Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
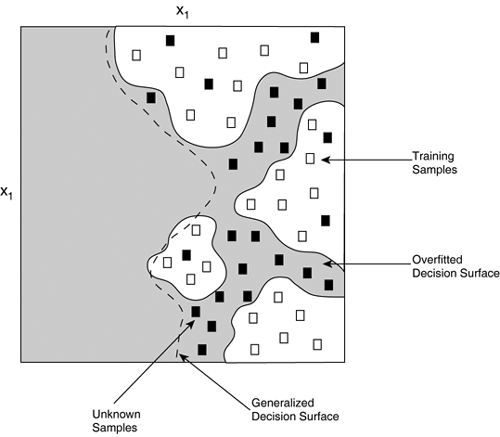
Practical IssuesThe theory covered so far has practical repercussions, as the additional hidden layers make perceptrons tricky to apply. It's essential to monitor the quality of the learning. GeneralizationThe learning phase is responsible for optimizing the weights for the examples provided. However, a secondary purpose of the training is to make sure that the multilayer performs well for other unseen examples (the objective function). This is known as generalization: the capability to learn a general policy from the examples. Generalization can be understood as finding a suitable decision surface. The problem is that if we learn the decision surface based on a particular set of examples, the result may not match the general decision surface. If we fit the examples too closely, the neural network may not perform well on other unseen examples. This predicament is known as overfitting—depicted in Figure 19.6. Figure 19.6. Example of overfitting where the learned decision surface fits the training samples too closely and generalizes poorly to other examples.
For single-layer perceptrons, generalization is not a problem because the decision surface is always linear! In MLPs, the number of hidden units affects the complexity of the decision surface, so this parameter plays an important role in the generalization capability. We need to find the trade-off between the number of hidden units and the apparent quality of results. Incorrect or incomplete data does not help generalization. If the learning doesn't produce the right result, the training examples are usually to blame (for instance, too few samples, examples not representative). One way to improve generalization is to gather all the data of the problem—or as close as possible to everything. Then, it's a matter finding a compromise between the number of hidden units and the quality of the results, which can be done by validation. Testing and ValidationThere is a method to deal with the data, to improve changes of successful generalization. It essentially involves splitting the training data into three different sets:
Essentially, the procedure to find the best model involves training many perceptrons, each with different parameters. Using the validation set, the best perceptron is identified. This is the final solution, and it can be optionally checked with the test. Incremental Versus BatchAs a general rule, batch training should be preferred whenever possible. Batch algorithms converge to the right result faster and with greater accuracy. Specifically, if RProp can't solve the problem, there's little hope for other methods. Even when a batch algorithm is not directly applicable, the problem should be changed to a batch prototype. The idea is to validate the design by using an algorithm with the highest chances of success. If necessary, incremental data can be gathered together for batch processing. Then, if the first test proves successful, incremental learning can be attempted. Incremental approaches are especially suited to online problems (learning within the game itself), because they require less memory. Indeed, the idea is to let the perceptron learn the examples as they are encountered, and discard them immediately. However, this runs the risk of "forgetting" early knowledge in favor of more recent examples. Dealing with Incremental LearningThere are general ways of dealing with adaptive behaviors. We'll discuss these in Chapter 48, "Dealing with Adaptive Behaviors." For perceptrons specifically, there is a common trick to acquire knowledge online—without forgetting it. One possible approach is to slow down the learning as time goes by. There's little risk of forgetting earlier experience when later training examples have a lesser importance. In practice, you do this by decreasing the learning rate over time. The adjustments made to the weights by steepest descent will thereby diminish over time. There's no formal approach to decreasing the learning rate over time, because it really depends on the problem itself. Generally, a linear or slow exponential decay over time often appears as successful strategies. Sadly, this also implies that the learning is effectively frozen as time passes. This is beneficial in some cases for preventing problems with incremental learning, but it can also cause problem where learning is actually necessary. As such, we need to pay special attention as to when to use this method. |
|
|
Ajax Editor
JavaScript Editor