Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
ApplicationNow it's possible to apply this perceptron to target selection. Our primary objective is to analyze the effectiveness of each rocket based on the situation. Then, theoretically, it should be possible to learn to predict the effectiveness of any shot before it happens. The AI code combines many of the techniques covered previously discussed. For navigation, a solution that provides good coverage of the terrain is essential. Tracking of enemy movement and estimating the velocity is also necessary. Then, the AI can launch a rocket around that target and see what happens. AlgorithmThe algorithm that selects the target is an iterative process. This is not done all at once; the decision can easily be split over multiple frames of the AI processing. Essentially, a generation mechanism creates new random points around the estimated position of the enemy. The animat checks for the first obstacle along that line (floor, wall), and uses that as the target. Then, the perceptron is called to evaluate the potential for damage at that point. Only when the damage is good enough is a target returned. Listing 20.1 shows this. The randvec() function returns a random offset, and the perceptron is called by the estimate_damage() function to assess the value of a target. Listing 20.1 The Iteration That Selects the Best Nearby Target by Predicting the Damage and Comparing the Probability to a Threshold Set by the Designer
function select_target
repeat
# pick a candidate target point near the enemy
target = position + randvec()
# use the perceptron to predict the hit probability
value = estimate_damage( target )
# stop if the probability is high enough
until value > threshold
return target
end function
This reveals how the neural network is put to use. However, some programming is required to teach it. Tracking RocketsKeeping track of the situation proves the most problematic. Most of the programming involves gathering and interpreting the information about the shot. The AI must be capable of answering the following questions:
To prevent any misinterpretations, each animat tries to have only one rocket in the air at any one time. It's then easier to attribute damage to that rocket. Embodiment actually helps this process, because all the rocket explosions that are invisible to an animat are unlikely to belong to it. There are four different stages for gathering this information. The major part of this problem is solved using events and callbacks (steps 2 and 3):
All four stages follow the life cycle of a rocket. After it has exploded, the AI has a unique data sample to train the perceptron. Dealing with NoiseDespite all these precautions, there is a lot of noise in the data. This means that two similar situations may have different outcomes. This is due to many things:
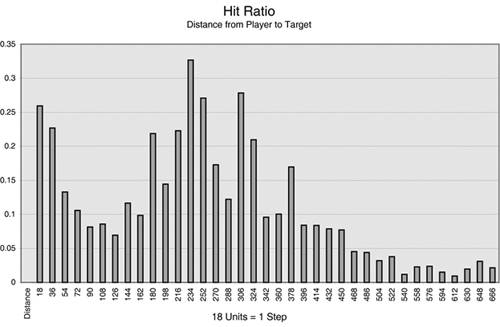
There are large variations in the training samples, making it very difficult to learn a good prediction of the outcome. The task is even tougher online, because the noise really takes its toll when learning incrementally. Instead, working with entire data sets really helps, so the noise averages out to suitable values. To gather the data, a number of animats (around five of them) store all their experience of different shots in logs. We can therefore acquire more information and process it manually to see whether the data indicates trends—thus confirming the design decisions. In Figure 20.2, for example, analyzing the hit ratio in terms of the distance between the player and the target reveals an interesting trend: Targets close to the estimate are likelier to cause more damage (this is accidental damage because the animats do not voluntarily shoot at close targets), but the damage is maximal at around 15 steps away (between distance 180 and 324). This curve reveals the strength of the prediction skills, which the perceptron for target selection will learn. (Manual design would no doubt ignore such factors.) Figure 20.2. The likelihood of a rocket damaging the enemy based on the distance from the player.
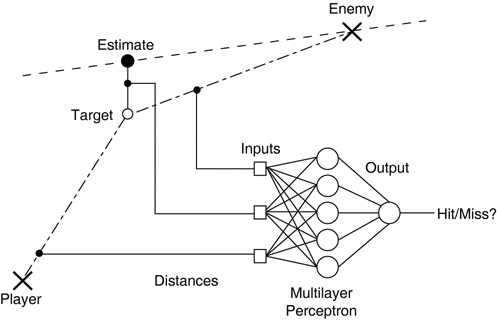
Inputs and OutputsThe inputs are chosen from among distances and dot products using combinations of the four points in space (that is, player origin, enemy position, estimated position, and chosen target):
Three primary distances between the four 3D points of the problem are the most useful as inputs (see Figure 20.3). There are trends in the dot products, too, but these are not as obvious. We could use further preprocessing to extract the relevant information out of the situation, but in a more generic fashion. For example, the dot product between the projectile and enemy velocities is 0 when the enemy is still; this situation would seem the same to the perceptron as a side-on shot. Returning a value of 1—similar to a full-on shot—would prove more consistent. Figure 20.3. Graphical representation of the inputs to the perceptron. The three primary features are the distances between the origin, enemy, and target.
The unique output corresponds to the damage inflicted. Because the damage is very often zero, and we want to emphasize any damage at all, we use a Boolean output that indicates injury. Training ProcedureDuring the training, the bots are not given unlimited rockets; they have to pick up the rocket launcher along with ammunition. In the test level, the rockets are easily available, and even the simplest-movement AI has no trouble picking them up accidentally. Animats without ammunition actually serve as good target practice for others with the rocket launchers (without causing chaos). To reduce the time taken by the simulation to gather the same data, the game can be accelerated. For example, this can be done by running the Quake 2 game in server mode and disabling the graphics. By default, these servers will only use necessary processing power to maintain the simulation real time. FEAR has an option to enable acceleration so the simulation runs at full speed, taking up as much processor time as possible. This is a great feature and saves a lot of development time.
|
|
|
Ajax Editor
JavaScript Editor