFA) or simply state machines or automata. So let's get formal for a second so as to provide a good definition of FSMs. An FSM is a formalism consisting of two sets:
Essentially, an FSM depicts the entity's brain as a group of possible actions (the states) and ways to change from one action to the other. If you say something like the following, you will have created a state machine:
Sentences 1 and 3 represent states, and sentences 2 and 4 represent transitions. However, written descriptions are not very well suited for FSMs. When the number of states and transitions grows, we need a better way to represent information. So, state machine graphs are drawn, using circles for the states and lines for the transitions between states. The initial state is represented with an incoming transition from nowhere, so it can be easily identified. FSMs are the most popular technique used to create game AIs. The state machine can become the brain of your virtual entity, describing different actions using states and linking those with transitions in a meaningful way. Lots of action games have been using FSMs since the dawn of time (which by the way happened in the late 1970s, more or less). They are intuitive to understand, easy to code, perform well, and can represent a broad range of behaviors. An ExampleBecause FSMs are such an important tool, let's look at a complete example, starting with the AI idea, creating the FSM needed to model it, and putting it down in code. This way we will see how each part fits together in an intuitive workflow. AI SpecificationThe first task you need to undertake is to specify the behavior of your AI. It is very important to be thorough in this phase because fixing an AI halfway through the process is sometimes problematic. Thus, it is a good idea to write down the primitive behaviors you need your AI to perform. We will then represent these graphically to lay them down into actual running code. As an interesting example, I have chosen the AI of a patrolling guard that carries a contact weapon, like a medieval soldier. Here is the specs list for our AI, in no specific order:
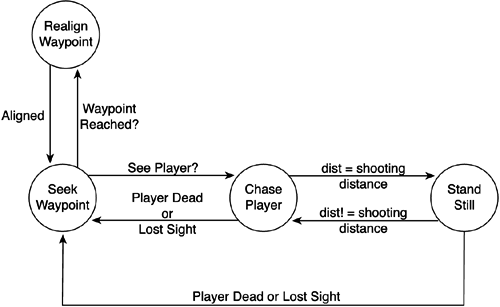
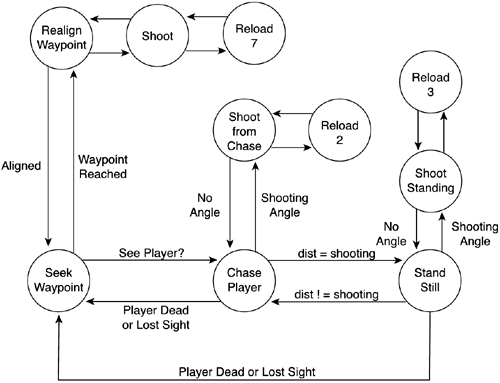
Graphical LayoutOne of the greatest mistakes in FSM creation is to actually begin by writing code. As the state machine grows, it will become impossible to keep in mind a complete picture of all states and transitions, and most likely, we will end up with clumsy AI that does not actually do what it was intended to. Whatever you are designing, the time required to draw a simple diagram will always pay off in the long run. You can save the diagram along with the rest of the project documentation for later use, thus making it easier to recycle AIs. It will also help you visualize the behavior in an intuitive way. FSMs are really easy to code when using a diagram as a starting point, but hard to get right without one. Thus, Figure 6.2 presents the diagram I have chosen for the AI I have just described. The first two states are used to implement the patrolling behavior. The first state follows the current waypoint, and the second is a very simple state that keeps rotating once we have reached a waypoint until we are aligned with the next one. This way our guard will stand still while turning corners, which is a very natural thing to do. Humans do not actually walk in curves like a car would do. Figure 6.2. Graphical representation of the soldier state machine.
Notice how we have a second subsystem that is triggered from the SEEK_WAYPOINT state and allows us to chase the player once he enters our view cone. The chase and attack subsystem is composed of two states: one chases the player around, and the second is used when we contact him to perform our combat routine. Both states can be abandoned if we lose sight of the player, thus returning to our regular patrol. Laying Down Some CodeWhen you reach the coding point, your creativity will have done all the work for you. Coding FSMs is almost an automatic process. If the specs and graph are done right, writing the FSM is very simple. Essentially, you need to enumerate your states, reserving 0 for the initial state and positive integers for the others. So, if your FSM has N states, your last state will take the number N-1 as its identifier. In C or C++, I recommend using #define statements to create meaningful state names, which make code much more readable. You can do something like this: #define SEEK_WAYPOINT 0 #define ROTATE_WAYPOINT 1 (...) Then, an integer variable will be used to represent the state the AI is at, and thus drive a switch construct:
int state;
switch (state)
{
case 0:
{
// code for this specific state
break;
}
(...)
case N-1:
{
// code for this specific state
break;
}
}
This way each of the cases in the switch controls a specific state and evaluates the possibility of changing states due to a specific transition in the automata being selected. Now we need to work out the code inside each of those cases. Here we can use another trick to make life easier. Each state's activities should be divided into three thematic areas:
We can then lay out the code into each of the cases easily regardless of the specifics of each state. Let's look at an example:
case [NAME OF STATE]:
[DEFAULT ACTIONS]
[CONDITION EVALUATION]
if (TRANSITION)
state=destination state;
(...)
