Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
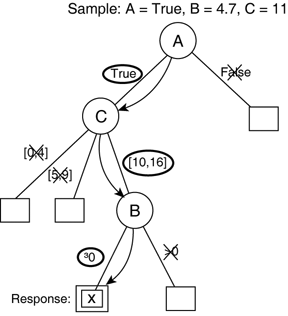
Classifying and RegressingGiven an existing DT, we can estimate the response variable for unknown data samples, based on the value of the attributes only. This is done sample per sample, allowing entire data sets to be filtered and evaluated. How is each data sample processed? Specifically how do we determine the class/value of a sample? This is done by a traversal of the tree, starting from the root toward the leaves. The traversal is based on the result of the conditional tests, guided by the predictor variables (see Figure 26.4). Figure 26.4. Using a data sample to guide the traversal of the DT.
At each level of the tree, a decision is made based on the value of the attributes. The conditional test in each node is used to evaluate predictor variables. One unique branch from the node will match the result of this evaluation. There is always one applicable branch because the conditions are complete (that is, minimum one option) and mutually exclusive (that is, one option only). The traversal will follow that branch to the next decision node where the process repeats. The traversal of the tree terminates when the end of the branching is reached (see Listing 26.1). Each leaf in the tree corresponds to a class (or value); the data sample that was used to traverse the tree must therefore belong to this class (or have this value). There is a guarantee that each sample will correspond to one and only one leaf—hence, one category or one estimate. Listing 26.1 Algorithm Used to Traverse a DT, Based on the Value of a Data Sample
node = root
repeat
result = node.evaluate( sample )
for each branch from node
if branch.match( result )
node = branch.child
end if
end for
until node is a leaf
return leaf class or value
This is an extremely simple process conceptually, which explains its efficiency. The biggest challenges lie in designing the software capable of simulating this in a flexible fashion. |
|
|
Ajax Editor
JavaScript Editor