 Free JavaScript Editor
JavaScript Debugger
Free JavaScript Editor
JavaScript Debugger
8.2. XMLAs you're aware, if only from the cameo appearance in Chapter 2, "Introducing Ajax," XML stands for eXtensible Markup Language, but other than the purpose of padding resumés, you're probably not aware of why XML is used so much. Basically, there are three main reasons for the popularity of XML, not including the air of mystery surrounding anything with an X in it. (Don't believe me about the air of mystery? What about The X-Files and X-Men?) Literally tons has been written about XMLwell, at least when hard copy is taken into account. As for electronic editions, I can't say because my notebook seems to weigh the same, regardless of the free space available. For this reason, I won't bore you with the history of XML and how it is the best thing since sliced bread, or how it cures baldness, because it would be either redundant or an outright lie. Anyone who has ever developed an application that uses XML knows that there is a good chance of pulling out one's own hair when attempting to explain XML to fellow developers who still haven't grasped the software equivalent of the concept of fire. However, I should at least hit the highlights and point out some of the more useful and obscure topics. 8.2.1. Well FormedAlright, the concept that XML has to be well formed is not obscure, but it does fall well into the useful bucket. You'd be surprised at the number of times that I've had to explain the concept of "well formed" to a particular project leader with mainframe roots. Or, come to think of it, maybe you wouldn't. Let's just say that, like the Creature from the Black Lagoon, the XML challenged walk among us, and you don't even need to travel to the now-closed Marineland in Florida to find them. For this reason, it is time for XML 101. An XML document is well formed when the follow conditions have been met:
That was relatively easy, wasn't it? I recommend quoting it verbatim whenever it is necessary to explain the concept to a clueless project leader. But you need to remember to make your eyes big when saying "Beware of entities!" because they like that. Alright, now that you're (hopefully) open to XML, the big question is, where does it come from? Well, that depends on both your web server and database environments; some have built-in methods for producing XML directly from the result of SQL SELECT statements or stored procedures. If your environment doesn't support that, there is always the possibility of "rolling" your own XML. Because XML is human readableessentially, textwith a little work, it is possible to create XML, even where XML isn't supported. Take, for example, MySQL. Although both Oracle and SQL Server can produce XML directly from a stored procedure, a little more effort is required to produce XML from MySQL. First, a stored function is required to build the individual nodes by concatenating the node name and value, as in Listing 8-1. Next, a function is needed that uses a cursor to step through the results of a query and build the XML using the aforementioned stored function. Listing 8-2 contains a sample stored procedure to do just that. Listing 8-1. Concatenating a Stored Function
Listing 8-2. XML Producing a Stored Procedure
Here's how it works: The stored procedure shown in listing 8-2 retrieves the result of a query, builds an XML string containing the opening root element, and then performs the following steps for each row retrieved:
After all the rows have been processed, the closing root element is appended to the XML string and the process is complete. Now that we have a reliable source of XML, let's examine how we can use it in a web browser. 8.2.2. Data Islands for Internet ExplorerThe official party line about XML Data Islands is that they are a "Microsoft-only" technology and, therefore, will not work with any other browser. Yeah, right. However, before altering the fabric of reality as only a mad scientist can, let's take a closer look at what XML data islands are and how they work. As foreboding as the term XML Data Island is, according to the official definition, it is nothing more than XML embedded somewhere in an HTML document. Not too badsounds about as scary as a bowl of goldfish. In fact, Listing 8-3 is a basic HTML page with XML embedded smack in the middle of it, with Figure 8-3 showing what it looks like in Microsoft Internet Explorer. Figure 8-3. HTML with embedded XML in Internet Explorer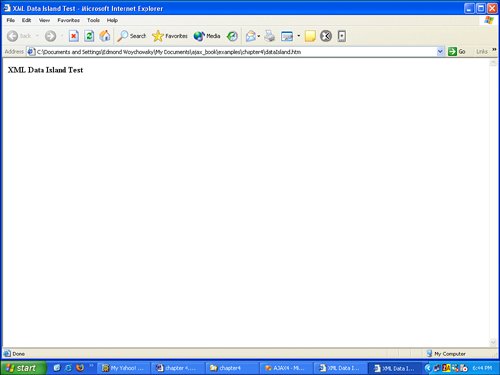
Listing 8-3. HTML with Embedded XML
Piece of cake, isn't it? Right up to the point that somebody opens it in Firefox, as Figure 8-4 illustrates. Figure 8-4. HTML with embedded XML in Firefox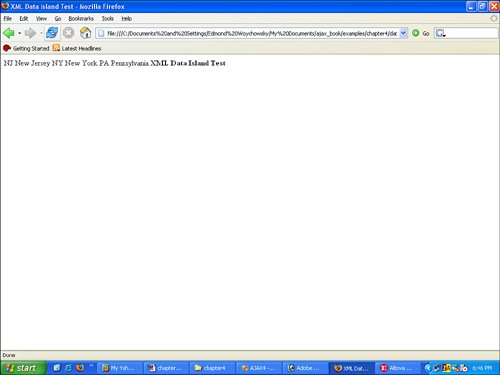
8.2.3. Data Islands for All!Right about now, if you're anything like me, you're leaning a little bit toward despair. And why not? A bunch of ugly stuff is embedded in the middle of the web page, but remember, just because something is there does not mean it has to be visible. Multiple methods exist for hiding information on a web page, such as sticking it in the value of a hidden input box or Cascading Style Sheets (CSS), or using white-out. Hmm, thinking about it, I'd ignore the first option because, although it will work, it will also be extremely cumbersome. I'd also ignore the third option as being either too permanent or just plain stupid. This leaves only the second option, Cascading Style Sheets. The great part about using CSS is that not only is it an elegant solution, but it is also cross-browser friendly. So let's make a minor modification to the previous web pagenamely, adding the style sheet shown in Listing 8-4, and take another look at the page (see Figure 8-5). Figure 8-5. HTML with embedded XML with CSS in Firefox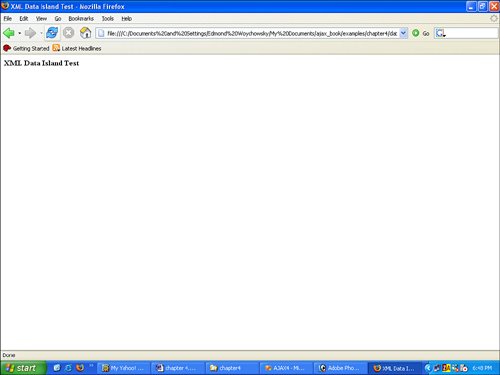