break;
I recommend that all your cases share this same layout because it will help you code faster and find potential bugs efficiently. With these guidelines in mind, and provided you can code your basic tests (distances, angles, and so on), coding FSMs becomes pretty much a mechanical task. All the creativity was completed in the AI design and formalization phase. Now, let's look at the code of our chaser enemy. I have implemented him using a class called patrol:
#include "point.h"
#define SEEK_WAYPOINT 0
#define ROTATE_WAYPOINT 1
#define CHASE_ENEMY 2
#define FIGHT_ENEMY 3
class patrol
{
int state;
int nextwaypoint;
point *waypoints;
point position;
float yaw;
public:
void create(point, point *,int);
void recalc();
};
The create method would create a patrolling enemy at the position passed as first parameter, load the waypoint vector with the incoming data from parameters two and three, and reset the nextwaypoint controller to the first point in the list. Then, it would put the automata in the state of SEEK_WAYPOINT. The real meat comes in the recalc function, which can be browsed in the following listing. Some routines have been simplified for the sake of brevity and clarity:
void patrol::recalc()
{
switch (state)
{
case SEEK_WAYPOINT:
{
break;
}
case ROTATE_WAYPOINT:
{
break;
}
}
}
For completeness, here is the very useful compute_rotation() routine, which is used by the preceding code. The routine receives a position and yaw (from the patrol), and a position (the waypoint or enemy we are following), and returns the yaw increment we should be applying in order to chase the target. It detects which side it stands in, and so on:
float compute_rotation(point pos, float yaw, point target)
{
point forward=pos+point(cos(yaw),0,sin(yaw));
point up=pos+point(0,1,0);
plane pl(pos,forward,up);
bool left=(pl.evalpoint(target)>0);
if left return –0.1;
else return 0.1;
}
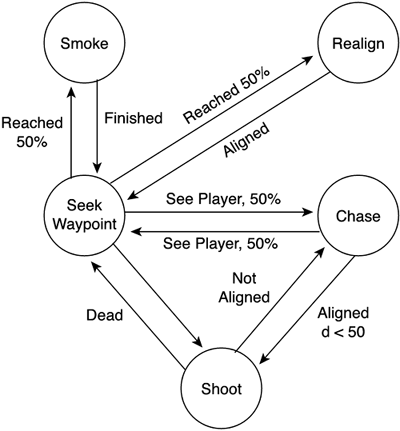
I have provided this as an example of where the CPU cycles are actually spent in an FSM—in these small tests that often require floating-point and trigonometric operations. Always double-check your tests for performance. It is essential that you guarantee that the state machine is as efficient as can be. The next chapter provides a great deal of information on computing these tests. Parallel AutomataSometimes, especially when modeling complex behaviors, a classic FSM will begin to grow quickly, becoming cluttered and unmanageable. Even worse, we will sometimes need to add some additional behavior and will discover how our FSM's size almost doubles in each step. FSMs are a great tool, but scaling them up is not always a trivial task. Thus, some extensions to this model exist that allow greater control over complex AI systems. Using parallel automata is one of the most popular approaches because it allows us to increase the complexity while limiting the size of the automata. The core idea of parallel automata is to divide our complex behavior into different subsystems or layers, pretending that the entity being modeled has several brains. By doing so, each sub-brain is assigned a simpler automata, and thus the overall structure is easier to design and understand. I will now provide a complete example of what a parallel automata can look like. As a starting point, I will use a variation of our patrolling enemy from the previous section, adding a gun to his behavior. I will also add simple collision detection. Thus, his behavior consists of patrolling an area and, as he senses you, chasing you around the level, trying to shoot you down. Clearly, he's a pretty complete case study. Now, let's try to model this character by assuming he has several brains; each one assigned to a type of action. In our case, we will need only two: one will manage locomotion, and the other will take care of the gun. Let's forget the gun for a second and focus on character movement. Essentially, this enemy can be modeled with a relatively straightforward FSM, which you can see in Figure 6.3. It is very similar to the preceding example except for the collision detection and additional logic required—not to seek contact, but to shoot from the right distance. Figure 6.3. Automata for locomotion.
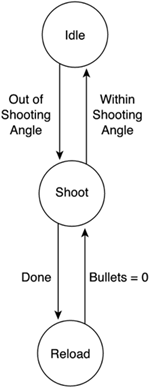
The resulting automata has four states. Now, let's add the gun handling control (see Figure 6.4). If you think about it, we only need to keep shooting if the player is directly in front of our virtual creature, which seems simple enough. An FSM that only performs this task would require just two states—an initial state that would detect the condition and a second state where the enemy is effectively shooting. Although we will add a third state to reload the gun, the automata is still quite simple. Figure 6.4. Automata controlling the gun.
But what would happen if, instead of using the parallel automata paradigm, we chose to merge the automatas into a large-size, unique automata? We would discover that whenever we merge the two automata, the size of the overall FSM triples. Why? Because from each state of the first automata we need to be able to shoot or not, depending on the player's position. Clearly, we need the combination of all the states of the first automata with the states of the second. The resulting automata (shown in Figure 6.5) is overly complex and significantly harder to understand. Figure 6.5. Combined automata. Notice how we need to split some states in two so we can return to the calling state when we are done.
