Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
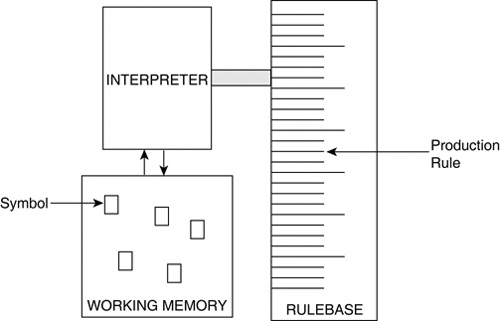
Overview of ComponentsThere is more to a rule-based system than a collection of "if...then" statements. Essentially, we need to know about three different components [Sharples96]: the working memory, the rulebase, and the interpreter (see Figure 11.2). Figure 11.2. The architecture of an RBS, composed of three interacting components.
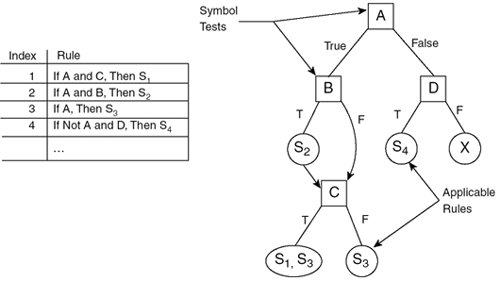
Working MemoryThe working memory is a collection of facts about the world (or the current problem), known as the internal representation. Generally, the working memory contains few symbols; human reasoning inspires RBSs, so short-term memory is relatively small. Here's an example of a working memory for the task of obstacle avoidance. There are two symbols present, implying they are true and all the others are false (for instance, there is no obstacle_right). Discarding symbols that aren't applicable is often easier and more efficient: [obstacle_left] [obstacle_front] Typically, RBSs are applied to problem solving, so there is a starting configuration and a particular desired result; these are both states of the working memory. In the case of control problems, however, we are just interested in the simulation itself, so there is no goal state per se; the symbols are updated repeatedly. The working memory defines the base of the system's architecture. This can be just an array of symbols, or something slightly more elaborate—such as a database. Extensions to the working memory are quite common, although the underlying concepts remain the same (that is, storage of facts). RulebaseThe second of three RBS components is the database of production rules stored by the system. Single RulesThe database contains a collection of rules, also sometimes called operators. They all have the following form: IF <condition> THEN <action> The first part of the rule is a collection of Boolean statements. It is also known as the head of the rule, or antecedent clause. The second part of the rule is a set of actions that manipulate symbols within the working memory. This part is also known as the body, or consequent clause. Both clauses are generally represented as combination of simple symbols (for instance, A and B, C or D). Data StructureA major aspect of the rulebase is the data structure chosen for internal storage. If a procedural approach is used, the production rules cannot be automatically reorganized for efficiency; this requires the programmer to edit the code and recompile. Instead, if the rules are stored separately from the system, in a declarative fashion, they must be loaded at runtime (that is, data driven). When implemented with a simple array of rules, a linear scan of the rulebase is needed to find conditions that are true. By organizing the rules further, the relationships between their conditions can be modeled with a tree-like data structure (see Figure 11.3). This splits the production rules into logical blocks, and proves more efficient when checking for applicable rules. Testing all the rules is done by a traversal of the tree. Each node corresponds to a single symbol test, and a match has been found once a leaf is reached. Figure 11.3. A linear data structure for storing rules, compared with a tree of hierarchical symbol tests.
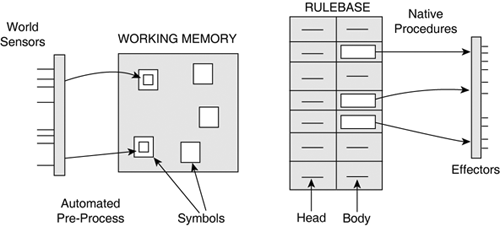
This tree is built in two phases; one identifies the common truth tests and organizes them into a tree, and the other merges common branches together. This procedure is extremely similar to building a decision tree, which Chapter 26, "Classification and Regression Trees," discusses in depth. In the meantime, see [Forgy82] for the details. This is a significant optimization of the time required to find matching rules. The computational power no longer scales linearly with the number of rules, which allows large systems to be treated efficiently. ExtensionsRBSs often interface with an external system. This can be a machine, a simulation of a problem, or—in our case—a synthetic body interacting with a virtual world. In many cases, it's necessary to communicate data with this system, for the RBS to work with up-to-date information and then act on the system. Standard declarative rules support sensors (inputs) and effectors (outputs) indirectly; sensors set corresponding symbols before they are used, and effectors test the working memory to see whether they should execute afterward. This approach is acceptable, although with the inconvenience of a pre- and postprocess. This problem has been the focus of practical research. The answer is to borrow the advantages of the procedural approach, only for sensors and effectors (allowing function calls in both clauses). This is a known extension to RBSs typically based on declarations. A compromise is also possible, and seems appropriate in our case; motor commands are procedural action, whereas symbols are automatically set according to the senses—as shown in Figure 11.4. This prevents the procedural sensors from being checked multiple times by the RBS, and allows the tree-based storage of the rules to work without modifications. Figure 11.4. The rule-based system interacts with the environment using a combination of declarative and procedural approaches.
