Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
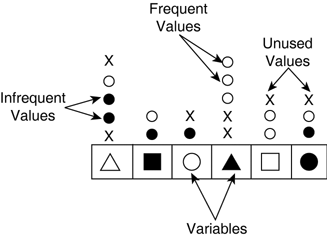
Underlying KnowledgeThe black box view is limited to rough knowledge: intuitions and theory. Obtaining a better understanding involves trying out the problem in practice. To do this, a solution—any solution—is required. It can be a simple prototype, a random solution, or even a human controlling the game character. Trying the problem in practice reveals usage of input and output values. It's possible to gather lots of example configurations (for instance, by logging network games among the development team), and analyze the data empirically. In this section, the understanding is mainly statistical, explaining different trends in the problem data. Usage AnalysisGiven the data gathered by random solutions to the problem, we can use different statistical techniques to provide a deeper insight into the problem. The simplest form of analysis identifies the frequency at which the values are used for each variable (see Figure 21.4, which shows the usage analysis of the problem in Figure 21.2). Figure 21.4. Statistics collected about the usage of the values for the problem from Figure 21.2.
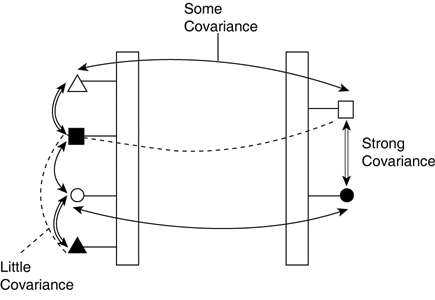
Given this knowledge about relevance of the values, we can determine the best representation, focusing on the important aspects and ignoring the less-relevant ones. In weapon selection, for example, a more precise representation can be used if there are large variations in the distance, or the discretization for the health parameter can be decreased if enemies have mostly full health. Variables and CovarianceIn practice, most of the values are used for each variable. However, not all the possible configurations are used for many problems. This happens particularly when input parameters are interdependent. In this case, there are commonly used input and output combinations. For example, the rules of the game or properties of the environment limit the number of situations (for instance, players mostly touch the floor, damage is linked with sounds of pain). The inputs are affected by external constraints (game logic and rules of the simulation), but the outputs are subject to internal constraints (requirements for realistic and intelligent behaviors). Formally speaking, this can be measured by the covariance between two parameters (see Figure 21.5). Intuitively, if one parameter can be fully determined from another, their covariance will be high (for instance, damage probability and likelihood of hitting the enemy). Conversely, if two parameters are unrelated to each other, their covariance will be near zero (for instance, the presence of a side obstacle and the amount of ammunition held by the enemy). Figure 21.5. The dependencies between the variables of the problem are denoted as arrows. Strong covariance makes the problem easier to solve.
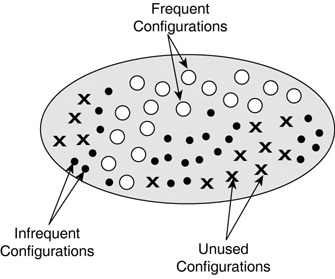
Note Conditional independence implies that two parameters vary freely of each other. Covariance can only measure dependencies between two variables, so a value of 0 is not sufficient to guarantee conditional independence. Indeed, there may be higher-order dependencies involving many parameters, which covariance does not identify. In practice, high covariance between two input parameters indicates redundant information. The lower the covariance, the more information is encoded in those inputs. As for the covariance between inputs and outputs, a high value indicates this is an extremely simple problem (for instance, obstacle avoidance). A covariance near zero implies the problem is not easy to solve (for instance, target selection by predicting damage). Finally, high covariance between the outputs is a good thing because it indicates that they are related. (Computing all the outputs is easier.) Effective DomainBoth the usage and the covariance statistics imply that different parts of the domain are used less often than others (see Figure 21.6). In fact, for most problems, the domain is rarely used entirely. We can therefore modify the representation to cover only the relevant part of the domain. This is a good way to optimize the problem. Figure 21.6. Statistics on the use of individual configurations in the problem. This emphasizes the relevant parts of the domain, as well as less-important ones.
However, optimizations need to be done with care. Removing or simplifying the variables from the problem reduces the flexibility of the interface, so the solutions are more limited. There also may be flaws in the statistical analysis, particularly when insufficient data has been gathered. So it's best to simplify the representation later after everything works, and optimizations can be validated by comparison and testing. Until then, knowledge of the effective domain is useful for developing a solution that is tailored to the problem, which reduces the complexity of the AI required to solve it. |
|
|
Ajax Editor
JavaScript Editor