So, let's try a different approach. Think of this enemy as if it were a warplane with two crew members: a pilot who controls the direction, speed, and so on, and a gunner who is in charge of shooting down targets. It's not one brain and one FSM, it's two brains acting in parallel. Using this approach, we would depict the behavior of the overall system by drawing both automata side by side and would code them in the following manner:
int state1;
int state2:
switch (state1)
{
case 0:
...
break;
(...)
case N-1:
...
break;
}
switch (state2)
{
case 0:
...
break;
(...)
case M-1:
...
break;
}
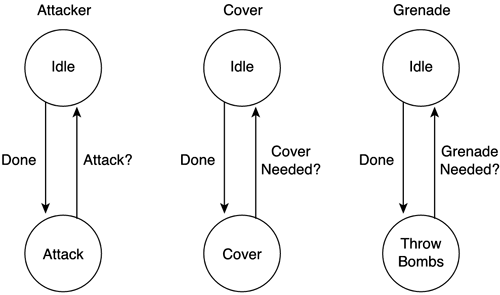
N and M are the number of states of each automata, respectively. Our design will be more elegant, our code will be shorter, and the performance penalty will be virtually zero. Parallel automata are great to use to model those systems where we have simultaneous but largely independent behaviors going on—locomotion and attack in this case. Independent is the key term here. Be careful with parallel automata where the state of one state machine affects the state of the other. For example, imagine that our soldier stops when shooting, so if the second automata's state equals "shooting," we need to change the state of the first one as well. These interconnections are tricky because they can yield deadlock situations and often break the elegance of a parallel automata's design. Keep automata independent as much as you can, and you will be safe. However, some great AIs and interesting behaviors are directly based in interconnected parallel automata, where state machines share information, and the overall behavior is greater than the sum of its parts. Let's take a look at that technique next. Synchronized FSMsAnother addition to our FSM bag of tricks is implementing inter-automata communications, so several of our AIs can work together and, to a certain extent, cooperate. By doing so we can have enemies that attack in squads. While one of them advances, the other provides coverage, and the third one calls for help. Such an approach became very popular with the game Half-Life, which was considered a quantum leap in action AI, basically because of the team-based AI. Notice, however, that synchronizing AIs is no silver bullet. The method we will use is not well suited for a full-blown strategic game with complete faction-based AIs involving dozens of entities. Rule systems (explained in the next section) are much better suited for that purpose. Synchronizing AIs via FSMs is just a way to increase the expressive potential of our AI, so we can have small teams working in parallel. At the core, synchronizing AIs involves a shared memory area where all automata can write to and read data from. I'll use a bulletin board metaphor. Whenever an AI wants to say something to the rest, it posts it in the shared memory area, so others can browse the information; and if it is relevant to them, they take it into consideration in their decision-making process. There are two common approaches to this task. One is to use a message passing architecture, which involves sending messages to those AIs we want to synchronize to. If an AI needs to keep in sync with several others, many messages will need to be sent. The alternative and preferred method is to use a bulletin board architecture, where we don't send dedicated messages, but instead post our sync messages on a shared space that is checked frequently by all AIs. This space is the bulletin board. By using it, we can avoid having to send many messages back and forth. Thus, we chose bulletin boards instead of a message passing architecture because message passing would slow performance down in systems involving many agents in parallel. With a bulletin board, all we have to do is post the information to the board. Then, it's up to the other AIs (and their internal state) to read that information or simply ignore it. Message passing would need queues, loops to ensure we send the message to everyone, and so on, which is really a big pain for such a simple system. Let's make a synchronized AI for a squad of three soldiers, designed to attack an enemy in a coordinated manner. I will override their navigation behavior and focus on the actual combat operation. As one of the three establishes contact with the player, he will designate himself as the attacker. The role of the attacker AI is to wait until a second AI, called the cover, begins providing cover fire. Then, the attacker will take advantage of the cover fire to advance toward the player and try to shoot him down. A third AI, dubbed the grenade, will remain in the back behind some protection, throwing grenades. If any soldier gets killed, the remaining soldiers will shift in the chain of command to cover the position. Thus, if the attacker is shot down, the cover will become the attacker, and the grenade will become the cover. This AI does not look very different from those found in many Half-Life situations. Figure 6.6 shows the three state machines, not taking communications and sync into consideration for a second. Figure 6.6. The three automata with no synchronization.
Now, we will implement the synchronization mechanism using a shared memory that will store the following data: bool fighting; // set by the first automata that contacts the enemy bool attacker_alive; // true if attacker is alive bool cover_alive; // true if cover is alive bool grenade_alive; // true if grenade is alive Our state machine code will need two operations: a shared memory read, which will always be part of the transition test, and a shared memory write, which will be performed from a state's own code. For example, the code used to detect the enemy would look something like this:
if (enemy sighted)
if (fighting=false)
fighting=true
attacker_alive=true;
The role played by shared memory writes and reads is obvious. Figure 6.7 presents the full automata for the AI system. Figure 6.7. Fully synchronized automata using a shared memory zone.
Notice how we have merged all three automata into one large state machine. This is a wise move because this way we can instantiate it three times (making sure the shared memory zone is common between them) and have the three soldiers actually be interchangeable. There is no longer one specific attacker, cover, or grenade, but three soldiers that can play different roles depending on which one spots the enemy first. Nondeterministic AutomataClassic FSMs are deterministic in a mathematical sense of the word. This means that given a state and the values of all the boundary conditions, we can predict which of the outgoing transitions will be executed (if any). In practical terms, this means that the behavior of our AI entity will be totally predictable, which is generally not a good thing. A corollary of this same principle is that given a state, one transition at most can be valid. It is unacceptable by the mathematical model that two transitions might be available at a given time. This predictability gives the developer tight control, but is not always desirable. Take, for example, an enemy AI. By playing the game repeatedly, the human opponent would discover the underlying strategy, and thus the gameplay would be destroyed. In these circumstances, a limited degree of randomness can be added to the mix to ensure that the AI will never become predictable, so it will remain challenging even after hours of play. A traditional FSM is not well suited for this. We can model these situations by relaxing our mathematical model to allow several transitions to be simultaneously valid. This kind of automata is usually called Nondeterministic Finite Automata (NDFA). Here, a state might have several outgoing transitions, which we can activate or not in a controlled random manner. Take, for example, our classic soldier. We can modify his automata by introducing limited randomness, as shown in Figure 6.8. For example, whenever he reaches a waypoint and feels like it, he can stop for a cigarette. Also, if he is patrolling and sees the player, he can choose between chasing him or shooting him down. This degree of limited randomness is very useful in games where many AIs are using the same state machine. If we do not add a certain jitter degree, the overall impression can become too robotic and repetitive. Figure 6.8. Nondeterministic automata for the soldier.