Supporting partial matching of rules can simplify the rulebase; the entire condition does not need to be true for a rule to fire. Formally, this can be understood as a condition with an OR operator. Standard systems using only conjunctions (AND) can handle this by splitting up the disjunction and duplicating the rule's body: IF <condition1> OR <condition2> THEN <action> IF <condition1> THEN <action> IF <condition2> THEN <action> However, this approach is cumbersome because of the duplication of the rule's body. If partial matching is an important feature, the system should be extended to support it, either allowing OR operations or supporting references to actions (to prevent duplicating them). InterpreterThe interpreter is the part of the program that controls the RBS, interacting with the database of rules and the working memory. It decides which rules match the current state and how to execute them. This last component of RBS is also known as an inference engine, because it allows knowledge to be inferred from the declarations. For an RBS, there are two different kinds of inference mechanisms: forward and backward chaining. This describes how rules can be applied to the working memory to solve problems. Forward ChainingA forward-chaining system starts with a set of assertions, and repeatedly attempts to apply rules until the desired result is reached. This is known as a data-driven method, because facts and rules are combined to derive new facts. For example, given assertions about the situation, determine what weapon to use. A single cycle of the forward-chaining interpreter happens as follows. It is known as a recognize-act cycle:
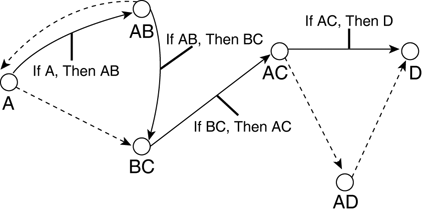
In a simulation (that is, a control problem), these rules are applied repeatedly as necessary, whereas for deductive problem solving a specific condition terminates the loop upon success—as shown in Figure 11.5. There are occasional problems with the interpreter getting stuck in infinite loops or in dead ends. We'll discuss solutions to these problems in the upcoming section, "Control Strategies." Figure 11.5. Result of a forward-chaining execution toward a goal. The discarded rules are drawn as dashed arrows.
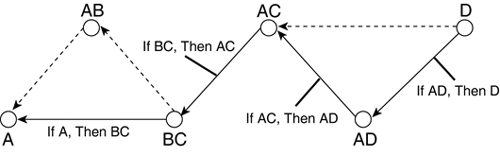
Forward-Chaining Extentions There are simple implementations for each of the three steps in the cycle, but it is possible to develop more elaborate strategies. These can provide more flexibility (for instance, partial matching), different forms of control (for instance, sensors and effectors), or just more efficiency as required (for instance, tree-based storage). This depends heavily on other parts of the system, so a good overall understanding of RBSs is required. Backward ChainingIn contrast, a backward-chaining system starts with the hypothesis and attempts to verify it by returning to the current state. This is known as goal-directed inference, because consequent clauses are matched to attempt to prove antecedent clauses recursively. For example, estimate the status of enemies based on their behavior. A cycle of this interpreter works in a similar fashion. It is known as a hypothesize-test cycle. The hypothesis about the solution is built step by step starting from the end—as shown in Figure 11.6: Figure 11.6. Result of a backward-chaining execution moving from the goal toward the start state. The discarded rules are drawn as dashed arrows.
Backward inference is more challenging to implement correctly, because the interpreter must keep track of the rules applied from the end to rebuild the solution from the start state. There are also more possibilities of finding dead ends (no applicable rules), and infinite loops are more likely too (same sequence of rules firing repeatedly). The solution to both these problem lies in the understanding of control strategies. Control StrategiesOne part of each cycle (forward and backward) requires a decision from the interpreter: conflict resolution. Different methods can be applied to select the rule; these are known as control strategies. The following ideas can be combined to produce custom selection processes:
When a decision is made as to which rule to pick, other alternatives are thereby not chosen. The control strategy affects what happens to the unchosen rules. The process of the interpreter was described in three steps as a "cycle." This cycle can be either iterative (that is, keep looping and ignore the alternatives) or recursive (that is, call another function for each of the options). With recursion, each alternative is kept in a stack, so it's possible to backtrack if something goes wrong. This allows all the options need to be searched exhaustively, guaranteeing the solution will be found if it exists. This process of going through all the options is known as a search, and can be done in many different ways. There is much to say about the search process itself, how it can be controlled and implemented, and even what can make it more efficient. However, such advanced control strategies are not commonly used in RBSs, and fall beyond the scope of reactive techniques.
Hybrid InterpretersBidirectional strategies have the option of supporting either type of inference separately. Combining forward and backward chaining prevents the interpreter from getting stuck, without using search mechanisms. Instead, both forward and backward rules can be chosen randomly until a solution is found! Backward chaining takes care of avoiding "dead ends" when moving forward, and vice versa. Search mechanisms are generally more robust and efficient at avoiding such traps, but bidirectional interpreters are appropriate for the simplest cases. |
|
|
Ajax Editor
JavaScript Editor