Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
The Search SpaceAssume we've chosen a representation, hopefully one enabling us to express the patterns in the solution. Beyond its suitability to map inputs to outputs, other properties of the representation affect the solution. Among these, the concept of search space and its smoothness are crucial issues for the AI (affecting its efficiency and reliability). One thing to keep in mind throughout this section is that the solution's internal representation may be entirely different from the problem's representation. In fact, it's often the case, because the interfaces to the components are often designed in a relatively generic fashion. Internal RepresentationThe representation can be understood as a paradigm used to express the solution, as a blueprint for the internal variables—and not the solution itself. The solution is a particular instance of all the possible representations, consisting in a set of specific values for each of the internal variables. The total number of configurations made up by these internal values is known as the search space; it's the set of all possible solutions—good or bad. Just like the domain of the problem, the domain of the solution is influenced by two things:
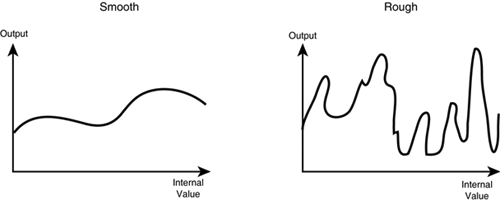
The domain of the representation affects the simulation (computing the answer) as well as training (finding a valid instance). Increases in the size of the search space tend to make both these tasks much tougher. ExamplesLet's take a few examples. For a perceptron, internal knowledge of the problem is stored in the weighted connections. Because the topology of perceptrons is generally frozen, the search space consists of the weights only. If there are 8 weights and 1 bias, the search space has a dimensionality of 9. The size of each dimension is theoretically the number of permutations of the 32 bits of a floating-point number (that is, 232 = 4,294,967,296). In the case of the perceptron, however, the values of the weights are limited to a small range around 0, and fine precision is rarely required. So in practice, the size of each dimension is in the thousands rather than billions. As for decision trees, let's consider the worst case: a complete tree. A tree with four Boolean attributes has three levels of branching, with the bottom nodes being leaves. The internal variables of the solution represent the decision used in each node. In the root, there are four possible attributes to choose from; in the next level, there are three choices, but two nodes; on the final level of branching, there are four nodes but only two possible attributes to choose from. The leaves have no decisions. So, the search space of a worst-case binary decision tree with n attributes would have a dimensionality of 20 * 21 * 22 * ... * 2n-2. Starting from the root, the size of these dimensions would be n, n – 1, n – 2, ... 2. Theoretically, that gives us a search space size of 576 for a full tree with 4 attributes—or worst case 6,480 if we allow the tree to be partial (1 extra option per decision). Search Space PropertiesBeyond just issues of size, the internal representation chosen is important for many reasons. Not only must the representation allow the problem to be modeled in a suitable fashion, it also must allow the AI technique to find the solution. The smoothness of the search space is a consequence of the representation. How do small adjustments to the internal values affect the mapping from inputs to outputs? In some cases, a small adjustment leads to a small change in the mapping; this is a smooth part of the search space. On the other hand, small changes may also lead to large jumps in the mapping; this is a very jagged part of the search space (see Figure 28.1). Figure 28.1. On the left, a smooth mapping that allows an easy adjustment of the internal values. On the right, a rough mapping that is hard to control and learn.
Significant changes in the mapping are particularly undesirable for two main reasons. If the search space is very rough, the control of human experts seems erratic when they make adjustments to the solution. This does not make their job of adjusting the solution very easy; whereas a with smooth search space, all the chances are on the experts' side. The same applies to AI techniques; in many cases, algorithms are used to find solutions to the problem. The mapping can be very unstable when the search space is jagged, which doesn't help the AI at all. Conversely, a smooth search space means that the adjustments in the solution are easy to control and understand by the AI. In practice, it's relatively easy to check how smooth the search space is. Starting with random configurations of the solution, the internal values are adjusted and the corresponding changes on the output are measured. The jump in the mapping very much depends on the interdependency between the internal variables. For example, adjusting a single weight in a multilayer perceptron can have a knock-on effect for all succeeding neurons, completely changing the entire mapping. On the other hand, changing a single rule of a rule-based system will only change a few isolated output conditions. The system designer has direct control over the properties of the search space. Chapter 21 discussed decisions at the problem level that affect the search space (for instance, selecting the right inputs and outputs). From the solutions point of view, engineers have control over the parameters of the representation (for instance, number of hidden neurons' maximum decision tree branching). The most appropriate technique can also be chosen without any prejudice. All these factors are in our control, and almost guarantee that a working solution can be developed with a smooth search space. |
|
|
Ajax Editor
JavaScript Editor