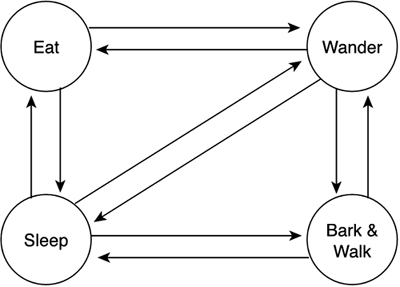
The soldier has a certain degree of "virtual freedom," so he can choose different action courses randomly. This will make his AI less predictable and more engaging. Nondeterminism is especially important for those AI entities that appear in groups, so we can reduce the homogeneous, boring look of the different automata performing the same task. Rule SystemsFinite state machines are a very convenient tool for designing AIs. They can model different behaviors elegantly. But some phenomena are not easy to describe in terms of states and transitions. For example, imagine the following specs for a virtual dog:
We have four statements that we might feel inclined to model using an FSM. But if we did so, we would get something like what is shown in Figure 6.9. Figure 6.9. Simplified automata for a dog, showcasing how we need all possible transitions.
Clearly, each statement implies one state of the machine, and each state can transition to any of the others. Something is not quite right here, but we can't tell what it is. The key idea is that FSMs are well suited for behaviors that are
The virtual dog just described is not local. If you analyze it, all states can yield any other state, so the model is not local at all. Also, there are no visible sequences. All the dog actually does is act according to some priorities or rules. Luckily, there is one way to model this kind of prioritized, global behavior. It is called a rule system (RS), and it allows us to model many behaviors that are tricky to model using FSMs. At the core of an RS, there is a set of rules that drive our AI's behavior. Each rule has the form:
The condition is also known as the left-hand side (LHS) of the rule, whereas the action is the right-hand side (RHS) of the rule. Thus, we specify the circumstances that activate the rule as well as which actions to carry out if the rule is active. In the previous dog example, a more formal specification of the system would be
Notice how we enumerated the rules and separated the condition from the actions in a more or less formal way. The execution of an RS is really straightforward. We test the LHS of each expression (the conditions) in order, and then execute the RHS (the action) of the first rule that is activated. This way, RSs imply a sense of priority. A rule closer to the top will have precedence over a rule closer to the bottom of the rule list. RSs, as opposed to FSMs, provide a global model of behavior. At each execution cycle, all rules are tested, so there are no implied sequences. This makes them better suited for some AIs. Specifically, RSs provide a better tool when we need to model behavior that is based on guidelines. We model directions as rules, placing the more important ones closer to the top of the list, so they are priority executed. Let's look at a more involved example, so I can provide more advice on RSs. Imagine that we need to create the AI for a soldier in a large squadron. The rule system could be
Again, just six rules are sufficient to model a relatively complex system. Now, notice how the clever placement of the rules has allowed some elegant design. If the soldier is in the middle of combat with an enemy but is given an order by the leader, he will ignore the order until he kills the enemy. Why? Because the combat rule is higher on the priority list than the "follow order" rule. Hence lies the beauty of RSs. Not only can we model behaviors, but we can also model behavior layering or how we process the concept of relevance. Notice the condition in rule 3. It should really say:
But we have skipped the second condition. If we have reached the third rule, it is because the second rule was computed as false, so we know for sure we can just evaluate the first member only, saving some execution cycles along the way. In addition, notice how the last rule does not have a condition but is more a "default action." It is relatively normal to have a last rule that is always true. This can be written in a variety of ways, such as:
Whichever option you choose, the goal is always the same—express the default action to be carried out if no rule can be applied. ImplementationOnce designed, RSs are very easy to actually code. There are different strategies that make coding rules almost as automatic as writing FSMs. I will now evaluate two different alternatives. One is very well suited for hard-coded RSs, which control actions. The other is a tactical RS, which would be useful in the context of a scripting language in a strategy game, for example. Decision TreesLet's start by coding an RS for action games. One of the easiest methods is to code your system using a decision tree. We will use the example from the previous section and lay out the code for the soldier's RS. The decision tree associated with this system would be
if (contact with an enemy) combat
else
{
if (closer than 10 meters)
{
if (stronger than him) chase him
else
escape him
}
else
{
if (command from our leader pending) execute it
else
{
if (friendly soldier is fighting and
I have a ranged weapon)
shoot at the enemy
else
stay still
}
}
}
Decision trees are a direct mapping of our rule set, in priority order, to an "if" tree. They are very easy to construct and, for simple systems such as this one, provide an excellent elegance versus cost ratio. Basically, we nest If-then-else sentences, using the rules as the conditions of each if. The first rule is the condition in the outer level if clause. Then, the if following the else contains the second rule, and so on. Actions are assigned to the corresponding if, so the action from the first if is whatever action we must carry out if the first rule proves to be valid. Symbolic Rule SystemsAnother implementation of the RS is by means of a scripting language, which symbolically represents the rules. The rules are written according to some specs, parsed from external files, and executed in real time. The best example of such behavior in action is the RSs present in most real-time strategy games, which control the tactical level of the gameplay. Here is an example taken from the Age of Empires rule language:
