 Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
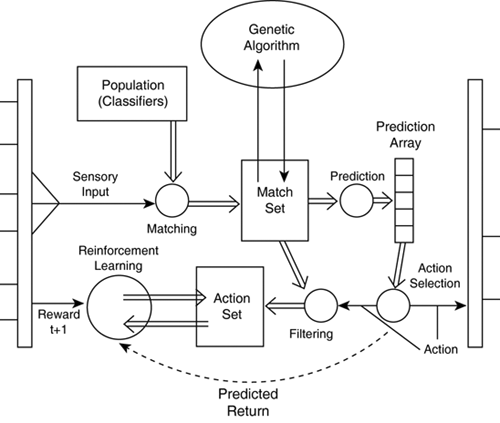
ArchitectureThe process follows the flow of data through the system, as depicted in Figure 33.1. The process starts by checking the sensory input and computing the matching classifiers. The matching classifiers are potentially evolved by the genetic algorithm. Then, the match set is processed to extract predictions for each of the actions. Given the predictions, it's possible to select the most appropriate action. The match set is then filtered to leave only the rules suggesting the selected action. The action is executed by the effectors. Figure 33.1. Flow chart of a classifier system, with functional components represented as circles, and data structures as rectangles.
Then, at the next step of the simulation, the reinforcement component adjusts the classifiers in the action set, given the reward and the predicted return. This outline gives us preliminary ideas of how the system works overall. The following sections cover the components separately. Matching Classifiers with the InputThe matching phase essentially analyzes the sensory input of the LCS (binary), comparing it with the conditions of the individual classifiers (ternary). Taking into account "don't care" symbols, all the applicable classifiers are stored in a match set, ready for further processing (see Table 33.1).
Creation of New ClassifiersEvolution aims to create new classifiers from the match set. This is performed in two cases: when there are insufficient matching rules (covering), and when there's a low probability (discovery). This phase is actually performed by a genetic algorithm. Genetic operators used are the random initialization, mutation, and crossover. CoveringCovering guarantees that there are always enough matching classifiers by generating new ones randomly if necessary. This introduces diversity into the population of classifiers, thus reducing the likelihood of premature convergence (in the population), or getting stuck in local traps (in the environment). The prediction and the error are left uninitialized with the counter at 0, as the reinforcement phase provides the first estimate. DiscoveryOne noticeable property of classifier systems is that they are not directly driven by the genetic algorithm. Instead, the genetic algorithm is considered the creative component that finds new behaviors, only applied with a low probability. The probability of selecting a classifier from the match set is proportional to its fitness (an elitist policy). Generally, two parents are chosen, two new classifiers are created, and they are inserted directly into the population. Again, the counter is set to 0 with the other values initialized in the reinforcement phase. There are separate probabilities for each genetic operator; there's a probability of m (Greek mu) that mutation will occur on a bit, and c (Greek chi) probability that one-point crossover is applied (see Chapter 32, "Genetic Algorithms"). Removal of ClassifiersBecause classifiers are added to the population at random intervals, it's necessary to remove the least fit to keep the population size under control. Deletion of classifiers also applies evolutionary pressure onto the population and increases the fitness of the system. There is a fixed upper limit on the size of the population. When there are too many classifiers, the worst are deleted stochastically. Generally, each classifier keeps an estimate of the size of the match sets it was involved in. The probability of a classifier being deleted is proportional to this estimated size and the classifier's fitness. In essence, frequently used classifiers are more likely to be removed when unfit. Using match-set size as a criterion for killing classifiers has the effect of balancing out the match sets. In genetic algorithms, such a technique is known as niching. A niched genetic algorithm essentially splits up the search space into different parts, and considers them as mostly separate. Genetic operators, including the deletion operators, are based on these niches. When done correctly, this has a consequence of balancing out the niches. Therefore, niching enforces diversity in the population of classifiers in an LCS. Individual classifiers apply to a certain part of input space. Ideally, we want to force the system to cover all the possible inputs (either explicitly or by generalization) so that it always suggests an action. Niching is necessary for the classifier system to acquire broad knowledge of the problem, and not just knowledge of the local areas of the search space where the fitness is high. PredictionIn the match set, the conditions of the classifiers are similar because they match the same inputs. The prediction phase separates the classifiers further by sorting them by identical actions. Each classifier has a different prediction of the return, so the prediction phase tries to estimate the total return for each action, taking into account potentially different predictions (see Table 33.2).
Generally for each action, the estimated return is a weighted average of the predictions of the classifiers. Wilson advocates using the fitness to perform the weighted average, so that the prediction of most accurate classifiers is given priority [Wilson94]. Action SelectionGiven the return predictions for each of the actions, it's possible to select the one that's most appropriate. Naturally, the action with the highest return is the most promising choice. However, it can also be beneficial to use randomized choices of actions to provide the system with more experience about the world. These two approaches are known as action selection policies:
Generally, a combination of the two policies is used to provide a trade-off between exploiting the best results, and exploring random actions.
ReinforcementThe reinforcement component is responsible for updating the values of the rules in the action set, only after the reward is received from the environment. Generally, the AI has to wait until the next step t+1 of the simulation to get the reward (that is, r(t+1)). Therefore, the implementation must keep the action set until then. Values that need to be updated include the prediction, the error of the prediction (accuracy), and the fitness. The principle used for updating these values is based on Widrow and Hoff's delta rule—as described in Chapter 17, "Perceptrons." The idea is to adjust the values toward a desired target, with a small step of b. We define the desired prediction P as the maximal value from the prediction array, multiplied by a discount factor g
In the case of the prediction of the return pj, we adjust that toward the desired value P using the delta rule, after the error has been updated:
The accuracy is defined as a function of the error, which increases the accuracy toward one as the error diminishes. The function exp(–ej) models this, and can be adjusted by scaling the error by alpha a. This is a simplification of the original function defined by Wilson [Wilson94], but works fine in practice. The fitness is defined as the relative accuracy of the classifier. The relative accuracy is computed as the difference of the accuracy and the average accuracy of the population. The fitness is estimated using an average for the first n updates and then using the delta rule (with h=1/b). | |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Ajax Editor
JavaScript Editor
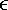 [0..1] (Greek gamma), summed with the reward feedback
[0..1] (Greek gamma), summed with the reward feedback