Listing 8-4. CSS to Hide XML
Okay, now that we have both the XML Data Island and a workable cloaking device for said XML Data Island, we still need a way to use it. Because with the exception of a "Doomsday Device," something that isn't being used is essentially useless, and I'm pretty sure that demanding "One million dollars in uncut flawless diamonds or I use my XML Data Island" wouldn't get much of a responseunless, of course, you count the nice people with the butterfly nets and jackets with wrap-around sleeves as a response. The big question is, now that we have it, how do we use it? This is a good although somewhat broad question that, unfortunately, ignores some of the technical issues yet to be addressed. Perhaps it would be better to break the single question into two separate questionsfor instance, "Now that we have an XML data island, how do we find it on the page?" and "How can it be incorporated into the page?" The first one is easy. Remember the transverse function from Chapter 5, "Ajax Using HTML and JavaScript"? It was the one that essentially walked through the HTML DOM. Something similar would work. I, however, prefer the more direct route and would use either the getElementById method or the getElementsByName method. The getElementById method, which we've used in earlier examples, has the advantage of returning a single object. However, if for some unforeseen reason the object doesn't exist, an error will be thrown. On the other hand, the getElementsByName method returns an array consisting of those nodes with a particular name. This requires a little more typing than the other method. The syntax for both of these methods is shown here:
document.getElementById('xmldi')
document.getElementsByTagName('xml')
The next question is, "How can it be incorporated into the page?" As with the previous question, there are several different means to an end. For instance, if you're interested in only replacing existing XHTML objects with new XHTML objects, you can use getElementById, as the page in Listing 8-5 shows. Listing 8-5. Using getElementById
As neat and nifty as this is, essentially, it is only a variation on the DHTML methods that have been used for the last several years. To turn heads, what is needed is a way to update the page's content dynamically. Fortunately, a number of approaches can be taken to accomplish this task, which we cover later. The only question is how much of a tolerance you have for "mad scientist stuff." 8.2.4. BindingTo those of you with impure thoughts about this heading, I'd like to say, "Shame on you!" It simply refers to the act of binding XML to a web page's HTML. Get your minds out of the gutter. If you've never used this technique, there are a number of reasons to consider using it. First, when you get the syntax down, it is relatively easy to understand. Another reason is that, for all of its power, it is quite compact, yet it separates content from presentation. Finally, it sounds really kinky, and how often do we get to use something that sounds kinky? Binding XML to HTML is usually considered a Microsoft Internet Exploreronly kind of thing. In Internet Explorer, each bound HTML element identifies both the XML data island's ID and the individual node that is being bound, as shown in Listing 8-6. Listing 8-6. XML Binding in Internet Explorer
Each HTML tag to be bound, the input tags in the example above, has both a datasrc to identify the XML Data Island and a datafld that identifies the specific node. It is important to realize that changes made to the contents of the text box are reflected in the XML Data Island itself. So type plover over xyzzy, and the text in the magic node is plover. This is a fine, although somewhat flakey, solution if the visitor is using Microsoft Internet Explorer, but what if they're using Firefox? The simple answer is to fake it. Using client-side JavaScript, a number of functions add the same functionality to Firefox, right down to using the same tags. The interesting thing about most of these tools is that they're usually more stable than Internet Explorer's own built-in binding. In an effort to work around IE's flakey-ness, I wrote the page shown in Listing 8-7. In addition, I renamed the datasrc attribute xmldi and the datafld attribute xmlnode to avoid having Internet Explorer use its own binding. Listing 8-7. Cross-Browser XML Binding
The bind() function retrieves all the div, input, select, span, and textarea elements using the DOM. Next, the ID of the data island and the elements' names are retrieved from HTML using the xmldi and xmlnode attributes. The XML node values are then copied to the HTML. Finally, an event handler is set for each HTML element affected. The purpose of this event handler is to update the XML when the visitor modifies the HTML value, for instance, by changing the value in an input box. |
Free JavaScript Editor
JavaScript Debugger