(defrule
(resource-found wood)
(building-type-count-total lumber-camp < 5)
(dropsite-min-distance wood > 5)
(can-build lumber-camp)
=>
(build lumber-camp)
)
This rule states that if we found wood, the number of lumber camps in our army is less than five, the newfound wood source is farther than five units, and if we have resources to build an additional lumber camp, then we should build one. Both tests and actions are highly symbolic and will require converting them to actual code. You will learn how to parse such an RS in Chapter 9. However, it's not parsing the rules that should worry us: A simple parser will do the job. The real issue with symbolic RSs is that instead of having to test five rules, we might need to check 50. Tactical reasoning needs lots of rules, and thus the rule evaluation function can become an issue. We will need to optimize the code carefully, and make sure the rule evaluation tests can actually be computed in our AI tick time. Another tricky problem is coping with variable-duration AI tests. RSs explore rules sequentially until one of them is proven true (or until no more rules are available). Clearly, if the first rule is true, our AI code will be executed in very little time. On the other hand, if no rule is valid, we would need a very significant processing time to reach the final rule. A variable AI processing time generates a variable frame rate, which is by no means a good thing. Clearly, we need a structured way to lay out RSs, which makes execution time more or less independent of the path taken. One of the best approaches is the Rete algorithm, proposed by C.L. Forgy in 1982.[1] The algorithm greatly improves the efficiency of forward-chaining RSs (the systems where we test conditions sequentially) by limiting the effort required to reevaluate the RS after a first iteration has been run. It exploits two facts:
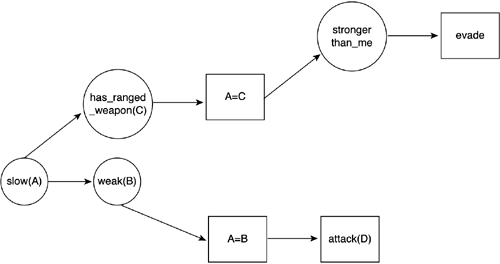
Rete works by keeping a directed acyclic graph that represents the facts in memory. New facts are added to the graph as they are activated by rules. We can also delete facts and modify existing ones (for example, if the number of soldiers in our camp increases from 20 to 21). Each node in the graph represents a pattern (a unique comparison in the LHS of a rule). Then, by tracing paths from the root to the leaves, complete LHSs of rules are extracted. Here is a very simple example of a Rete built from the rules: (defrule (slow(x)) (has_ranged_weapon(x)) (stronger_than_me(x)) => (evade(x)) ) (defrule (slow(x)) (weak(x)) => (attack(x)) ) The associated algorithm is shown in Figure 6.10. Figure 6.10. Rete algorithm, starting point. Circles are predicates, squares indicate restrictions we must satisfy, rectangles are the RHS of rules. At runtime, the tree is explored so we can cache partial results from one test to the next.
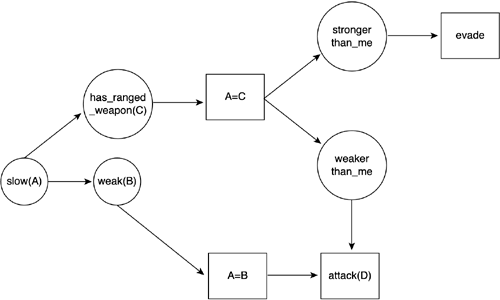
Notice how we have repeated facts that are in fact shared by the two rules. In Rete, we usually merge those, so we eliminate the fact redundancy. We can also eliminate operators that are repeated, so we cache parts of the LHS that are repeated in many rules. Now, imagine we add a new rule, such as: (defrule (slow(x)) (has_ranged_weapon(x)) (weaker_than_me(x)) => (attack(x)) ) The final Rete for the preceding example is shown in Figure 6.11. Figure 6.11. Rete after insertions.
The number of elements in the Rete is no longer linear to the number of rules. In fact, as the number of rules grows, the chances of patterns in the LHS being repeated increases. Thus, extra rules will come at little cost for the Rete. Coding the graph function is definitely not for the faint of heart, so I suggest you take a look at Appendix E, "Further Reading," for more details in implementing the algorithm. In the long run, the Rete algorithm guarantees that execution time will be more or less independent from the number of rules because we're not really testing rules anymore but checking for changes in our fact database. In fact, Rete is widely considered to be the fastest pattern-matching algorithm in the world and is used by many popular production RSs, such as CLIPS and Jess. User-Defined FactsThe RSs we have seen so far only test for conditions and perform actions. Often, a third construct is added to increase the expressive potential of the RS so it can model more problems accurately. User-defined facts are added, so one rule can set a flag, and another rule can test whether the flag has a certain value. This is very useful because it allows the AI programmer to somehow implement the concept of memory or state in the otherwise stateless world of rules. Imagine that we are working on a strategy game and are coding the RS that controls resource gathering, as in the earlier wood example. We have written a rule for the lumber camp construction that is not very different from the previous one. For increased realism, we want to show the player the process of building the lumber camp. Specifically, once the "build camp" rule is triggered, we want one AI entity to move to the building spot, and then perform a series of animations that show the building process. Obviously, this is a sequence of actions that must be performed in a specific order, and we already know that RSs are not very well suited for this task. We could achieve this result by writing the following rules, which would do the job:
(defrule
(constructor-available)
(need-to-build lumber-camp)
(I-am-in lumber-camp)
=>
(construct lumber-camp)
)
(defrule
(constructor-available)
(need-to-build lumber-camp)
=>
(move-to lumber-camp)
)
(defrule
(resource-found wood)
(building-type-count-total lumber-camp < 5)
(dropsite-min-distance wood > 5)
(can-build lumber-camp)
=>
(build lumber-camp)
)
