Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
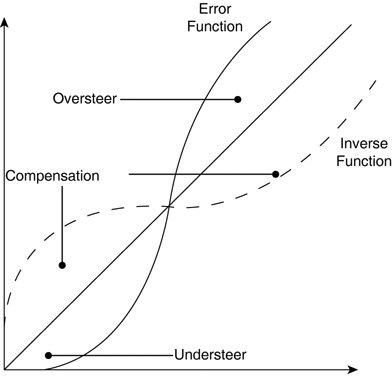
Dealing with ErrorsThe model of momentum and friction is an error that accumulates over sequences of turns. Additional errors for single angles can be included, too. The idea is to complicate this nonlinear problem to reveal how well a perceptron approximates the solution. These errors can be seen as a constraint to get the animat to perform realistically. The AI should take these errors into account so that the animats can still be effective at aiming—but realistic at the same time. Ignoring the variations in aiming would be error prone, causing the AI to under- and overshoot. Such errors are acceptable when the animats are playing against beginners. However, we want a top-quality AI that can deal with aiming errors so that expert human players feel challenged, too. Inverse ProblemTo compensate for errors, we could model the inverse of the error function (see Figure 18.3), so that the perfect corrected aiming angle is suggested. However, mathematical understanding of the problem is required and the inverse of a function does not always exist (like the one equation in Chapter 16, "Physics for Prediction"). Figure 18.3. An error function over an angle, and the inverse function that satisfies f(g(x)) = x.
Ideally, the AI needs a simple math-free way of approximating a function that will serve as the inverse of the aiming error. This approach would allow the animats to learn to perform better as they practice—without a model of the error. In the simulation, the AI can compare the desired angle (action) with the actual angle (observation). Given enough trial and error, it's possible to predict which corrected angles are required to obtain the desired angles. This approach gathers input/output pairs from the simulation, and learns the inverse relationship by flipping the pairs.
ImplementationThe AI uses sensors to regularly check the actual angles by which the body has turned since the last update. This allows the AI to compare what actually happened with what was requested in the previous update. However, the result must be flipped around; the AI needs to know what angle to specify based on the desired turn. Because the system now knows which angle to request to get the result that was observed, this preprocess provides a training sample for the perceptron. The neural network can be trained incrementally to learn these patterns. The information gathered does not help solve the same problem next time around. Consider, for instance, that we are trying to get the desired angle d1. If we try angle a1 as an action and observe an angle of d2, we still don't know how to get d1! All we know is how to get d2. Given enough samples, we'll eventually discover the angle that produces d1. For this problem, an online learning approach is used. The obvious benefit is for the animats to learn to improve their aiming during the game. This sounds more impressive than it is, but it's still fun to watch the animats improve their skills. One important thing to remember is that the perceptrons may have to deal with input and output values that are not within the unit vector. This is the case for angles in degrees, for example. For this reason, we'll use rescaling on both the input and output. On the output, it's absolutely necessary to rescale for the perceptron to learn—or the output unit couldn't produce all the possible results. Scaling is also applied to the input because it learns faster empirically. In theory, this is not necessary, but we can use suitable default parameters (for instance, a learning rate of 0.1) and get good results. |
|
|
Ajax Editor
JavaScript Editor