Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Training ProcedureWhen creating a DT, the data set itself will greatly influence the final result. This is not particularly desirable because we want the result to reflect the problem itself, not the data used. Data Set ManagementData set management is particularly important for creating DTs and preventing the algorithms from learning too specific models. Just like for multilayer perceptrons, this symptom is known as overfitting and can prevent DTs from generalizing to other data. Many improvements to DTs actually involve simple tricks to manipulate the data sets. The fundamental concepts remain the same as for perceptrons. We need to keep three different sets:
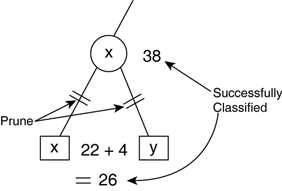
Dividing the entire data set can be done as equal parts: randomly picking a third of the samples. This somewhat depends on the total data available, because a minimal amount is needed for training. Validation works best with a much greater quantity of samples, and testing can optionally be skipped if there's a shortage of data! Pruning BranchesThe pruning of DTs is generally done as a postprocessing after learning. It's important to use a different data set for pruning, because using the training data set would not suggest any changes! Pruning uses the validation set. Intuitively, if the results of the classification are better when a branch is pruned, we prune it. To do this comparison, each node needs to know the response variable it would have if it were a leaf. Computing this class (or value) can be done in the same way as for the leaf; the class with the most instances (or the average value) is used. Then, we run a test of the entire data set. In each node, we count the number of successful classifications (or the total regression error). When finished, we can perform a simple check: Does any node have a better score than all its children put together? If this is the case, the children are in fact unnecessary, so we prune the tree at that node (see Figure 26.6). Figure 26.6. Pruning a branch by counting the number of successfully classified examples in each node.
Bagging and BoostingThe idea behind bagging and boosting is that poor classifiers can be combined to form better ones. We can use many different parameters and training sets to generate a collection of DTs. For example, bagging arbitrarily selects different samples from the training set, and boosting assigns them weights to influence the learning. Then, two different policies can be used to combine the different decisions:
The advantage of these techniques is that the quality of the final classifier is usually improved. However, the results are purely empirical. There's no guarantee that the combined classifiers will perform better on the entire problem, although there's proof for closed sets that the results will not be worse. The cost of combining classifiers scales linearly with the number of DTs used. Additional memory is needed to store the data structures in memory, and for each decision, there is a cost for traversing each of the trees. |
|
|
Ajax Editor
JavaScript Editor