Now, try to think of the amount of extra facts we would need to add to our system to cover all the possibilities. Age of Empires can build dozens of structures, and each one would require specific rules for it. Clearly, that's not the way to go, but some of its philosophy is definitely valid. If you think about it, you will realize that all we have to do is add a construct that allows us to set a value in a memory position, so subsequent rules can read it back as part of their condition evaluation code. Instead of hard coding all the new facts, we would provide an open interface so the user can define them as needed. This is what user-defined facts are all about—allowing the user to implement sequences and store intermediate values, which are read back when needed. The case of the lumber camp constructor can be easily solved with the following rules:
(defrule
(constructor-available)
(check-fact-value lumber-camp-construction-step equals 1)
=>
(build-structure lumber-camp)
)
(defrule
(constructor-available)
(check-fact-value lumber-camp-construction-step equals 0)
(distance-to lumber-camp less-than 5
=>
(set-fact lumber-camp-construction-step 1)
)
(defrule
(constructor-available)
(check-fact-value lumber-camp-construction-step equals 0)
=>
(move-to lumber-camp)
)
(defrule
(resource-found wood)
(building-type-count-total lumber-camp < 5)
(dropsite-min-distance wood > 5)
(can-build lumber-camp)
=>
(build lumber-camp)
(set-fact lumber-camp-construction-step 0)
)
We only need to add the set-fact and check-fact value constructs. Some systems (Age of Empires, for example) do not allow user-defined facts to be identified by character strings but by numbers. We have a certain number of facts whose identifiers are integers. But the added parsing complexity of implementing a symbol table that allows the user-defined facts to be assigned character strings pays off in the long run because readability is increased and rules are easier to debug. In the end, the symbol table is converted to integers as well, so performance does not vary. Notice how the process of building the lumber camp is in fact a sequence, much like what we would code in a state machine. In fact, user-defined facts make RSs engulf state machines in terms of expressive power. Everything we can do with a state machine can now be done with an RS with user facts. The opposite is not always true because RSs have a sense of priority that is hard to express with a state machine. Thus, user-defined facts provide a best-of-both worlds solution. Complex behaviors can be prioritized and layered using the RS, but each one might involve sequences of actions, much like a state machine would. Most RSs used in commercial game engines use this approach to increase the flexibility of the system at a very low coding and computational cost. Planning and Problem SolvingFSMs and rule sets are very useful paradigms to model simple behavior. If our problem can be expressed in terms of sequences and phases, FSMs are clearly the way to go. RSs, on the other hand, are better suited for priority lists or tasks that should be performed concurrently. Clearly, these tools are at the core of any action AI programmer's toolbox. However, both approaches are limited when it comes to modeling other, more complex behaviors. How can we teach a computer how to play chess? Chess is definitely not played in terms of steps, so FSMs won't help much. It definitely doesn't look like the kind of problem we can tackle with rules either. The nature of chess is predicting moves, analyzing the possible outcomes of a certain sequence of operations, and trying to outperform the analysis power of the opponent. Clearly, some problems are simply too hard for the kind of solutions we have proposed so far. Some phenomena require real-world analysis, reasoning, and thinking. Chess is a good example, but there are many others. As a quick sampler, consider the following list:
All these problems have some characteristics in common, which make them hard to model with our existing toolset. These problems require the following:
Clearly, we need to add some additional tools to our battle chest, tools that help us build plans, solve problems, and create tactics. These tools will not replace our FSMs or RSs but complement them. State-Space SearchIf I had to choose between FSMs and RSs, I would say chess is somehow similar to a state machine. It has board configurations that resemble the machine's states, and it has moves that resemble state transitions. But the structural complexity of chess is not easy to describe by means of FSMs. The key difference is that any state machine representing chess would have to be dynamic, not static. We would start from the current configuration of the board and propagate some moves into the future to choose the movement sequence that we think suits us best. A state machine, on the other hand, is completely built beforehand, so all states are designed before we even turn the AI on. Problems like solving a puzzle can also be expressed this way, using an initial state or configuration and a series of potential moves from which we will select the best one according to some strategies. The kind of problems based on exploring candidate transitions and analyzing their suitability for reaching our goals is globally called state-space search problems. We search the state-space to find ways to move from the initial conditions to our goals. State-space search is a very powerful paradigm that can be used to create strategies and plans. We propagate each possible move into the future and evaluate its consequences. This family of algorithms is well suited for everything from playing chess to finding the exit to a maze. It all boils down to representing the game as a tree with possible configurations as nodes in the tree and moves as branches between moves. Given an initial state and a target state, we can use a variety of methods to find the best route (and thus, move sequence) to go from one to the other. Figure 6.12 shows the classic state-space for the game of tic-tac-toe. Figure 6.12. State-space tree for tic-tac-toe (subset).
