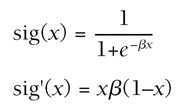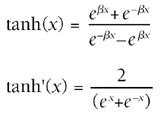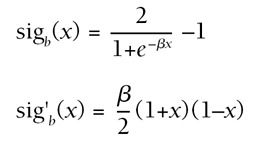Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Model OverviewMultilayer perceptrons are based on their older sibling with one single layer. There are two major differences between these models:
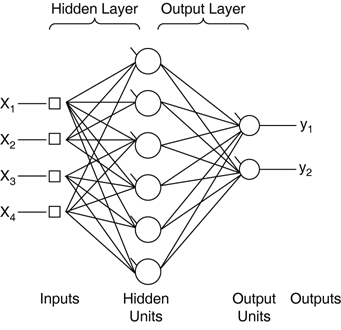
The next section looks at each of these differences separately. TopologyThe topology is the layout of the processing units inside a neural network, and how they are connected together. The topology of an MLP is said to be feed forward (as in Figure 19.1); there are no backward connections—also called recurrent connections. The information flows directly from the inputs to the outputs. The important structural improvement of MLP is the middle layer. Figure 19.1. Topology of an MLP, including inputs, middle layer, and output.
Middle LayersThere can be an arbitrary number of middle layers, although one is most common. These middle layers are sometimes referred to as hidden—because of the fact that these are not directly connected to the output. From the user's perspective, they could not be there! Another historical reason for calling them "hidden" is that they could not be directly trained according to the error. So once initialized (usually randomly), they were no longer touched. Because including more hidden layers increases the computational complexity of the network, why not have more? There are many factors to take into account (for instance, memory), but essentially one middle layer is almost always enough. One hidden layer enables us to get a universal approximator, capable in theory of modeling any continuous function (given a suitable activation function). So for most kinds of nonlinear problems (as in games), one hidden layer is enough. In some cases, however, there is much interdependency between the input variables, and the complexity of the problem is high. Here, an extra layer can help reduce the total number of weights needed for a suitable approximation. In practice, rarely more than two hidden layers are used in any topology. Perceptrons with two middle layers can approximate any function—even noncontinuous ones. Hidden UnitsChoosing the number of units in the hidden layer is also a decision linked with the topology. Unlike for the output layer, the number of hidden units is not bound to any explicit characteristic of the problem; it's the AI engineer's responsibility to decide about this magical number. This can have a great effect on the performance of the network generally, so it's quite an important decision. What's more, there is no analytical way (that is, a miracle formula) for determining the number of hidden units required, so no wonder this seems like a black art! Multilayer perceptrons require hidden units to represent their knowledge of the problem internally. These hidden units provide coverage of the input space, forming a decision surface. Each input pattern can be evaluated compared to this decision surface. For complex problems—with complex decision surfaces—the number of hidden units required can grow faster than exponentially! Certain properties of functions are just not suited to perceptrons (for instance, discontinuous functions, sharp and jagged variations), requiring too much memory and computation. As the number of dimensions grows (more inputs), the complexity of the desired decision surface increases, too. Again, this can require the number of hidden neurons to grow exponentially, a predicament known as the curse of dimensionality. It's one interpretation of why neural networks do not scale well, and why they have trouble coping with huge problems. It's a good idea to keep problems small for this reason. For example, aiming and target selection are handled separately in this part, but modeling them all together with prediction requires many neurons and layers. Much of the topology depends on the complexity of the decision surface. Therefore, we should expect to be confronted with these issues on a case-per-case basis. We'll take a practical approach to this problem in the next chapter. ConnectionsA final property of the topology resides in the connections between the units. In many cases, the units are all connected from one layer to another. However, this can be customized and individual connections can be removed arbitrarily. This is the difference between a fully connected network and a sparse one. Together with this, connections can be established that skip layers. For example, one connection could be established straight from the input to the output, ignoring the middle layer. These "exotic" configurations are extremely rare compared to fully connected MLPs. Although it is possible to create a simulator that can deal with arbitrary topologies, there is a large overhead in doing so. Indeed, the connections will have to be stored explicitly as pointers. The connections are implicit with fully connected perceptrons and only arrays of weights need storing. However, arbitrary topologies can have their uses given insider knowledge about the problem (that is, the engineer knows exactly what the topology should be, which rarely happens). Activation FunctionsThe activation function computes the output based on the net sum of each unit. Different types of functions are applicable. However, linear activation functions in the middle layers are no use at all! The MLP would have the same power as a plain perceptron, because combining two linear functions gives another linear one. For the hidden layers to have any effect on the computational capabilities of the MLP, a nonlinear activation function is necessary. PropertiesWe need to watch out for a few things when selecting an activation function. It needs to have the following properties:
We also may desire optional properties of the activation function for a particular implementation:
These last two options are linked to practical issues during the development. We'll look at them in more detail in the discussion, and during the application. Possible Activation FunctionsIn general, activation functions are selected from a commonly used set, as shown in Figure 19.2. Some of the choices we discussed for the standard perceptron are also used in MLP. These include step functions (allowing binary output) and linear activation functions (identity transformation). A combination of the two is known as threshold logic, where the linear output is clamped to a certain range. Figure 19.2. Graph of functions that are used as activation functions in the output layer.
These functions make suitable choices for the output layer, but not for the hidden layer (because not all the required properties are satisfied). Instead, so-called sigmoid functions are a popular choice. One of these is known as a logistic function.
b (Greek beta) is a value that controls the smoothness of the curve. For large values, the sigmoid can become close to a step function. This is useful because it has all the right properties as well! Another choice is the tanh function, but it is slightly more expensive computationally. This has the property of being negative and positive:
Instead of this, a bipolar sigmoid can be a more efficient alternative, giving the same features:
The choice of a bipolar or positive sigmoid is often dependent on the problem (negative output values), but the bipolar option should be preferred because it seems to provide better precision for training with floating-point values. |
|
|
Ajax Editor
JavaScript Editor