Many exploration algorithms exist for state-space problems. Some of them are blind search methods, meaning they use brute force to explore all possible moves. An example is depth-first search. We select candidates recursively using a single path until we reach an end state from which no further moves can be performed. Then, if the end state is not a goal, we start all over again using the next candidate. Blind search methods always work, but sometimes their cost can make them impractical. Take chess again, for example. Doing a depth-first search for such a game can take forever because the game does not necessarily have to end in a finite amount of time. So, other algorithms have been devised through the years. These algorithms use information about the problem to select not just any candidate, but one that looks like a promising option. These algorithms are said to be heuristic based, which means they use extra information that usually improves results. A good example is a problem-solving algorithm called A*. A* examines the current state and then explores future states, prioritizing those that look like better candidates. It is widely used for path finding. In this scenario, A* needs to have some extra information about the domain of the problem we are trying to solve. Then, it can find very good solutions without exploring all opportunities. In fact, for many problems, A* is an optimal algorithm, meaning it is capable of finding the optimal way to move between two locations. It's all a matter of using information about the problem we are solving. You can find a complete discussion of A* and other path finding algorithms in the next several chapters. We also need to be aware that some problems are just too big, even for heuristic-based approaches. Chess, again, is a good example. Put simply, there is no computer in the world (and there won't be at least for a few years) that can hold the complete chess movement state space. The number of board configurations is of astronomic proportions (just think about it: the board has 64 squares, there are 16 pieces, each one different. Get a calculator and do the math). Besides, most configurations can be connected in cycles. We can move a queen to a position, only to move it back to the original state. Thus, trying to explore the whole tree is just plain impossible. What most good programs do is analyze the tree with limited depth, trying to forecast the next N moves and select the best strategy for that movement sequence. By concatenating this sequentially, a good game should hopefully emerge. Biology-Inspired AIAll the core AI technologies we have explored so far are clearly rooted in computer science and mathematics concepts. The graphs, rules, or trees we have been using are not biological concepts but computational structures. Essentially, we have simulated human behavior, but we have used nonhuman tools. Thus, you could be inclined to generalize this and believe that all AI works the same way, that all simulations take place in the computer's mind-set. Although this is partly true, other techniques exist that are rooted not in computer science but in biology and neurology. We can try to simulate not only the intelligence that emerges from cognitive processes, but also the cognitive processes. The main issue with this biological approach is that today we are just beginning to scratch the surface of how the brain really works. Our cognitive processes are just being explored, and so far, their complexity has not yet been tamed. Thus, all biology-inspired models suffer from a certain sense of instability. But once these limitations are well understood, some of the methods are mature enough to offer promising results in specific areas. Genetic ProgrammingA very popular biology-inspired approach is genetic programming, inspired by genetic theory as developed by Mendel and evolution theory as developed by Charles Darwin (both in the nineteenth century). For those of you who are not familiar with these theories, I'll provide a short explanation in the next two paragraphs. The core idea behind genetic theory is that all living beings are defined by a molecular construct called genetic code (which was latter discovered to consist of DNA strings). DNA encodes the features of each individual. Different species (such as birds and mammals) have different DNA structures, and individuals from a single species share their DNA layouts. But individuals from the same species have minimal variations in some values in their DNA. These variations yield slightly different individuals, with differences in gender, external appearance, and so forth. Then, each generation can create a new generation whose DNA code will consist of a combination of the parent's respective DNA code, plus a minor degree of mutations. Based on genetic theory, Charles Darwin developed his theory of evolution. This theory essentially states that living beings in an ecosystem survive or expire depending on the suitability or fitness of their DNA to the said environment. The fittest survive, and the less well suited will simply disappear. Imagine a cold environment and a population of bears. Logically, those with better temperature insulation will live longer and will create a second generation that will, statistically, share their temperature protection scheme (be it thicker hair, stronger skin, and so on). Thus, nature is somehow biased toward better individuals. Every few generations, small mutations will appear, causing some of the DNA elements to change. Most bears will resemble their parents (using a normal distribution), but a small part of the Nth generation bears will have different eyes, longer legs, or even better temperature shielding. These bears, being better suited to their environment, will survive better, statistically breed more and fitter descendants, and so forth. If you extend this process, which is merely statistical, over several thousand generations, these micro changes will have paid off, and the species that will have survived the process will be very well adapted (within the obvious limits of biology) to the environment. Today, evolutionary theory is accepted and proven, despite some annoying questions as to how and why seahorses and other funny-looking animals ever came to be. The genetic and evolutionary theories work very well as a whole. The complete genetic theory deals with both the creation of a uniform population and the evolution of its individuals according to the rules of survival and improvement in the ecosystem. Interestingly, this process is well suited for numerical simulation. We can generate synthetic individuals and make them evolve using a computer simulation of these evolutionary principles. This way we can evolve virtual creatures and ecosystems in reasonable amounts of time, far from the millions of years it takes nature to select the fittest. Additionally, genetic programming can be used in game AI. Although FSMs and RSs are the workhorses of any AI programmer, these novel techniques are beginning to find their way into computer games in very specific applications. So let's now explore genetic algorithms in some detail to understand their potential applications. I will propose two examples. In the first example, we will use DNA codes to generate similar, yet varied, individuals. Then, we will explore how a Darwinian selection process can help us tune our game AI. Generating PopulationsThe first component we will study is the core genetic simulator, which will allow us to create individuals according to a virtual DNA. The DNA will be represented as an array of values; each one being one parameter of the species to model. So, if we are to genetically derive human pedestrians to act as part of the scenario in a game set in a city (think GTA3, Midtown Madness, but also The Sims, and so on), we could have a DNA string such as this:
The linear combination of these seven parameters can generate a variety of individuals; each with its own DNA. Given the number of parameters and the possible choices for each individual, we could have approximately 30,000 different specimens. It would then be the task of a sophisticated graphics animation engine to render the different variations. Here are two specimens from our DNA sequence:
Using genetic combinations, we can derive many descendants from this couple. Genetically speaking, about 200 possible descendants can be generated (not including mutations). Here's how:
Thus, the equation is the linear combination of all these variations: 2*2*2*1*3*3*3 = 216 The result is the number of possible descendants from that pair of source genetic codes. From this simple example, one of the main uses of genetic programming becomes evident. It is a great tool to create variations for groups, whether it's orcs, pedestrians, or lemmings. Genetic programming adds a degree of statistical variance that makes results more interesting. Moreover, genetic programming is not limited to living beings. How about using DNA codes for a cityscape, so each house is a variation of the standard genetic code of a core house? You could even have different neighborhoods with distinctive looks and qualities by creating a unique DNA structure and then modeling each neighborhood in terms of specific values for each gene. Then, you could create transitional zones between two neighborhoods by mating the DNA from each zone, weighted by the distance to the zone itself. Thus, we could seamlessly blend a Victorian downtown with a residential area. Once you get into the computer's realm, the possibilities are endless. Genetic programming can help us overcome uniform and boring games. Evolutionary ComputationNow it is time to implement Darwin's theory of natural selection. This is slightly trickier than simple genetic computation because we need to test individuals against their ecosystem and somehow measure their performance or fitness. This way the better suited will survive, and the remainder will simply perish (actually, they will become NULL pointers). By iterating this selection process, better-suited generations will statistically dominate in the long run. Here is the general layout of any Darwinian system:
Let's explore each step in detail. We will skip step 1 because it's the traditional genetic computation we have just explored. Fitness TestingThe fitness test determines which specimens are interesting (and thus deserve new generations) and which ones are simply not worth it. Thus, it is an essential component to ensure proper evolution and improvement. There are two ways of performing the test: automatic and supervised. In an automatic scenario, we define a function that can be computed automatically and will be applied to all individuals with no user interaction. An assisted system needs user supervision to select the cream of each crop. To better understand each system's potential and shortcomings, imagine that we are genetically deriving opponents for a Formula-1 racing game. We have defined their DNA as:
Obviously, we do not know beforehand which combination of the preceding parameters yields the best driver. Even more interesting, there might be different parameter combinations (and thus different driving styles) that yield top results. So, we build an evolutionary tester and run a number of generations to breed a good selection of drivers. As mentioned earlier, we need a significant number of generations to achieve interesting results. So, we run the system for 50 generations with 50 drivers being born in each one. In each run, we select the top 10 drivers as generators for the next iteration. Clearly, having to examine 2,500 drivers is a time-consuming task. Besides, as generations advance, the differences in driving will diminish as they converge to create stable, almost perfect driving styles. So, a human supervisor can have a hard time selecting the best specimens. In these situations, we can define an automatic fitness function, and thus perform the whole evolutionary loop as a batch process. For our driver selector, the fitness function can be a weighted sum of:
Now, assuming we run this as a batch process, and each driver gets a two-minute time slice to run a lap around the circuit and thus generate input for the fitness function, we will need about three days (using a single computer) to reach our final selection. Although significant, this time will ensure that we have top AI opponents using a vastly automatic process. The main programming task is defining the DNA we are going to use and determining the fitness function. A different strategy of performing the fitness test is to make specimens compete with one another in a tournament. We pair them randomly and test which one of them performs better. Then, the losing specimen is discarded, and the winning one advances to the next round. This can be a very useful technique to select specimens that are combat or competition oriented. For example, you can test Quake bots this way by making them fight each other in an empty level, and the one that achieves more frags in a given time is selected. But be careful with this approach. Imagine that two very good contestants are matched in the first round. Even if one of them wins in the end, this does not necessarily mean that the other one should be discarded. This kind of phenomena happens in many sports competitions (the Wimbledon tennis tournament and the Soccer World Cup are good examples). Sometimes, very good teams or players get coupled early on in the competition, which forces some quite good contestants to be discarded too early. However, in some instances, it will be hard to define a feasible, automatic fitness test. Sometimes the selection criteria will be nonnumeric, or quite simply, hard to put into numbers. Let's go back for a second to our crowd genetic simulator. Imagine you choose to iterate a crowd in an evolutionary way. Your goal is to create visually interesting combinations. You parameterize your virtual pedestrians using a variety of values and simply need to generate a few people that are visually attractive. One classic method is to let a supervisor select couples and then genetically derive descendants from them. This same method is used to procedurally generate textures in some packages based on the user's desired style. Then, it is hard, if not impossible, to automate what a person might find attractive or ugly. It is much better to create a system that can be evolved interactively, so the user can perform the Darwinian selection. The process can actually be done very quickly. We can select the best-looking pedestrian out of a population of 20 in one minute. This means we can derive 60 generations in an hour, which is more than enough. When coding this kind of supervised system, there are two guidelines that should be strictly observed:
These two conditions try to guarantee the rapid convergence of the evolution, so we can reach interesting results in a short time. Mating, Mutations, and PlateausOnce we have selected the best individuals, it is time to generate descendants as linear combinations of the parents' DNA strings. This process is really straightforward and, if the parents were among the cream of the crop, they will generate a better iteration. But it is very important to introduce some kind of mutation to the process. Assign a random gene value to a small portion of the newborn population to test that solution as well. The reason why we must act this way might not be trivial. Evolutionary computation is just a process of local optimization. Each generation is, on average, slightly better than the last one, and in the long run, this leads to perfect specimens. In fact, evolutionary computation is nothing but a special case of what's usually called a hill-climbing approach. Each step of the algorithm produces an improvement based on local characteristics, much like a hill climber. When climbing a hill, provided you always advance in the steepest direction, you should reach the top. But we all know a hill-climbing method only guarantees that we will reach a local maxima because we can reach a plateau from which we can no longer climb (and is not necessarily the top of the mountain). That's why mutations are essential. They guarantee that we can always generate a different individual who can by chance find a different way to evolve and reach better fitness values that the current generation cannot. |
|
|
Ajax Editor
JavaScript Editor


 Action
Action